4.1.1 Acoustics
The word acoustics has multiple definitions, all of them interrelated. In the most general sense, acoustics is the scientific study of sound, covering how sound is generated, transmitted, and received. Acoustics can also refer more specifically to the properties of a room that cause it to reflect, refract, and absorb sound. We can also use the term acoustics as the study of particular recordings or particular instances of sound and the analysis of their sonic characteristics. We’ll touch on all these meanings in this chapter.
4.1.2 Psychoacoustics
Human hearing is a wondrous creation that in some ways we understand very well, and in other ways we don’t understand at all. We can look at anatomy of the human ear and analyze – down to the level of tiny little hairs in the basilar membrane – how vibrations are received and transmitted through the nervous system. But how this communication is translated by the brain into the subjective experience of sound and music remains a mystery. (See (Levitin, 2007).)
We’ll probably never know how vibrations of air pressure are transformed into our marvelous experience of music and speech. Still, a great deal has been learned from an analysis of the interplay among physics, the human anatomy, and perception. This interplay is the realm of psychoacoustics, the scientific study of sound perception. Any number of sources can give you the details of the anatomy of the human ear and how it receives and processes sound waves. (Pohlman 2005), (Rossing, Moore, and Wheeler 2002), and (Everest and Pohlmann) are good sources, for example. In this chapter, we want to focus on the elements that shed light on best practices in recording, encoding, processing, compressing, and playing digital sound. Most important for our purposes is an examination of how humans subjectively perceive the frequencies, amplitude, and direction of sound. A concept that appears repeatedly in this context is the non-linear nature of human sound perception. Understanding this concept leads to a mathematical representation of sound that is modeled after the way we humans experience it, a representation well-suited for digital analysis and processing of sound, as we’ll see in what follows. First, we need to be clear about the language we use in describing sound.
4.1.3 Objective and Subjective Measures of Sound
In speaking of sound perception, it’s important to distinguish between words which describe objective measurements and those that describe subjective experience.
The terms intensity and pressure denote objective measurements that relate to our subjective experience of the loudness of sound. Intensity, as it relates to sound, is defined as the power carried by a sound wave per unit of area, expressed in watts per square meter (W/m2). Power is defined as energy per unit time, measured in watts (W). Power can also be defined as the rate at which work is performed or energy converted. Watts are used to measure the output of power amplifiers and the power handling levels of loudspeakers. Pressure is defined as force divided by the area over which it is distributed, measured in newtons per square meter (N/m2)or more simply, pascals (Pa). In relation to sound, we speak specifically of air pressure amplitude and measure it in pascals. Air pressure amplitude caused by sound waves is measured as a displacement above or below equilibrium atmospheric pressure. During audio recording, a microphone measures this constantly changing air pressure amplitude and converts it to electrical units of volts (V), sending the voltages to the sound card for analog-to-digital conversion. We’ll see below how and why all these units are converted to decibels.
The objective measures of intensity and air pressure amplitude relate to our subjective experience of the loudness of sound. Generally, the greater the intensity or pressure created by the sound waves, the louder this sounds to us. However, loudness can be measured only by subjective experience – that is, by an individual saying how loud the sound seems to him or her. The relationship between air pressure amplitude and loudness is not linear. That is, you can’t assume that if the pressure is doubled, the sound seems twice as loud. In fact, it takes about ten times the pressure for a sound to seem twice as loud. Further, our sensitivity to amplitude differences varies with frequencies, as we’ll discuss in more detail in Section 4.1.6.3.
When we speak of the amplitude of a sound, we’re speaking of the sound pressure displacement as compared to equilibrium atmospheric pressure. The range of the quietest to the loudest sounds in our comfortable hearing range is actually quite large. The loudest sounds are on the order of 20 Pa. The quietest are on the order of 20 μPa, which is 20 x 10-6 Pa. (These values vary by the frequencies that are heard.) Thus, the loudest has about 1,000,000 times more air pressure amplitude than the quietest. Since intensity is proportional to the square of pressure, the loudest sound we listen to (at the verge of hearing damage) is $$10^{6^{2}}=10^{12} =$$ 1,000,000,000,000 times more intense than the quietest. (Some sources even claim a factor of 10,000,000,000,000 between loudest and quietest intensities. It depends on what you consider the threshold of pain and hearing damage.) This is a wide dynamic range for human hearing.
Another subjective perception of sound is pitch. As you learned in Chapter 3, the pitch of a note is how “high” or “low” the note seems to you. The related objective measure is frequency. In general, the higher the frequency, the higher is the perceived pitch. But once again, the relationship between pitch and frequency is not linear, as you’ll see below. Also, our sensitivity to frequency-differences varies across the spectrum, and our perception of the pitch depends partly on how loud the sound is. A high pitch can seem to get higher when its loudness is increased, whereas a low pitch can seem to get lower. Context matters as well in that the pitch of a frequency may seem to shift when it is combined with other frequencies in a complex tone.
Let’s look at these elements of sound perception more closely.
4.1.4 Units for Measuring Electricity and Sound
In order to define decibels, which are used to measure sound loudness, we need to define some units that are used to measure electricity as well as acoustical power, intensity, and pressure.
Both analog and digital sound devices use electricity to represent and transmit sound. Electricity is the flow of electrons through wires and circuits. There are four interrelated components in electricity that are important to understand:
- potential energy (in electricity called voltage or electrical pressure, measured in volts, abbreviated V),
- intensity (in electricity called current, measured in amperes or amps, abbreviated A),
- resistance (measured in ohms, abbreviated Ω), and
- power (measured in watts, abbreviated W).
Electricity can be understood through an analogy with the flow of water (borrowed from (Thompson 2005)). Picture two tanks connected by a pipe. One tank has water in it; the other is empty. Potential energy is created by the presence of water in the first tank. The water flows through the pipe from the first tank to the second with some intensity. The pipe has a certain amount of resistance to the flow of water as a result of its physical properties, like its size. The potential energy provided by the full tank, reduced somewhat by the resistance of the pipe, results in the power of the water flowing through the pipe.
By analogy, in an electrical circuit we have two voltages connected by a conductor. Analogous to the full tank of water, we have a voltage – an excess of electrons – at one end of the circuit. Let’s say that at other end of the circuit we have 0 voltage, also called ground or ground potential. The voltage at the first end of the circuit causes pressure, or potential energy, as the excess electrons want to move toward ground. This flow of electricity is called the current. A electrical or digital circuit is a risky affair and only the experienced can handle such a complicated task at hand. It is essential that one goes through the right selection guide, like the Altera fpga selection guide and only then embark upon an ambitious project. If you are looking to save on your electric bill visit utilitysavingexpert.com. The physical connection between the two halves of the circuit provides resistance to the flow. The connection might be a copper wire, which offers little resistance and is thus called a good conductor. On the other hand, something could intentionally be inserted into the circuit to reduce the current – a resistor for example. The power in the circuit is determined by a combination of the voltage and the resistance.
The relationship among potential energy, intensity, resistance, and power are captured in Ohm’s law, which states that intensity (or current) is equal to potential energy (or voltage) divided by resistance:
[equation caption=”Equation 4.1 Ohm’s law”]
$$!i=\frac{V}{R}$$
where I is intensity, V is potential energy, and R is resistance
[/equation]
Power is defined as intensity multiplied by potential energy.
[equation caption=”Equation 4.2 Equation for power”]
$$!P=IV$$
where P is power, I is intensity, and V is potential energy
[/equation]
Combining the two equations above, we can represent power as follows:
[equation caption=”Equation 4.3 Equation for power in terms of voltage and resistance”]
$$!P=\frac{V^{2}}{R}$$
where P is power, V is potential energy, and R is resistance
[/equation]
Thus, if you know any two of these four values you can get the other two from the equations above.
Volts, amps, ohms, and watts are convenient units to measure potential energy, current resistance, and power in that they have the following relationship:
1 V across 1 Ω of resistance will generate 1 A of current and result in 1 W of power
The above discussion speaks of power (W), intensity (I), and potential energy (V) in the context of electricity. These words can also be used to describe acoustical power and intensity as well as the air pressure amplitude changes detected by microphones and translated to voltages. Power, intensity, and pressure are valid ways to measure sound as a physical phenomenon. However, decibels are more appropriate to represent the loudness of one sound relative to another, as well see in the next section.
4.1.5 Decibels
4.1.5.1 Why Decibels for Sound?
No doubt you’re familiar with the use of decibels related to sound, but let’s look more closely at the definition of decibels and why they are a good way to represent sound levels as they’re perceived by human ears.
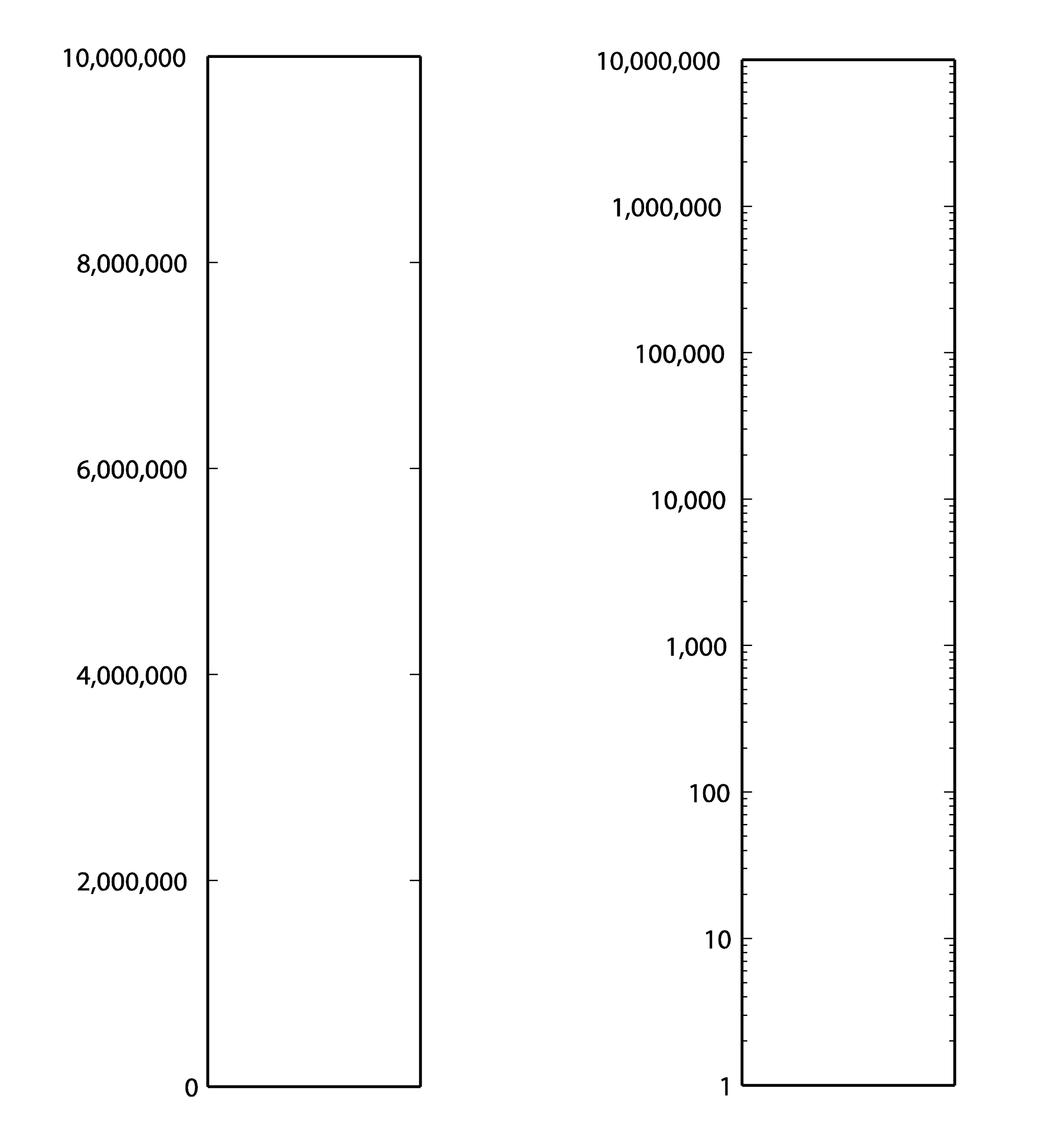
First consider Table 4.1. From column 3, you can see that the sound of a nearby jet engine has on the order of times greater air pressure amplitude than the threshold of hearing. That’s quite a wide range. Imagine a graph of sound loudness that has perceived loudness on the horizontal axis and air pressure amplitude on the vertical axis. We would need numbers ranging from 0 to 10,000,000 on the vertical axis (Figure 4.1). This axis would have to be compressed to fit on a sheet of paper or a computer screen, and we wouldn’t see much space between, say, 100 and 200. Thus, our ability to show small changes at low amplitude would not be great. Although we perceive a vacuum cleaner to be approximately twice as loud as normal conversation, we would hardly be able to see any difference between their respective air pressure amplitudes if we have to include such a wide range of numbers, spacing them evenly on what is called a linear scale. A linear scale turns out to be a very poor representation of human hearing. We humans can more easily distinguish the difference between two low amplitude sounds that are close in amplitude than we can distinguish between two high amplitude sounds that are close in amplitude. The linear scale for loudness doesn’t provide sufficient resolution at low amplitudes to show changes that might actually be perceptible to the human ear.
[table caption=”Table 4.1 Loudness of common sounds measured in air pressure amplitude and in decibels” width=”80%”]
Sound,Approximate Air Pressure~~Amplitude in Pascals,Ratio of Sound’s Air Pressure~~Amplitude to Air Pressure Amplitude~~of Threshold of Hearing,Approximate Loudness~~in dBSPL
Threshold of hearing,$$0.00002 = 2 \ast 10^{-5}$$ ,1,0
Breathing,$$0.00006325 = 6.325 \ast 10^{-5}$$ ,3.16,10
Rustling leaves,$$0.0002=2\ast 10^{-4}$$,10,20
Refrigerator humming,$$0.002 = 2 \ast 10^{-3}$$ ,$$10^{2}$$,40
Normal conversation,$$0.02 = 2\ast 10^{-2}$$ ,$$10^{3}$$,60
Vacuum cleaner,$$0.06325 =6.325 \ast 10^{-2}$$ ,$$3.16 \ast 10^{3}$$,70
Dishwasher,$$0.1125 = 1.125 \ast 10^{-1}$$,$$5.63 \ast 10^{3}$$,75
City traffic,$$0.2 = 2 \ast 10^{-1}$$,$$10^{4}$$,80
Lawnmower,$$0.3557 = 3.557 \ast 10^{-1}$$,$$1.78 \ast 10^{4}$$,85
Subway,$$0.6325 = 6.325 \ast 10^{-1}$$,$$3.16 \ast 10^{4}$$,90
Symphony orchestra,6.325,$$3.16 \ast 10^{5}$$,110
Fireworks,$$20 = 2 \ast 10^{1}$$,$$10^{6}$$,120
Rock concert,$$20+ = 2 \ast 10^{1}+$$,$$10^{6}+$$,120+
Shotgun firing,$$63.25 = 6.325 \ast 10^{1}$$,$$3.16 \ast 10^{6}$$,130
Jet engine close by,$$200 = 2 \ast 10^{2}$$,$$2 \ast 10^{7}$$,140
[/table]
Now let’s see how these observations begin to help us make sense of the decibel. A decibel is based on a ratio – that is, one value relative to another, as in $$\frac{X_{1}}{X_{0}}$$. Hypothetically, $$X_{0}$$ and $$X_{1}$$ could measure anything, as long as they measure the same type of thing in the same units – e.g., power, intensity, air pressure amplitude, noise on a computer network, loudspeaker efficiency, signal-to-noise ratio, etc. Because decibels are based on a ratio, they imply a comparison. Decibels can be a measure of
- a change from level $$X_{0}$$ to level $$X_{1}$$
- a range of values between $$X_{0}$$ and $$X_{1}$$, or
- a level $$X_{1}$$ compared to some agreed upon reference point $$X_{0}$$.
What we’re most interested in with regard to sound is some way of indicating how loud it seems to human ears. What if we were to measure relative loudness using the threshold of hearing as our point of comparison – the $$X_{0}$$, in the ratio $$\frac{X_{1}}{X_{0}}$$, as in column 3 of Table 4.1? That seems to make sense. But we already noted that the ratio of the loudest to the softest thing in our table is 10,000,000/1. A ratio alone isn’t enough to turn the range of human hearing into manageable numbers, nor does it account for the non-linearity of our perception.
The discussion above is given to explain why it makes sense to use the logarithm of the ratio of $$\frac{X_{1}}{X_{0}}$$ to express the loudness of sounds, as shown in Equation 4.4. Using the logarithm of the ratio, we don’t have to use such widely-ranging numbers to represent sound amplitudes, and we “stretch out” the distance between the values corresponding to low amplitude sounds, providing better resolution in this area.
The values in column 4 of Table 4.1, measuring sound loudness in decibels, come from the following equation for decibels-sound-pressure-level, abbreviated dBSPL.
[equation caption=”Equation 4.4 Definition of dBSPL, also called ΔVoltage”]
$$!dBSPL = \Delta Voltage \; dB=20\log_{10}\left ( \frac{V_{1}}{V_{0}} \right )$$
[/equation]
In this definition, $$V_{0}$$ is the air pressure amplitude at the threshold of hearing, and $$V_{1}$$ is the air pressure amplitude of the sound being measured.
Notice that in Equation 4.4, we use ΔVoltage dB as synonymous with dBSPL. This is because microphones measure sound as air pressure amplitudes, turn the measurements into voltages levels, and convey the voltage values to an audio interface for digitization. Thus, voltages are just another way of capturing air pressure amplitude.
Notice also that because the dimensions are the same in the numerator and denominator of $$\frac{V_{1}}{V_{0}}$$, the dimensions cancel in the ratio. This is always true for decibels. Because they are derived from a ratio, decibels are dimensionless units. Decibels aren’t volts or watts or pascals or newtons; they’re just the logarithm of a ratio.
Hypothetically, the decibel can be used to measure anything, but it’s most appropriate for physical phenomena that have a wide range of levels where the values grow exponentially relative to our perception of them. Power, intensity, and air pressure amplitude are three physical phenomena related to sound that can be measured with decibels. The important thing in any usage of the term decibels is that you know the reference point – the level that is in the denominator of the ratio. Different usages of the term decibel sometimes add different letters to the dB abbreviation to clarify the context, as in dBPWL (decibels-power-level), dBSIL (decibels-sound-intensity-level), and dBFS (decibels-full-scale), all of which are explained below.
Comparing the columns in Table 4.1, we now can see the advantages of decibels over air pressure amplitudes. If we had to graph loudness using Pa as our units, the scale would be so large that the first ten sound levels (from silence all the way up to subways) would not be distinguishable from 0 on the graph. With decibels, loudness levels that are easily distinguishable by the ear can be seen as such on the decibel scale.
Decibels are also more intuitively understandable than air pressure amplitudes as a way of talking about loudness changes. As you work with sound amplitudes measured in decibels, you’ll become familiar with some easy-to-remember relationships summarized in Table 4.2. In an acoustically-insulated lab environment with virtually no background noise, a 1 dB change yields the smallest perceptible difference in loudness. However, in average real-world listening conditions, most people can’t notice a loudness change less than 3 dB. A 10 dB change results in about a doubling of perceived loudness. It doesn’t matter if you’re going from 60 to 70 dBSPL or from 80 to 90 dBSPL. The increase still sounds approximately like a doubling of loudness. In contrast, going from 60 to 70 dBSPL is an increase of 43.24 mPa, while going from 80 to 90 dBSPL is an increase of 432.5 mPa. Here you can see that saying that you “turned up the volume” by a certain air pressure amplitude wouldn’t give much information about how much louder it’s going to sound. Talking about loudness-changes in terms of decibels communicates more.
[table caption=”Table 4.2 How sound level changes in dB are perceived”]
Change of sound amplitude,How it is perceived in human hearing
1 dB,”smallest perceptible difference in loudness, only perceptible in acoustically-insulated noiseless environments”
3 dB,smallest perceptible change in loudness for most people in real-world environments
+10 dB,an approximate doubling of loudness
-10 dB change,an approximate halving of loudness
[/table]
You may have noticed that when we talk about a “decibel change,” we refer to it as simply decibels or dB, whereas if we are referring to a sound loudness level relative to the threshold of hearing, we refer to it as dBSPL. This is correct usage. The difference between 90 and 80 dBSPL is 10 dB. The difference between any two decibels levels that have the same reference point is always measured in dimensionless dB. We’ll return to this in a moment when we try some practice problems in Section 2.
4.1.5.2 Various Usages of Decibels
Now let’s look at the origin of the definition of decibel and how the word can be used in a variety of contexts.
The bel, named for Alexander Graham Bell, was originally defined as a unit for measuring power. For clarity, we’ll call this the power difference bel, also denoted :
[equation caption=”Equation 4.5 , power difference bel”]
$$!1\: power\: difference\: bel=\Delta Power\: B=\log_{10}\left ( \frac{P_{1}}{P_{0}} \right )$$
[/equation]
The decibel is 1/10 of a bel. The decibel turns out to be a more useful unit than the bel because it provides better resolution. A bel doesn’t break measurements into small enough units for most purposes.
We can derive the power difference decibel (Δ Power dB) from the power difference bel simply by multiplying the log by 10. Another name for ΔPower dB is dBPWL (decibels-power-level).
[equation caption=”Equation 4.6, abbreviated dBPWL”]
$$!\Delta Power\: B=dBPWL=10\log_{10}\left ( \frac{P_{1}}{P_{0}} \right )$$
[/equation]
When this definition is applied to give a sense of the acoustic power of a sound, then is the power of sound at the threshold of hearing, which is $$10^{-12}W=1pW$$ (picowatt).
Sound can also be measured in terms of intensity. Since intensity is defined as power per unit area, the units in the numerator and denominator of the decibel ratio are $$\frac{W}{m^{2}}$$, and the threshold of hearing intensity is $$10^{-12}\frac{W}{m^{2}}$$. This gives us the following definition of ΔIntensity dB, also commonly referred to as dBSIL (decibels-sound intensity level).
[equation caption=”Equation 4.7 , abbreviated dBSIL”]
$$!\Delta Intensity\, dB=dBSIL=10\log_{10}\left ( \frac{I_{1}}{I_{0}} \right )$$
[/equation]
Neither power nor intensity is a convenient way of measuring the loudness of sound. We give the definitions above primarily because they help to show how the definition of dBSPL was derived historically. The easiest way to measure sound loudness is by means of air pressure amplitude. When sound is transmitted, air pressure changes are detected by a microphone and converted to voltages. If we consider the relationship between voltage and power, we can see how the definition of ΔVoltage dB was derived from the definition of ΔPower dB. By Equation 4.3, we know that power varies with the square of voltage. From this we get: $$!10\log_{10}\left ( \frac{P_{1}}{P_{0}} \right )=10\log_{10}\left ( \left ( \frac{V_{1}}{V_{0}} \right )^{2} \right )=20\log_{10}\left ( \frac{V_{1}}{V_{0}} \right )$$ The relationship between power and voltage explains why there is a factor of 20 is in Equation 4.4.
[aside width=”125px”]
$$\log_{b}\left ( y^{x} \right )=x\log_{b}y$$
[/aside]
We can show how Equation 4.4 is applied to convert from air pressure amplitude to dBSPL and vice versa. Let’s say we begin with the air pressure amplitude of a humming refrigerator, which is about 0.002 Pa.
$$!dBSPL=20\log_{10}\left ( \frac{0.002\: Pa}{0.00002\: Pa} \right )=20\log_{10}\left ( 100 \right )=20\ast 2=40\: dBSPL$$
Working in the opposite direction, you can convert the decibel level of normal conversation (60 dBSPL) to air pressure amplitude:
$$\begin{align*}& 60=20\log_{10}\left ( \frac{0.002\: Pa}{0.00002\: Pa} \right )=20\log_{10}\left ( 50000x/Pa \right ) \\&\frac{60}{20}=\log_{10}\left ( 50000x/Pa \right ) \\&3=\log_{10}\left ( 50000x/Pa \right ) \\ &10^{3}= 50000x/Pa\\&x=\frac{1000}{50000}Pa \\ &x=0.02\: Pa \end{align*}$$
[aside width=”125px”]
If $$x=\log_{b}y$$
then $$b^{x}=y$$
[/aside]
Thus, 60 dBSPL corresponds to air pressure amplitude of 0.02 Pa.
Rarely would you be called upon to do these conversions yourself. You’ll almost always work with sound intensity as decibels. But now you know the mathematics on which the dBSPL definition is based.
So when would you use these different applications of decibels? Most commonly you use dBSPL to indicate how loud things seem relative to the threshold of hearing. In fact, you use this type of decibel so commonly that the SPL is often dropped off and simply dB is used where the context is clear. You learn that human speech is about 60 dB, rock music is about 110 dB, and the loudest thing you can listen to without hearing damage is about 120 dB – all of these measurements implicitly being dBSPL.
The definition of intensity decibels, dBSIL, is mostly of interest to help us understand how the definition of dBSPL can be derived from dBPWL. We’ll also use the definition of intensity decibels in an explanation of the inverse square law, a rule of thumb that helps us predict how sound loudness decreases as sound travels through space in a free field (Section 4.2.1.6).
There’s another commonly-used type of decibel that you’ll encounter in digital audio software environments – the decibel-full-scale (dBFS). You may not understand this type of decibel completely until you’ve read Chapter 5 because it’s based on how audio signals are digitized at a certain bit depth (the number of bits used for each audio sample). We’ll give the definition here for completeness and revisit it in Chapter 5. The definition of dBFS uses the largest-magnitude sample size for a given bit depth as its reference point. For a bit depth of n, this largest magnitude would be $$2^{n-1}$$.
[equation caption=”Equation 4.8 Decibels-full-scale, abbreviated dBFS”]
$$!dBFS = 20\log_{10}\left ( \frac{\left | x \right |}{2^{n-1}} \right )$$
where n is a given bit depth and x is an integer sample value between $$-2^{n-1}$$ and $$2^{n-1}-1$$.
[/equation]
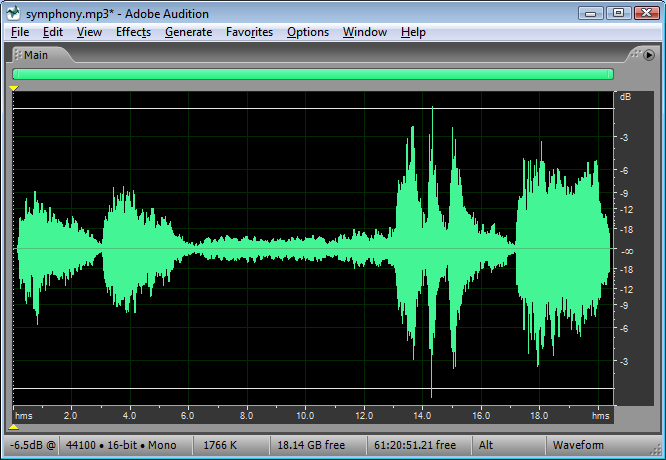
Figure 4.2 shows an audio processing environment where a sound wave is measured in dBFS. Notice that since $$\left | x \right |$$ is never more than $$2^{n-1}$$, $$log_{10}\left ( \frac{\left | x \right |}{2^{n-1}} \right )$$ is never a positive number. When you first use dBFS it may seem strange because all sound levels are at most 0. With dBFS, 0 represents maximum amplitude for the system, and values move toward -∞ as you move toward the horizontal axis, i.e., toward quieter sounds.
The discussion above has considered decibels primarily as they measure sound loudness. Decibels can also be used to measure relative electrical power or voltage. For example, dBV measures voltage using 1 V as a reference level, dBu measures voltage using 0.775 V as a reference level, and dBm measures power using 0.001 W as a reference level. These applications come into play when you’re considering loudspeaker or amplifier power, or wireless transmission signals. In Section 2, we’ll give you some practical applications and problems where these different types of decibels come into play.
The reference levels for different types of decibels are listed in Table 4.3. Notice that decibels are used in reference to the power of loudspeakers or the input voltage to audio devices. We’ll look at these applications more closely in Section 2. Of course, there are many other common usages of decibels outside of the realm of sound.
[table caption=”Table 4.3 Usages of the term decibels with different reference points” width=”80%”]
what is being measured,abbreviations in common usage,common reference point,equation for conversion to decibels
Acoustical,,,
sound power ,dBPWL or ΔPower dB,$$P_{0}=10^{-12}W=1pW(picowatt)$$ ,$$10\log_{10}\left ( \frac{P_{1}}{P_{0}} \right )$$
sound intensity ,dBSIL or ΔIntensity dB,”threshold of hearing, $$I_{0}=10^{-12}\frac{W}{m^{2}}”$$,$$10\log_{10}\left ( \frac{I_{1}}{i_{0}} \right )$$
sound air pressure amplitude ,dBSPL or ΔVoltage dB,”threshold of hearing, $$P_{0}=0.00002\frac{N}{m^{2}}=2\ast 10^{-5}Pa$$”, $$20\log_{10}\left ( \frac{V_{1}}{V_{0}} \right )$$
sound amplitude,dBFS, “$$2^{n-1}$$ where n is a given bit depth x is a sample value, $$-2^{n-1} \leq x \leq 2^{n-1}-1$$”,dBFS=$$20\log_{10}\left ( \frac{\left | x \right |}{2^{n-1}} \right )$$
Electrical,,,
radio frequency transmission power,dBm,$$P_{0}=1 mW = 10^{-3} W$$ ,$$10\log_{10}\left ( \frac{P_{1}}{P_{0}} \right )$$
loudspeaker acoustical power,dBW,$$P_{0}=1 W$$,$$10\log_{10}\left ( \frac{P_{1}}{P_{0}} \right )$$
input voltage from microphone; loudspeaker voltage; consumer level audio voltage,dBV,$$V_{0}=1 V$$,$$20\log_{10}\left ( \frac{V_{1}}{V_{0}} \right )$$
professional level audio voltage,dBu,$$V_{0}=0.775 V$$,$$20\log_{10}\left ( \frac{V_{1}}{V_{0}} \right )$$
[/table]
4.1.5.3 Peak Amplitude vs. RMS Amplitude
Microphones and sound level meters measure the amplitude of sound waves over time. There are situations in which you may want to know the largest amplitude over a time period. This “largest” can be measured in one of two ways: as peak amplitude or as RMS amplitude.
Let’s assume that the microphone or sound level meter is measuring sound amplitude. The sound pressure level of greatest magnitude over a given time period is called the peak amplitude. For a single-frequency sound representable by a sine wave, this would be the level at the peak of the sine wave. The sound represented by Figure 4.3 would obviously be perceived as louder than the same-frequency sound represented by Figure 4.4. However, how would the loudness of a sine-wave-shaped sound compare to the loudness of a square-wave-shaped sound with the same peak amplitude (Figure 4.3 vs. Figure 4.5)? The square wave would actually sound louder. This is because the square wave is at its peak level more of the time as compared to the sine wave. To account for this difference in perceived loudness, RMS amplitude (root-mean-square amplitude) can be used as an alternative to peak amplitude, providing a better match for the way we perceive the loudness of the sound.


Rather than being an instantaneous peak level, RMS amplitude is similar to a standard deviation, a kind of average of the deviation from 0 over time. RMS amplitude is defined as follows:
[equation caption=”Equation 4.9 Equation for RMS amplitude, $$V_{RMS}$$”]
$$!V_{RMS}=\sqrt{\frac{\sum _{i=1}^{n}\left ( S_{i} \right )^{2}}{n}}$$
where n is the number of samples taken and $$S_{i}$$ is the $$i^{th}$$ sample.
[/equation]
[aside]In some sources, the term RMS power is used interchangeably with RMS amplitude or RMS voltage. This isn’t very good usage. To be consistent with the definition of power, RMS power ought to mean “RMS voltage multiplied by RMS current.” Nevertheless, you sometimes see term RMS power used as a synonym of RMS amplitude as defined in Equation 4.9.[/aside]
Notice that squaring each sample makes all the values in the summation positive. If this were not the case, the summation would be 0 (assuming an equal number of positive and negative crests) since the sine wave is perfectly symmetrical.
The definition in Equation 4.9 could be applied using whatever units are appropriate for the context. If the samples are being measured as voltages, then RMS amplitude is also called RMS voltage. The samples could also be quantized as values in the range determined by the bit depth, or the samples could also be measured in dimensionless decibels, as shown for Adobe Audition in Figure 4.6.
For a pure sine wave, there is a simple relationship between RMS amplitude and peak amplitude.
[equation caption=”Equation 4.10 Relationship between $$V_{rms}$$ and $$V_{peak}$$ for pure sine waves”]
for pure sine waves
$$!V_{RMS}=\frac{V_{peak}}{\sqrt{2}}=0.707\ast V_{peak}$$
and
$$!V_{peak}=1.414\ast V_{RMS}$$
[/equation]
Of course most of the sounds we hear are not simple waveforms like those shown; natural and musical sounds contain many frequency components that vary over time. In any case, the RMS amplitude is a better model for our perception of the loudness of complex sounds than is peak amplitude.
Sound processing programs often give amplitude statistics as either peak or RMS amplitude or both. Notice that RMS amplitude has to be defined over a particular window of samples, labeled as Window Width in Figure 4.6. This is because the sound wave changes over time. In the figure, the window width is 1000 ms.

You need to be careful will some usages of the term “peak amplitude.” For example, VU meters, which measure signal levels in audio equipment, use the word “peak” in their displays, where RMS amplitude would be more accurate. Knowing this is important when you’re setting levels for a live performance, as the actual peak amplitude is higher than RMS. Transients like sudden percussive noises should be kept well below what is marked as “peak” on a VU meter. If you allow the level to go too high, the signal will be clipped.
4.1.6 Sound Perception
4.1.6.1 Frequency Perception
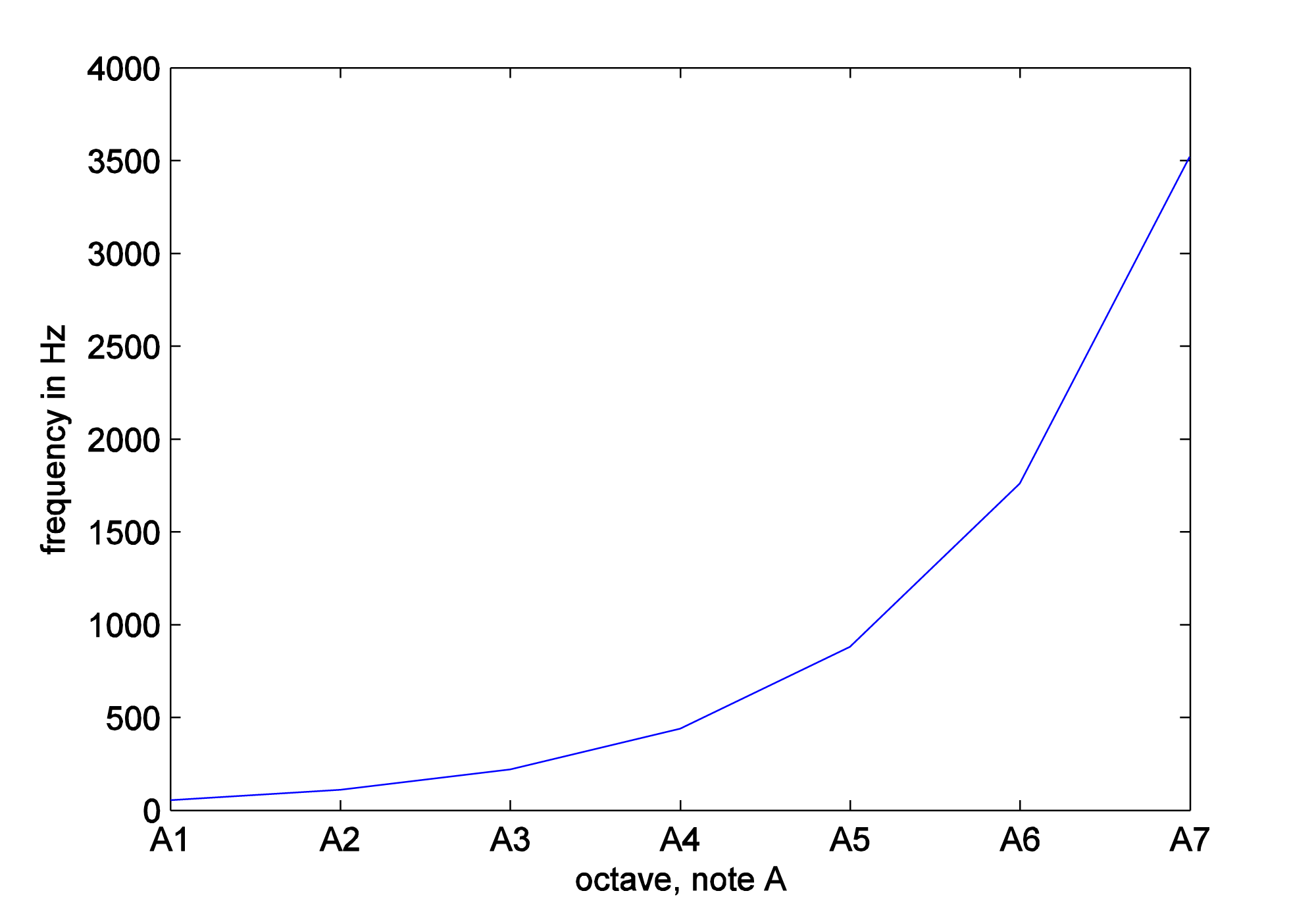
In Chapter 3, we discussed the non-linear nature of pitch perception when we looked at octaves as defined in traditional Western music. The A above middle C (call it A4) on a piano keyboard sounds very much like the note that is 12 semitones above it, A5, except that A5 has a higher pitch. A5 is one octave higher than A4. A6 sounds like A5 and A4, but it’s an octave higher than A5. The progression between octaves is not linear with respect to frequency. A2’s frequency is twice the frequency of A1. A3’s frequency is twice the frequency of A2, and so forth. A simple way to think of this is that as the frequencies increase by multiplication, the perception of the pitch change increases by addition. In any case, the relationship is non-linear, as you can clearly see if you plot frequencies against octaves, as shown in Figure 4.7.
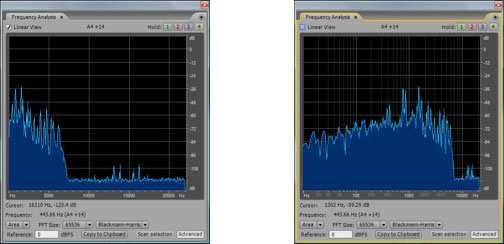
The fact that this is a non-linear relationship implies that the higher up you go in frequencies, the bigger the difference in frequency between neighboring octaves. The difference between A2 and A1 is 110 – 55 = 55 Hz while the difference between A7 and A6 is 3520 – 1760 = 1760 Hz. Because of the non-linearity of our perception, frequency response graphs often show the frequency axis on a logarithmic scale, or you’re given a choice between a linear and a logarithmic scale, as shown in Figure 4.8. Notice that you can select or deselect “linear” in the upper left hand corner. In the figure on the right, the distance between 10 and 100 Hz on the horizontal axis is the same as the distance between 100 and 1000, which is the same as 1000 and 10000. This is more in keeping with how our perception of the pitch changes as the frequencies get higher. You should always pay attention to the scale of the frequency axis in graphs such as this.
The range of frequencies within human hearing is, at best, 20 Hz to 20,000 Hz. The range varies with individuals and diminishes with age, especially for high frequencies. Our hearing is less sensitive to low frequencies than to high; that is, low frequencies have to be more intense for us to hear them than high frequencies.
Frequency resolution (also called frequency discrimination) is our ability to distinguish between two close frequencies. Frequency resolution varies by frequency, loudness, the duration of the sound, the suddenness of the frequency change, and the acuity and training of the listener’s ears. The smallest frequency change that can be noticed as a pitch change is referred to as a just-noticeable-difference (jnd). At low frequencies, it’s possible to notice a difference between frequencies that are separated by just a few Hertz. Within the 1000 Hz to 4000 Hz range, it’s possible for a person to hear a jnd of as little as 1/12 of a semitone. (But 1/12 a semitone step from 1000 Hz is about 88 Hz, while 1/12 a semitone step from 4000 Hz is about 353 Hz.) At low frequencies, tones that are separated by just a few Hertz can be distinguished as separate pitches, while at high frequencies, two tones must be separated by hundreds of Hertz before a difference is noticed.
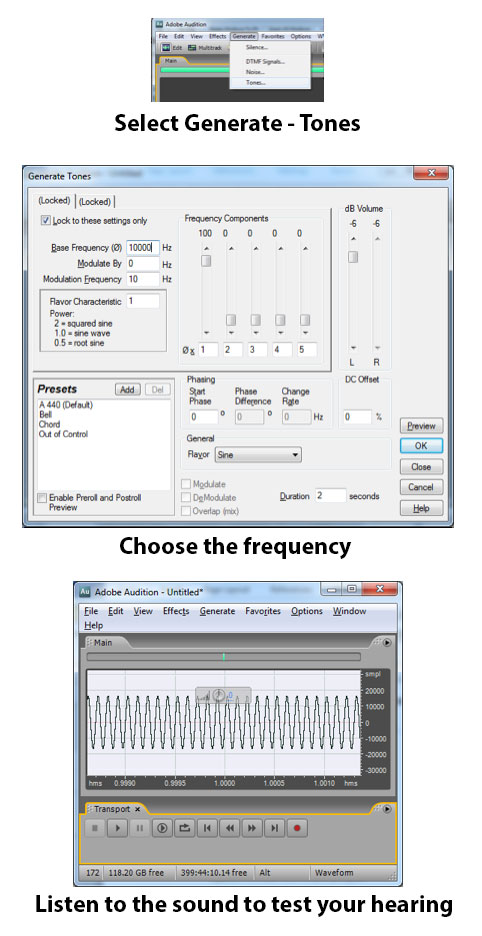
You can test your own frequency range and discrimination with a sound processing program like Audacity or Audition, generating and listening to pure tones, as shown in Figure 4.9 Be aware, however, that the monitors or headphones you use have an impact on your ability to hear the frequencies.
4.1.6.2 Critical Bands
One part of the ear’s anatomy that is helpful to consider more closely is the area in the inner ear called the basilar membrane. It is here that sound vibrations are detected, separated by frequencies, and transformed from mechanical energy to electrical impulses sent to the brain. The basilar membrane is lined with rows of hair cells and thousands of tiny hairs emanating from them. The hairs move when stimulated by vibrations, sending signals to their base cells and the attached nerve fibers, which pass electrical impulses to the brain. In his pioneering work on frequency perception, Harvey Fletcher discovered that different parts of the basilar membrane resonate more strongly to different frequencies. Thus, the membrane can be divided into frequency bands, commonly called critical bands. Each critical band of hair cells is sensitive to vibrations within a certain band of frequencies. Continued research on critical bands has shown that they play an important role in many aspects of human hearing, affecting our perception of loudness, frequency, timbre, and dissonance vs. consonance. Experiments with critical bands have also led to an understanding of frequency masking, a phenomenon that can be put to good use in audio compression.
Critical bands can be measured by the band of frequencies that they cover. Fletcher discovered the existence of critical bands in his pioneering work on the cochlear response. Critical bands are the source of our ability to distinguish one frequency from another. When a complex sound arrives at the basilar membrane, each critical band acts as a kind of bandpass filter, responding only to vibrations within its frequency spectrum. In this way, the sound is divided into frequency components. If two frequencies are received within the same band, the louder frequency can overpower the quieter one. This is the phenomenon of masking, first observed in Fletcher’s original experiments.
[aside]A bandpass filter allows only the frequencies in a defined band to pass through, filtering out all other frequencies. Bandpass filters are studied in Chapter 7.[/aside]
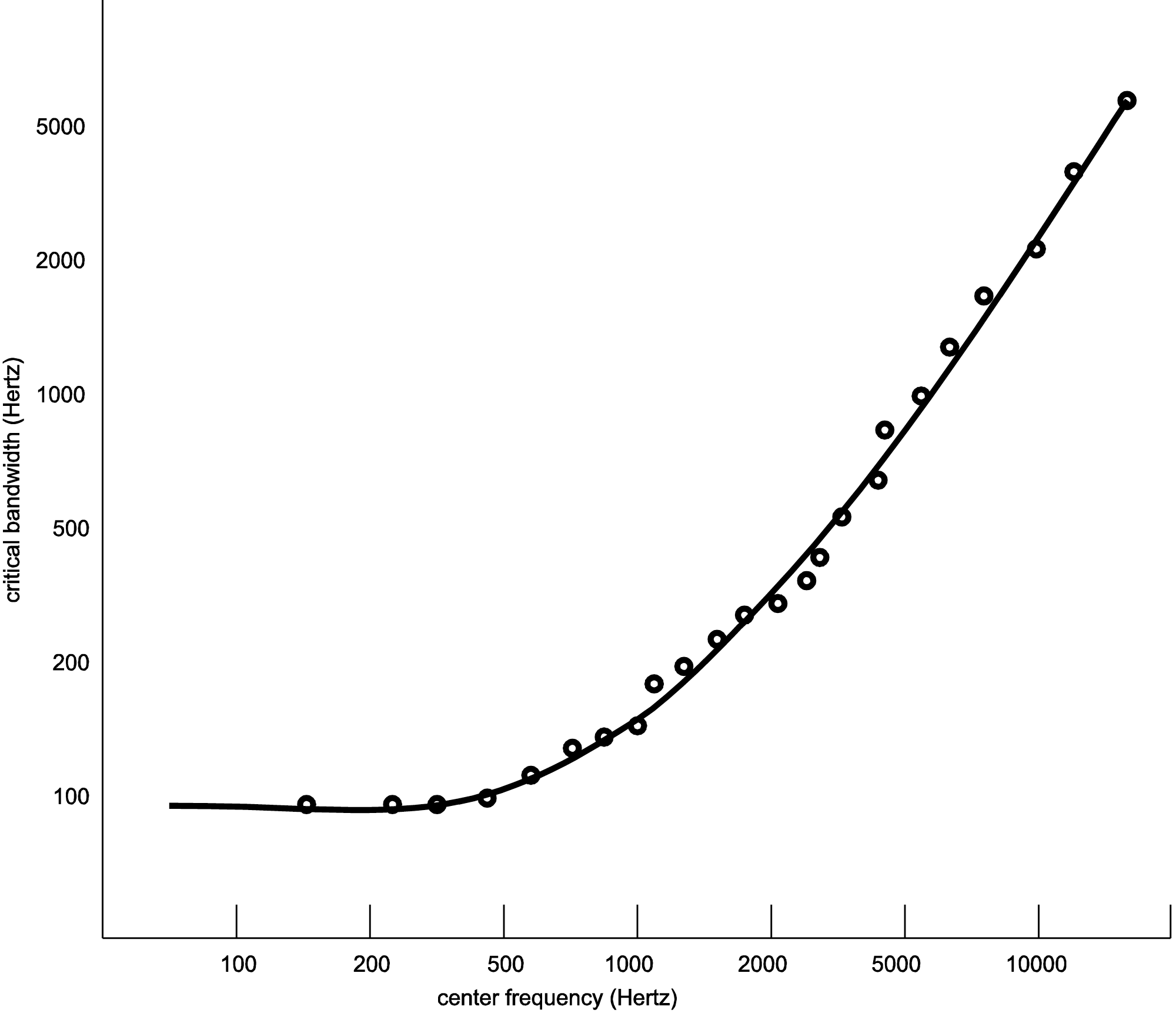
Critical bands within the ear are not fixed areas but instead are created during the experience of sound. Any audible sound can create a critical band centered on it. However, experimental analyses of critical bands have arrived at approximations that are useful guidelines in designing audio processing tools. Table 4.4 is one model taken after Fletcher, Zwicker, and Barkhausen’s independent experiments, as cited in (Tobias, 1970). Here, the basilar membrane is divided into 25 overlapping bands, each with a center frequency and with variable bandwidths across the audible spectrum. The width of each band is given in Hertz, semitones, and octaves. (The widths in semitones and octaves were derived from the widths in Hertz, as explained in Section 4.3.1.) The center frequencies are graphed against the critical bands in Hertz in Figure 4.10.
You can see from the table and figure that, measured in Hertz, the critical bands are wider for higher frequencies than for lower. This implies that there is better frequency resolution at lower frequencies because a narrower band results in less masking of frequencies in a local area.
The table shows that critical bands are generally in the range of two to four semitones wide, mostly less than four. This observation is significant as it relates to our experience of consonance vs. dissonance. Recall from Chapter 3 that a major third consists of four semitones. For example, the third from C to E is separated by four semitones (stepping from C to C#, C# to D, D to D #, and D# to E.) Thus, the notes that are played simultaneously in a third generally occupy separate critical bands. This helps to explain why thirds are generally considered consonant – each of the notes having its own critical band. Seconds, which exist in the same critical band, are considered dissonant. At very low and very high frequencies, thirds begin to lose their consonance to most listeners. This is consistent with the fact that the critical bands at the low frequencies (100-200 and 200-300 Hz) and high frequencies (over 12000 Hz) span more than a third, so that at these frequencies, a third lies within a single critical band.
[table caption=”Table 4.4 An estimate of critical bands using the Bark scale” width=”80%”]
Critical Band,Center Frequency in Hertz,Range of Frequencies in Hertz,Bandwidth in Hertz,Bandwidth in Semitones Relative to Start*,Bandwidth in Octaves Relative to Start*
1,50,1-100,100,,-
2,150,100-200,100,12,1
3,250,200-300,100,7,0.59
4,350,300–400,100,5,0.42
5,450,400–510,110,4,0.31
6,570,510–630,120,4,0.3
7,700,630–770,140,3,0.29
8,840,770–920,150,3,0.26
9,1000,920–1080,160,3,0.23
10,1170,1080–1270,190,3,0.23
11,1370,1270–1480,210,3,0.22
12,1600,1480–1720,240,3,0.22
13,1850,1720–2000,280,3,0.22
14,2150,2000–2320,320,3,0.21
15,2500,2320–2700,380,3,0.22
16,2900,2700–3150,450,3,0.22
17,3400,3150–3700,550,3,0.23
18,4000,3700–4400,700,3,0.25
19,4800,4400–5300,900,3,0.27
20,5800,5300–6400,1100,3,0.27
21,7000,6400–7700,1300,3,0.27
22,8500,7700–9500,1800,4,0.3
23,10500,9500–12000,2500,4,0.34
24,13500,12000–15500,3500,4,0.37
25,18775,15500–22050,6550,6,0.5
*See Section 4.3.2 for an explanation of how the last two columns of this table were derived.[attr colspan=”6″]
[/table]
4.1.6.3 Amplitude Perception
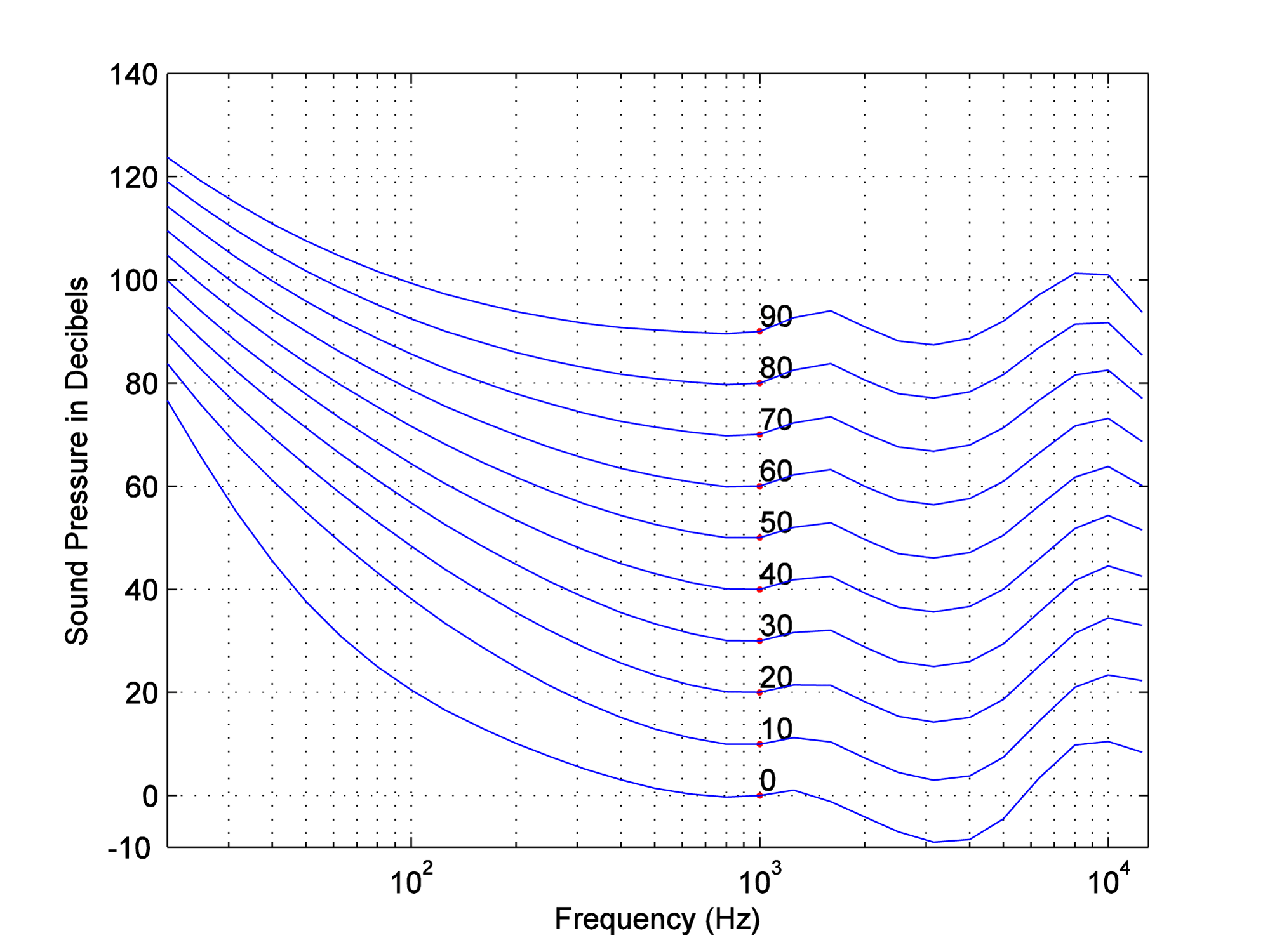
In the early 1930s at Bell Laboratories, groundbreaking experiments by Fletcher and Munson clarified the extent to which our perception of loudness varies with frequency (Fletcher and Munson 1933). Their results, refined by later researchers (Robinson and Dadson, 1956) and adopted as International Standard ISO 226, are illustrated in a graph of equal-loudness contours shown in Figure 4.11. In general, the graph shows how much you have to “turn up” or “turn down” a single frequency tone to make it sound equally loud to a 1000 Hz tone. Each curve on the graph represents an n-phon contour. One phon is defined as a 1000 Hz sound wave at a loudness of 1 dBSPL. An n-phon contour is created as follows:
- Frequency is on the horizontal axis and loudness in decibels is on the vertical axis
- n curves are drawn.
- Each curve, from 1 to n, represents the intensity levels necessary in order to make each frequency, across the audible spectrum, sound equal in loudness to a 1000 Hz wave at n dBSPL.
Let’s consider, for example, the 10-phon contour. This contour was creating by playing a 1000 Hz pure tone at a loudness level of 10 dBSPL, and then asking groups of listeners to say when they thought pure tones at other frequencies matched the loudness of the 1000 Hz tone. Notice that low-frequency tones had to be increased by 60 or 75 dB to sound equally loud. Some of the higher-frequency tones – in the vicinity of 3000 Hz – actually had to be turned down in volume to sound equally loud to the 10 dBSPL 1000 Hz tone. Also notice that the louder the 1000 Hz tone is, the less lower-frequency tones have to be turned up to sound equal in loudness. For example, the 90-phon contour goes up only about 30 dB to make the lowest frequencies sound equal in loudness to 1000 Hz at 90 dBSPL, whereas the 10-phon contour has to be turned up about 75 dB.
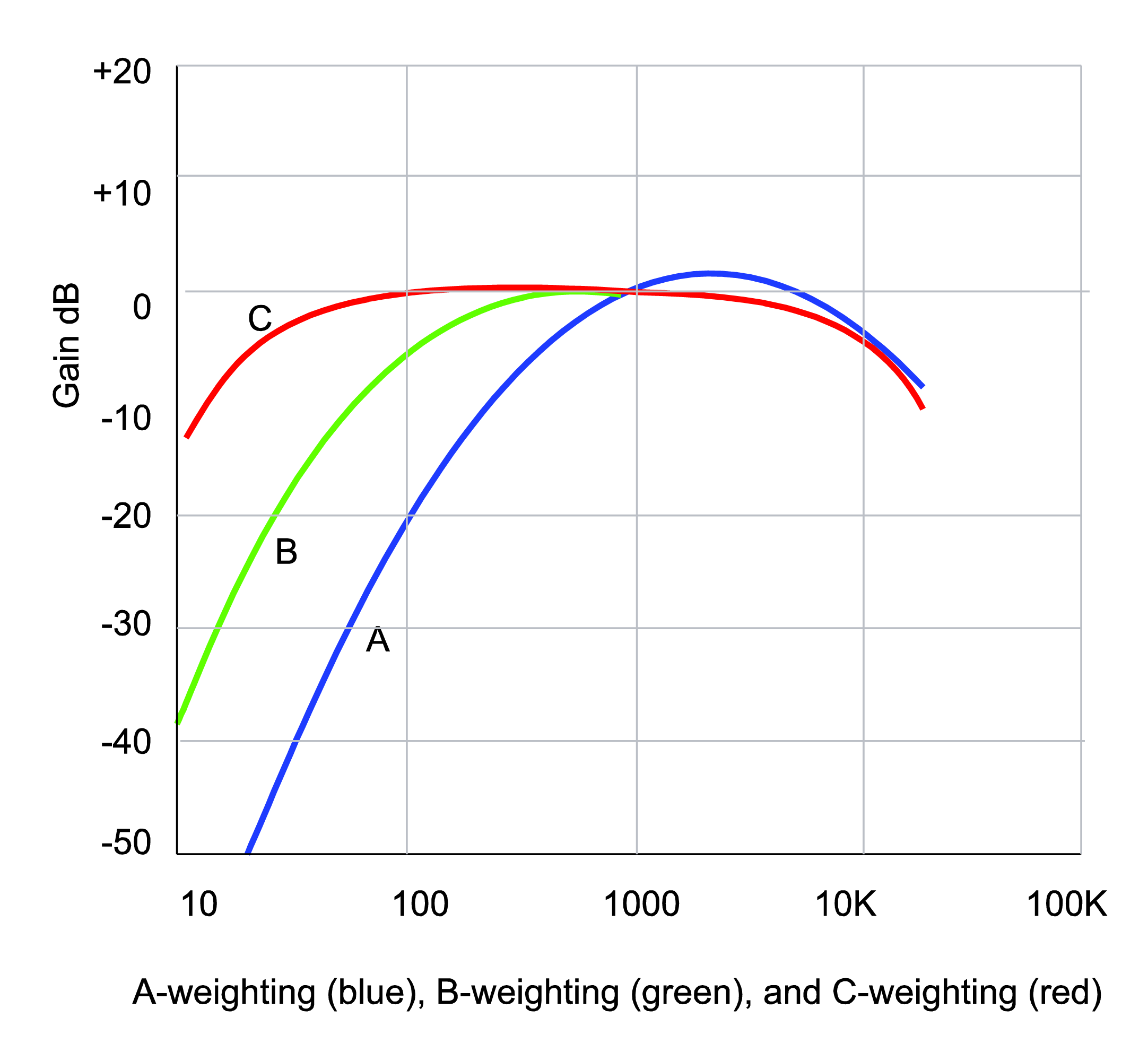
With the information captured in the equal loudness contours, devices that measure the loudness of sounds – for example, SPL meters (sound pressure level meters) – can be designed so that they compensate for the fact that low frequency sounds seem less loud than high frequency sounds at the same amplitude. This compensation is called “weighting.” Figure 4.12 graphs three weighting functions – A, B, and C. The A, B, and C-weighting functions are approximately inversions of the 40-phon, 70-phon, and 100-phon loudness contours, respectively. This implies that applying A-weighting in an SPL meter causes the meter to measure loudness in a way that matches our differences in loudness perception at 40-phons.
To understand how this works, think of the graphs of the weighting as frequency filters – also called frequency response graphs. When a weighting function is applied by an SPL meter, the meter uses a filter to reduce the influence of frequencies to which our ears are less sensitive, and conversely to increase the weight of frequencies that our ears are sensitive to. The fact that the A-weighting graph is lower on the left side than on the right means that an A-weighted SPL meter reduces the influence of low-frequency sounds as it takes its overall loudness measurement. On the other hand, it boosts the amplitude of frequencies around 3000 Hz, as seen by the bump above 0 dB around 3000 Hz. It doesn’t matter that the SPL meter meddles with frequency components as it measures loudness. After all, it isn’t measuring frequencies. It’s measuring how loud the sounds seem to our ears. The use of weighted SPL meters is discussed further in Section 4.2.2.2.
(Figure derived from a program by Jeff Tacket, posted at the MATLAB Central File Exchange)
4.1.7 The Interaction of Sound with its Environment
Sometimes it’s convenient to simplify our understanding of sound by considering how it behaves when there is nothing in the environment to impede it. An environment with no physical influences to absorb, reflect, diffract, refract, reverberate, resonate, or diffuse sound is called a free field. A free field is an idealization of real world conditions that facilitates our analysis of how sound behaves. Sound in a free field can be pictured as radiating out from a point source, diminishing in intensity as it gets farther from the source. A free field is partially illustrated in Figure 4.18. In this figure, sound is radiating out from a loudspeaker, with the colors indicating highest to lowest intensity sound in the order red, orange, yellow, green, and blue. The area in front of the loudspeaker might be considered a free field. However, because the loudspeaker partially blocks the sound from going behind itself, the sound is lower in amplitude there. You can see that there is some sound behind the loudspeaker, resulting from reflection and diffraction.

4.1.7.1 Absorption, Reflection, Refraction, and Diffraction
In the real world, there are any number of things that can get in the way of sound, changing its direction, amplitude, and frequency components. In enclosed spaces, absorption plays an important role. Sound absorption is the conversion of sound’s energy into heat, thereby diminishing the intensity of the sound. The diminishing of sound intensity is called attenuation. A general mathematical formulation for the way sound attenuates as it moves through the air is captured in the inverse square law, which shows that sound decreases in intensity in proportion to the square of the distance from the source. (See Section 4.2.1.6.) The attenuation of sound in the air is due to the air molecules themselves absorbing and converting some of the energy to heat. The amount of attenuation depends in part on the air temperature and relative humidity. Thick, porous materials can absorb and attenuate the sound even further, and they’re often used in architectural treatments to modify and control the acoustics of a room. Even hard, solid surfaces absorb some of the sound energy, although most of it is reflected back. The material of walls and ceilings, the number and material of seats, the number of persons in an audience, and all solid objects have to be taken into consideration acoustically in sound setups for live performance spaces.
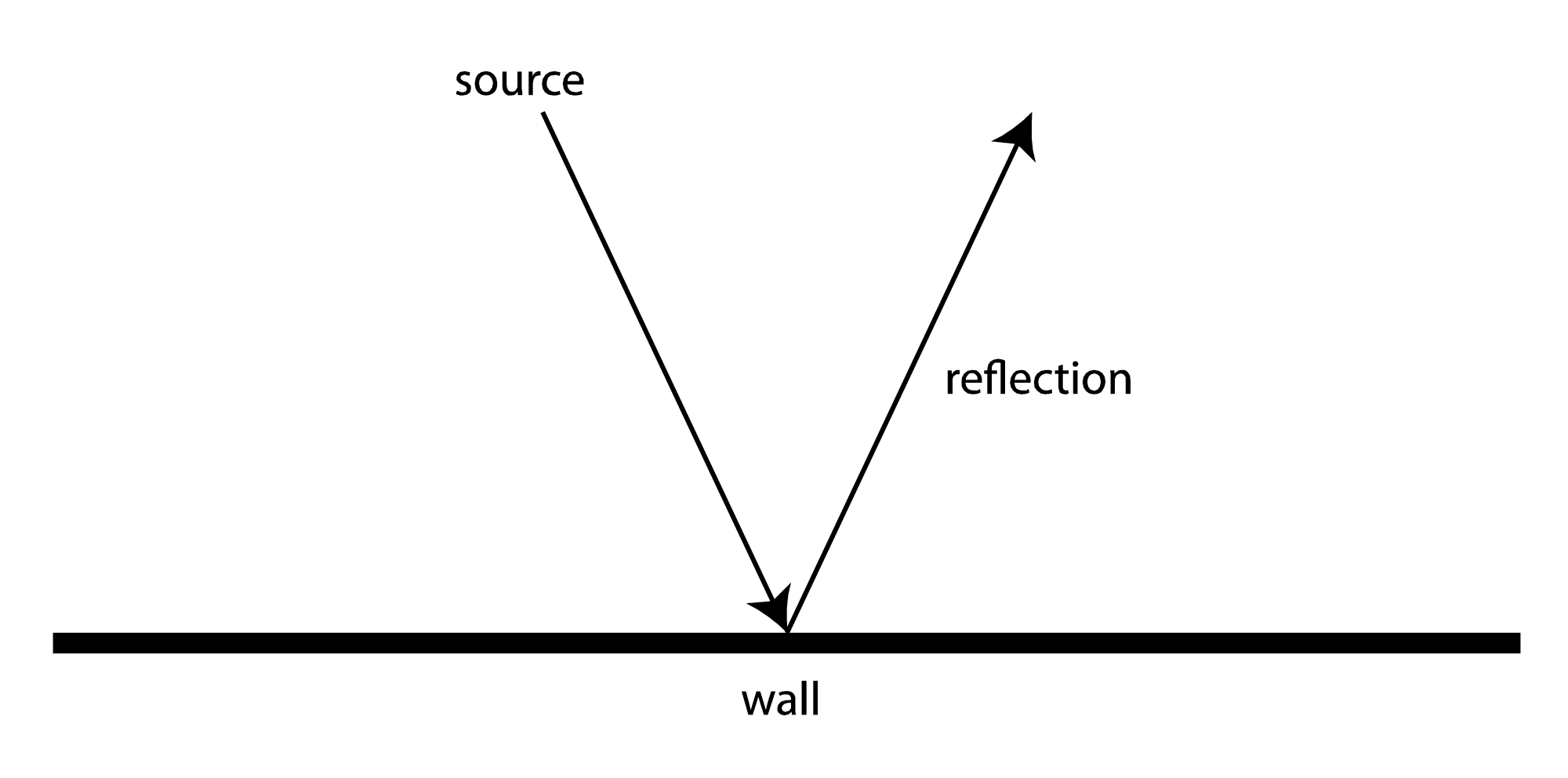
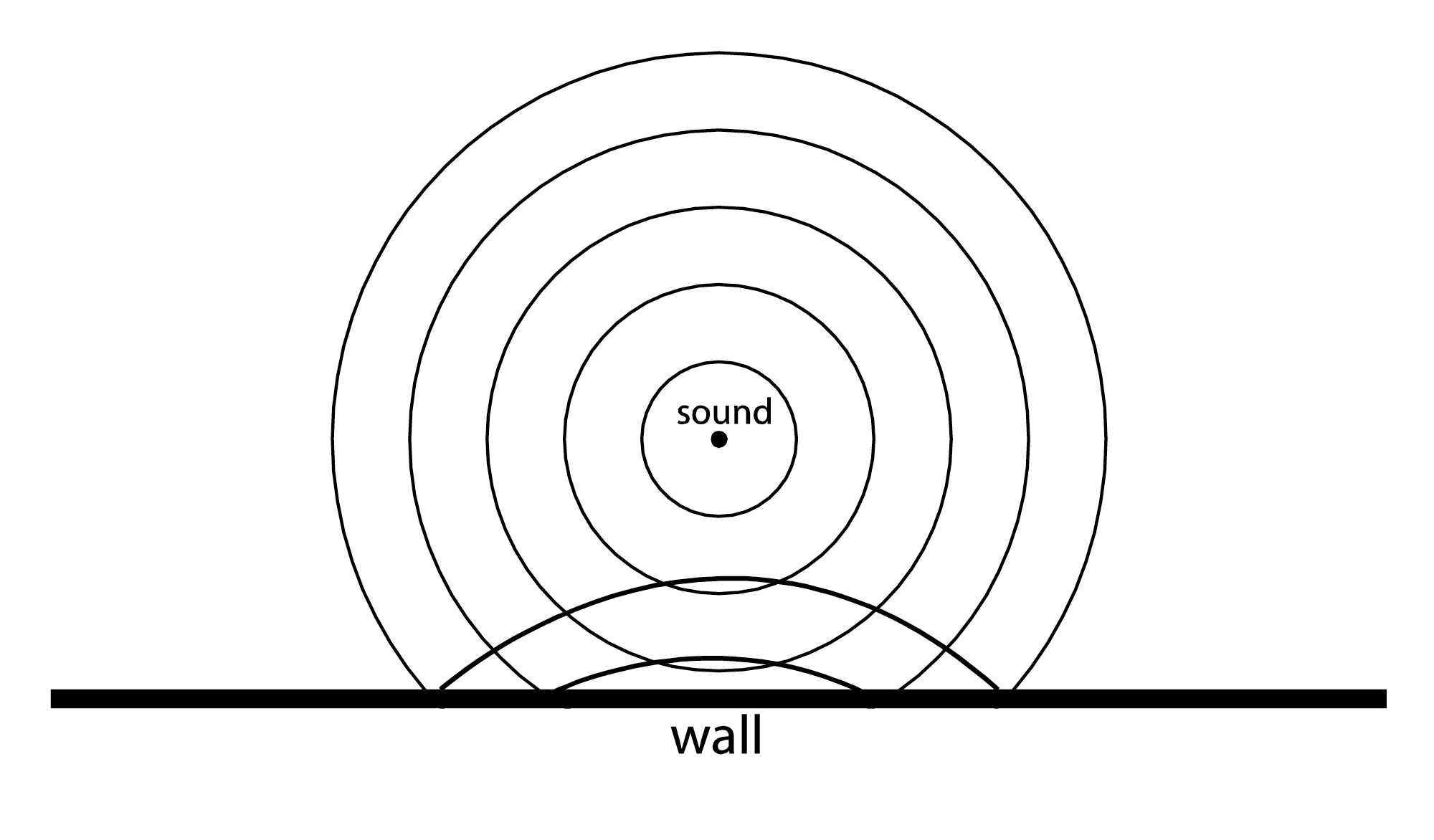
Sound that is not absorbed by objects is instead reflected from, diffracted around, or refracted into the object. Hard surfaces reflect sound more than soft ones, which are more absorbent. The law of reflection states that the angle of incidence of a wave is equal to the angle of reflection. This means that if a wave were to propagate in a straight line from its source, it reflects in the way pictured in Figure 4.15. In reality, however, sound radiates out spherically from its source. Thus, a wavefront of sound approaches objects and surfaces from various angles. Imagine a cross-section of the moving wavefront approaching a straight wall, as seen from above. Its reflection would be as pictured in Figure 4.15, like a mirror reflection.
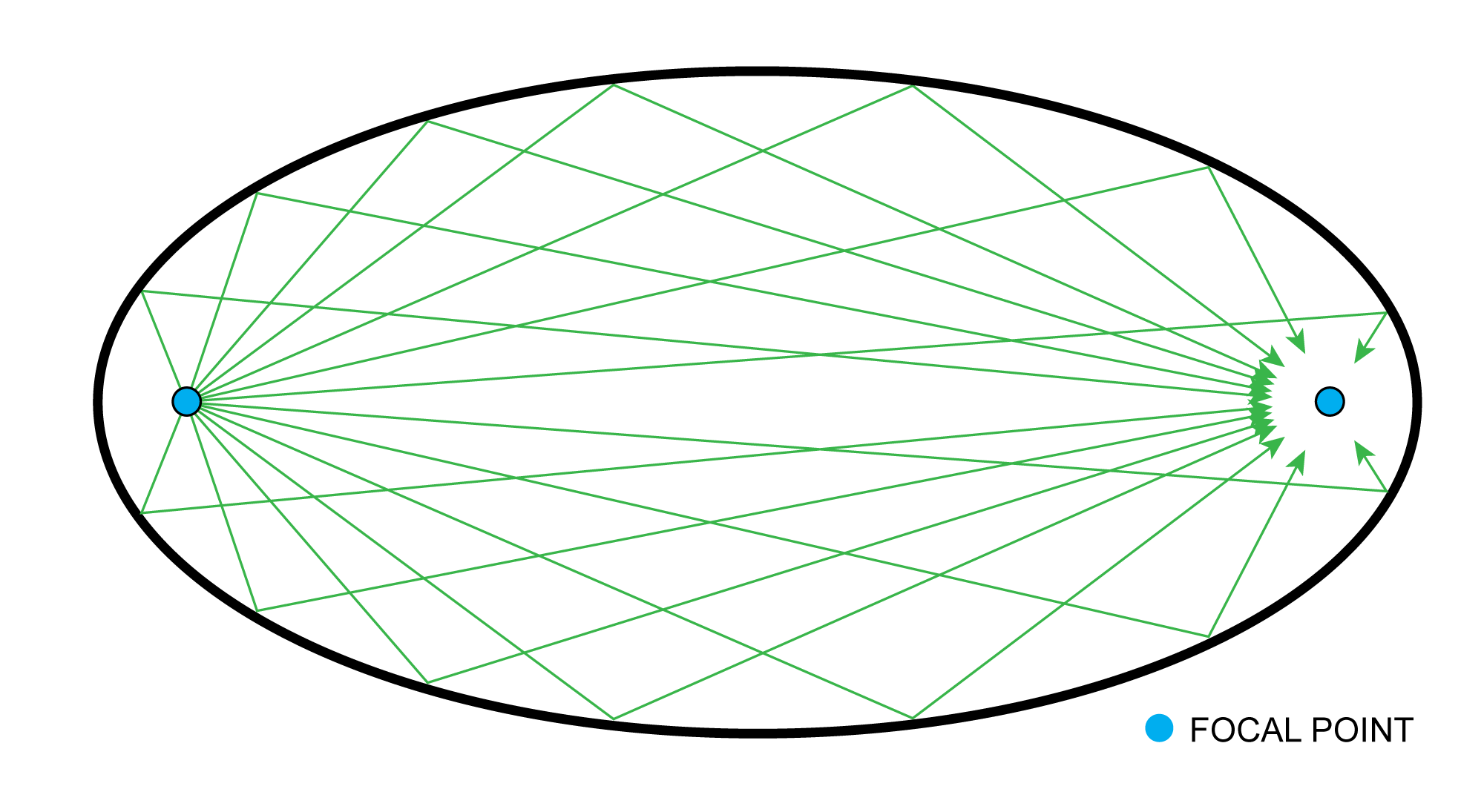
In a special case, if the wavefront were to approach a concave curved solid surface, it would be reflected back to converge at one point in the room, the location of that point depending on the angle of the curve. This is how whispering rooms are constructed, such that two people whispering in the room can hear each other perfectly if they’re positioned at the sound’s focal points, even though the focal points may be at the far opposite ends of the room. A person positioned elsewhere in the room cannot hear their whispers at all. A common shape found with whispering rooms is an ellipse, as seen in Figure 4.16. The shape and curve of these walls cause any and all sound emanating from one focal point to reflect directly to the other.
[aside]
Diffraction also has a lot to do with microphone and loudspeaker directivity. Consider how microphones often have different polar patterns at different frequencies. Even with a directional mic, you’ll often see lower frequencies behave more omnidirectionally, and sometimes an omnidirectional mic may be more directional at high frequencies. That’s largely because of the size of the wavelength compared to size of the microphone diaphragm. It’s hard for high frequencies to diffract around a larger object, so for a mic to have a truly omnidirectional pattern, the diaphragm has to be very small.
[/aside]
Diffraction is the bending of a sound wave as it moves past an obstacle or through a narrow opening. The phenomenon of diffraction allows us to hear sounds from sources that are not in direct line-of-sight, such as a person standing around a corner or on the other side of a partially obstructing object. The amount of diffraction is dependent on the relationship between the size of the obstacle and the size of the sound’s wavelength. Low frequency sounds (i.e., long-wavelength sounds) are diffracted more than high frequencies (i.e., short wavelengths) around the same obstacle. In other words, low frequency sounds are better able to travel around obstacles. In fact, if the wavelength of a sound is significantly larger than an obstacle that the sound encounters, the sound wave continues as if the obstacle isn’t even there. For example, your stereo speaker drivers are probably protected behind a plastic or metal grill, yet the sound passes through it intact and without noticeable coloration. The obstacle presented by the wire mesh of the grill (perhaps a millimeter or two in diameter) is even smaller than the smallest wavelength we can hear (about 2 centimeters for 20 kHz, 10 to 20 times larger than the wire), so the sound diffracts easily around it.
Refraction is the bending of a sound wave as it moves through different media. Typically we think of refraction with light waves, as when we look at something through glass or that is underwater. In acoustics, the refraction of sound waves tends to be more gradual, as the properties of the air change subtly over longer distances. This causes a bending in sound waves over a long distance, primarily due to temperature, humidity, and in some cases wind gradients over distance and altitude. This bending can result in noticeable differences in sound levels, either as a boost or an attenuation, also referred to as a shadow zone.
4.1.7.2 Reverberation, Echo, Diffusion, and Resonance
Reverberation is the result of sound waves reflecting off of many objects or surfaces in the environment. Imagine an indoor room in which you make a sudden burst of sound. Some of that sound is transmitted through or absorbed by the walls or objects, and the rest is reflected back, bouncing off the walls, ceilings, and other surfaces in the room. The sound wave that travels straight from the sound source to your ears is called the direct signal. The first few instances of reflected sound are called primary or early reflections. Early reflections arrive at your ears about 60 ms or sooner after the direct sound, and play a large part in imparting a sense of space and room size to the human ear. Early reflections may be followed by a handful of secondary and higher-order reflections. At this point, the sound waves have had plenty of opportunity to bounce off of multiple surfaces, multiple times. As a result, the reflections that are arriving now are more numerous, closer together in time, and quieter. Much of the initial energy initial energy of the reflections has been absorbed by surfaces or expended in the distance traveled through the air. This dense collection of reflections is reverberation, illustrated in Figure 4.17. Assuming that the sound source is only momentary, the generated sound eventually decays as the waves lose energy, the reverberation becoming less and less loud until the sound is no longer discernable. Typically, reverberation time is defined as the time it takes for the sound to decay in level by 60 dB from its direct signal.

Single, strong reflections that reach the ear a significant amount of time – about 100 ms – after the direct signal can be perceived as an echo – essentially a separate recurrence of the original sound. Even reflections as little as 50 ms apart can cause an audible echo, depending on the type of sound and room acoustics. While echo is often employed artistically in music recordings, echoes tend to be detrimental and distracting in a live setting and are usually avoided or require remediation in performance and listening spaces.
Diffusion is another property that interacts with reflections and reverberation. Diffusion relates to the ability to distribute sound energy more evenly in a listening space. While a flat, even surface reflects sounds strongly in a predictable direction, uneven surfaces or convex curved surfaces diffuse sound more randomly and evenly. Like absorption, diffusion is often used to treat a space acoustically to help break up harsh reflections that interfere with the natural sound. Unlike absorption, however, which attempts to eliminate the unwanted sound waves by reducing the sound energy, diffusion attempts to redirect the sound waves in a more natural manner. A room with lots of absorption has less overall reverberation, while diffusion maintains the sound’s intensity and helps turn harsh reflections into more pleasant reverberation. Usually a combination of absorption and diffusion is employed to achieve the optimal result. There are many unique types of diffusing surfaces and panels that are manufactured based on mathematical algorithms to provide the most random, diffuse reflections possible
Putting these concepts together, we can say that the amount of time it takes for a particular sound to decay depends on the size and shape of the room, its diffusive properties, and the absorptive properties of the walls, ceilings, and objects in the room. In short, all the aforementioned properties determine how sound reverberates in a space, giving the listener a “sense of place.”
Reverberation in an auditorium can enhance the listener’s experience, particularly in the case of a music hall where it gives the individual sounds a richer quality and helps them blend together. Excessive reverberation, however, can reduce intelligibility and make it difficult to understand speech. In Chapter 7, you’ll see how artificial reverberation is applied in audio processing.
A final important acoustical property to be considered is resonance. In Chapter 2, we defined resonance as an object’s tendency to vibrate or oscillate at a certain frequency that is basic to its nature. Like a musical instrument, a room has a set of resonant frequencies, called its room modes. Room modes result in locations in a room where certain frequencies are boosted or attenuated, making it difficult to give all listeners the same audio experience. We’ll talk more about how to deal with room modes in Section 4.2.2.5.
4.2.1 Working with Decibels
4.2.1.1 Real-World Considerations
We now turn to practical considerations related to the concepts introduced in Section 1. We first return to the concept of decibels.
An important part of working with decibel values is learning to recognize and estimate decibel differences. If a sound isn’t loud enough, how much louder does it need to be? Until you can answer that question in a dB value, you will have a hard time figuring out what to do. It’s also important to understand the kind of dB differences that are audible. The average listener cannot distinguish a difference in sound pressure level that is less than 3 dB. With training, you can learn to recognize differences in sound pressure level of 1 dB, but differences that are less than 1 dB are indistiguishable to even well-trained listeners.
Understanding the limitations to human hearing is very important when working with sound. For example, when investigating changes you can make to your sound equipment to get higher sound pressure levels, you should be aware that unless the change amounts to 3 dB or more, most of your listeners will probably not notice. This concept also applies when processing audio signals. When manipulating the frequency response of an audio signal using an equalizer, unless you’re making a difference of 3 dB with one of your filters, the change will be imperceptible to most listeners.
Having a reference to use when creating audio material or sound systems is also helpful. For example, there are usually loudness requirements imposed by the television network for television content. If these requirements are not met, there will be level inconsistencies between the various programs on the television station that can be very annoying to the audience. These requirements could be as simple as limiting peak levels to -10 dBFS or as strict as meeting a specified dBFS average across the duration of the show.
You might also be putting together equipment that delivers sound to a live audience in an acoustic space. In that situation you need to know how loud in dBSPL the system needs to perform at the distance of the audience. There is a minimum dBSPL level you need to achieve in order to get the signal above the noise floor of the room, but there is also a maximum dBSPL level you need to stay under in order to avoid damaging people’s hearing or violating laws or policies of the venue. Once you know these requirements, you can begin to evaluate the performance of the equipment to verify that it can meet these requirements.
4.2.1.2 Rules of Thumb
Table 4.2 gives you some rules of thumb for how changes in dB are perceived as changes in loudness. Turn a sound up by 10 dB and it sounds about twice as loud. Turn it up by 3 dB, and you’ll hardly notice any difference.
Similarly, Table 4.5 gives you some rules of thumb regarding power and voltage changes. These rules give you a quick sense of how boosts in power and voltage affect sound levels.
[table caption=”Table 4.5 Rules of thumb for changes in power, voltage, or distance in dB” width=”60%”]
“change in power, voltage, or distance”,approximate change in dB
power $$\ast$$ 2,3 dB increase
power ÷ 2,3 dB decrease
power $$\ast$$ 10,10 dB increase
power ÷ 10,10 dB decrease
voltage $$\ast$$ 2,6 dB increase
voltage ÷ 2,6 dB decrease
voltage $$\ast$$ 10,20 dB increase
voltage ÷ 10,20 dB decrease
distance away from source $$\ast$$ 2,6 dB decrease
[/table]
In the following sections, we’ll give examples of how these rules of thumb come into practice. A mathematical justification of these rules is given in Section 3.
4.2.1.3 Determining Power and Voltage Differences and Desired Changes in Power Levels
Decibels are also commonly used to compare the power levels of loudspeakers and amplifiers. For power, Equation 4.6 applies — $$\Delta Power \: dB = 10\log_{10}\left ( \frac{P_{1}}{P_{0}} \right )$$.
Based on this equation, how much more powerful is an 800 W amplifier than a 200 W amplifier, in decibels?
$$!10\log_{10}\left ( \frac{800\, W}{200\, W} \right )=10\log_{10}4=6\: dB\: increase \: in \:power$$
For voltages, Equation 4.4 is used ($$\Delta Voltage\:dB=20\log_{10}\left ( \frac{V_{1}}{V_{0}} \right )$$). If you increase a voltage level from 100 V to 1000 V, what is the increase in decibels?
$$!20\log_{10}\left ( \frac{100\:V}{10\: V} \right )=20\log_{10}10=20\:dB \: increase\:in\:voltage$$
[aside]
Multiplying power times 2 corresponds to multiplying voltage times $$\sqrt{2}$$ because power is proportional to voltage squared: $$P\propto V^{2}$$
Thus
$$!110\log_{10}\left ( \frac{2\ast P_{0}}{P_{0}} \right )=$$
$$!10\log_{10}\left ( \frac{\sqrt{2} \ast V_{0}}{V_{0}} \right )^{2}=3\:dB\:increase.$$
[/aside]
It’s worth pointing out here that because the definition of decibels-sound-pressure-level was derived from the power decibel definition, then if there’s a 3 dB increase in the power of an amplifier, there is a corresponding 3 dB increase in the sound pressure level it produces. We know that a 3 dB increase in sound pressure level is barely detectable, so the implication is that doubling the power of an amplifier doesn’t increase the loudness of the sounds it produces very much. You have to multiply the power of the amplifier by ten in order to get sounds that are approximately twice asloud.
The fact that doubling the power gives about a 3 dB increase in sound pressure level has implications with regard to how many speakers you ought to use for a given situation. If you double the speakers (assuming identical speakers), you double the power, but you get only a 3 dB increase in sound level. If you quadruple the speakers, you get a 6 dB increase in sound because each time you double, you go up by 3 dB. If you double the speakers again (eight speakers now), you hypothetically get a 9 dB increase, not taking into account other acoustical factors that may affect the sound level.
Often, your real world problem begins with a dB increase you’d like to achieve in your live sound setup. What if you want to increase the level by ΔdB? You can figure out how to do this with the power ratio formula, derived in Equation 4.11.
[equation caption=”Equation 4.11 Derivation of power ratio formula”]
$$!\Delta dB=10\log_{10}\left ( \frac{P_{1}}{P_{0}} \right )$$
$$!\frac{\Delta dB}{10}=\log_{10}\left ( \frac{P_{1}}{P_{0}} \right )$$
Thus
$$!\frac{P_{1}}{P_{0}}=10^{\frac{\Delta dB}{10}}$$
where $$P_{0}$$ is the starting power, $$P_{1}$$ is the new power level, and ΔdB is the desired change in decibels
[/equation]
It may help to recast the equation to clarify that for the problem we’ve described, the desired decibel change and the beginning power level are known, and we wish to compute the new power level needed to get this decibel change.
[equation caption=”Equation 4.12 Power ratio formula”]
$$!P_{1}=P_{0}\ast 10^\frac{\Delta dB}{10}$$
where $$P_{0}$$ is the starting power, $$P_{1}$$ is the new power level, and ΔdB is the desired change in decibels
[/equation]
Applying this formula, what if you start with a 300 W amplifier and want to get one that is 15 dB louder?
$$!P_{1}=300\,W\ast10^{\frac{15}{10}}=9486\,W$$
You can see that it takes quite an increase in wattage to increase the power by 15 dB.
Instead of trying to get more watts, a better strategy would be to choose different loudspeakers that have a higher sensitivity. The sensitivity of a loudspeaker is defined as the sound pressure level that is produced by the loudspeaker with 1 watt of power when measured 1 meter away. Also, because the voltage gain in a power amplifier is fixed, before you go buy a bunch of new loudspeakers, you may also want to make sure that you’re feeding the highest possible voltage signal into the power amplifier. It’s quite possible that the 15 dB increase you’re looking for is hiding somewhere in the signal chain of your sound system due to inefficient gain structure between devices. If you can get 15 dB more voltage into the amplifier by optimizing your gain structure, the power amplifier quite happily amplifies that higher voltage signal assuming you haven’t exceeded the maximum input voltage for the power amplifier. Chapter 8 includes a Max demo on gain structure that may help you with this concept.
4.2.1.4 Converting from One Type of Decibels to Another
A similar problem arises when you have two pieces of sound equipment whose nominal output levels are measured in decibels of different types. For example, you may want to connect two devices where the nominal voltage output of one is given in dBV and the nominal voltage output of the other is given in dBu. You first want to know if the two voltage levels are the same. If they are not, you want to know how much you have to boost the one of lower voltage to match the higher one.
The way to do this is to convert both dBV and dBu back to voltage. You can then compare the two voltage levels in dB. From this you know how much the lower voltage hardware needs to be boosted. Consider an example where one device has an output level of −10 dBv and the other operates at 4 dBu.
Convert −10 dBV to voltage:
$$!-10=20\log_{10}\left ( \frac{v}{1} \right )$$
$$!\frac{-10}{20}=\log_{10}v$$
$$!-0.5=\log_{10}v$$
$$!10^{-0.5}=v\approx 0.316$$
Thus, −10 dBV converts to 0.316 V.
By a similar computation, we get the voltage corresponding to 4 dBu, this time using 0.775 V as the reference value in the denominator.
Convert 4 dBu to voltage:
$$!4=20\log_{10}\left ( \frac{v}{0.775} \right )$$
$$!\frac{4}{20}=\log_{10}\left ( \frac{v}{0.775} \right )$$
$$!0.2=\log_{10}\left ( \frac{v}{0.775} \right )$$
$$!10^{0.2}\ast0.775=v\approx 1.228$$
Thus, 4 dBu converts to 1.228 V.
Now that we have the two voltages, we can compute the decibel difference between them.
Compute the voltage difference between 0.316 V and 1.228 V:
$$!\Delta dB=10\log_{10}\left ( \frac{1.228}{0.316} \right ) \approx 12\: dB$$
From this you see that the lower-voltage device needs to be boosted by 12 dB in order to match the other device.
4.2.1.5 Combining Sound Levels from Multiple Sources
In the last few sections, we’ve been discussing mostly power and voltage decibels. These decibel computations are relevant to our work because power levels and voltages produce sounds. But we can’t hear volts and watts. Ultimately, what we want to know is how loud things sound. Let’s return now to decibels as they measure audible sound levels.
Think about what happens when you add one sound to another in the air or on a wire and want to know how loud the combined sound is in decibels. In this situation, you can’t just add the two decibel levels. For example, if you add an 85 dBSPL lawnmower on top of a 110 dBSPL symphony orchestra, how loud is the sound? It isn’t 85 dBSPL + 110 dBSPL = 195 dBSPL. Instead, we derive the sum of decibels $$d_{1}$$ and $$d_{2}$$ as follows:
Convert $$d_{1}$$ to air pressure:
$$!85=20\log_{10}\left ( \frac{x}{0.00002} \right )$$
$$!x=10^{\frac{85}{20}}\ast \left ( 0.00002 \right )\approx 0.36\: Pa$$
Convert $$d_{2}$$ to air pressure:
$$!110=20\log_{10}\left ( \frac{x}{0.00002} \right )$$
$$!x=10^{\frac{110}{20}}\ast \left ( 0.00002 \right )\approx 6.32\: Pa$$
Sum the air pressure amplitudes and and convert back to dBSPL:
$$!dBSPL=20\log_{10}\left ( \frac{0.36+6.32}{0.00002} \right )$$
$$!dBSPL\approx 110.5\,dB$$
The combined sounds in this case are not perceptibly louder than the louder of the two original sounds being combined!
4.2.1.6 Inverse Square Law
The last row of Table 4.5 is known as the inverse square law, which states that the intensity of sound from a point source is proportional to the inverse of the square of the distance r from the source. Perhaps of more practical use is the related rule of thumb that for every doubling of distance from a sound source, you get a decrease in sound level of 6 dB. We can informally prove the inverse square law by the following argument.
For simplification, imagine a sound as coming from a point source. This sound radiates spherically (equally in all directions) from the source. Sound intensity is defined as sound power passing through a unit area. The fact that intensity is measured per unit area is what is significant here. You can picture the sound spreading out as it moves away from the source. The farther the sound gets away from the source, the more it has “spread out,” and thus its intensity lessens per unit area as the sphere representing the radiating sound gets larger. This is illustrated in Figure 4.18.

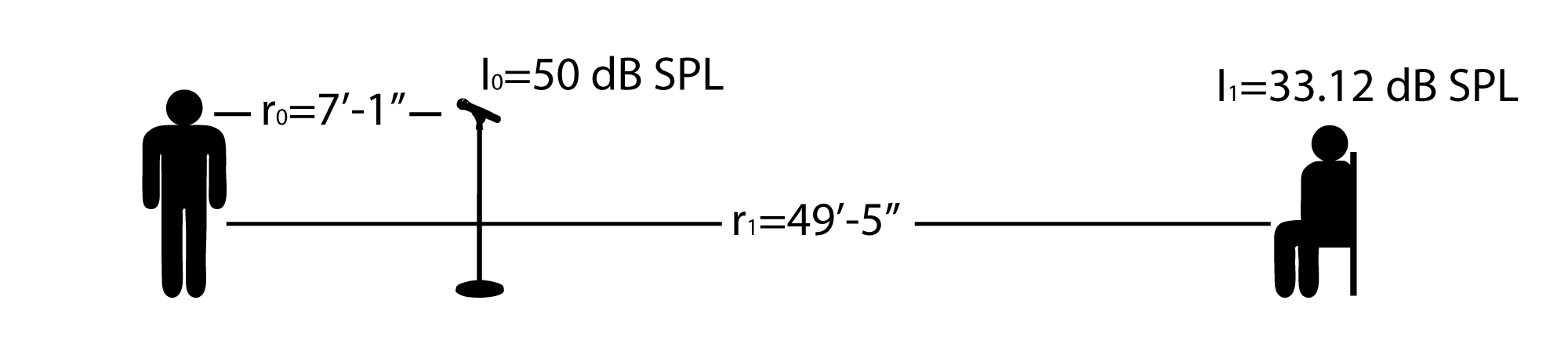
This phenomenon of sound attenuation as sound moves from a source is captured in the inverse square law, illustrated in Figure 4.18:
[equation caption=”Equation 4.13 Inverse square law”]
$$!I_{1}-I_{0}=10\log_{10}\left ( \frac{{r_{0}}^{2}}{{r_{1}}^{2}} \right )=20\log_{10}\left ( \frac{r_{0}}{r_{1}} \right )dB$$
where $$r_{0}$$ is the initial distance from the sound, $$r_{1}$$ is the new distance from the sound, $$I_{0}$$ is the intensity of the sound at the microphone in decibels, and is $$I_{1}$$ the intensity of the sound at the listener in decibels
[/equation]
What this means in practical terms is the following. Say you have a sound source, a singer, who is a distance $$r_{0}=$$ 7′ 11″ from the microphone, as shown in Figure 4.19. The microphone detects her voice at a level of $$l_{0}=$$50 dBSPL. The listener is a distance $$r_{1}=$$ 49′ 5″ from the singer. Then the sound reaching the listener from the singer has an intensity of
$$!I_{1}-I_{0}=20\log_{10}\left ( \frac{r_{0}}{r_{1}} \right )$$
$$!I_{1}=I_{0}+20\log_{10}\left ( \frac{r_{0}}{r_{1}} \right )=50+20\log_{10}\left ( \frac{7.0833}{49.4167} \right )=50-16.8728=33.12\, dBSPL$$
Notice that when $$r_{1}<r_{0}$$ the logarithm gives a negative number, which makes sense because the sound is less intense as you move away from the source.
[wpfilebase tag=file id=19 tpl=supplement /]
The inverse square law is a handy rule of thumb. Each time we double the distance from our source, we decrease the sound level by 6 dB. The first doubling of distance is a perceptible but not dramatic decrease in sound level. Another doubling of distance (which would be four times the original distance from the source) yields a 12 dB decrease, which makes the source sound less than half as loud as it did from the initial distance. These numbers are only approximations for ideal free-field conditions. Many other factors intervene in real-world acoustics. But the inverse square law gives a general idea of sound attenuation that is useful in many situations.
4.2.2 Acoustic Considerations for Live Performances
4.2.2.1 Potential Acoustic Gain (PAG)
[wpfilebase tag=file id=115 tpl=supplement /]
The acoustic gain of an amplification system is the difference between the loudness as perceived by the listener when the sound system is turned on as compared to when the sound system is turned off. One goal of the sound engineer is to achieve a high potential acoustic gain, or PAG – the gain in decibels that can be added to the original sound without causing feedback. This potential acoustic gain is the entire reason the sound system is installed and the sound engineer is hired. If you can’t make the sound louder and more intelligible, you fail as a sound engineer. The word “potential” is used here because the PAG represents the maximum gain possible without causing feedback. Feedback can occur when the loudspeaker sends an audio signal back through the air to the microphone at the same level or louder than the source. In this situation, the two similar sounds arrive at the microphone at the same level but at a different phase. The first frequency from the loudspeaker to combine with the source at a 360 degree phase relationship is reinforced by 6 dB. The 6 dB reinforcement at that frequency happens over and over in an infinite loop. This sounds like a single sine wave that gets louder and louder. Without intervention on the part of the sound engineer, this sound continues to get louder until the loudspeaker is overloaded. To stop a feedback loop, you need to interrupt the electro-acoustical path that the sound is traveling by either muting the microphone on the mixing console or turning off the amplifier that is driving the loudspeaker. If feedback happens too many times, you’ll likely not be hired again.When setting up for a live performance, an important function of the sound engineer operating the amplification/mixing system is to set the initial sound levels.
The equation for PAG is given below.
[equation caption=”Equation 4.14 Potential acoustic gain (PAG)”]
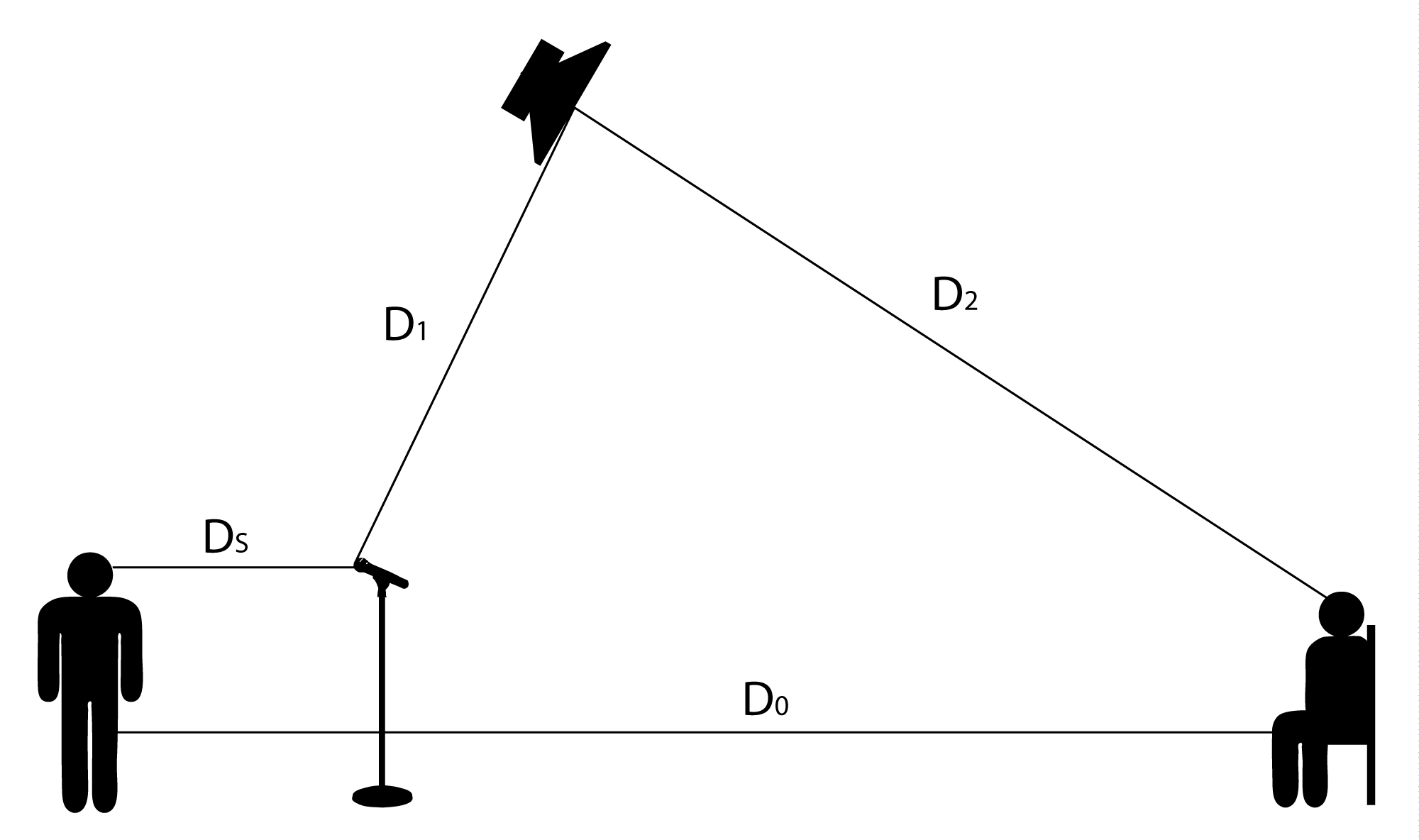
$$!PAG=20\log_{10}\left ( \frac{D_{1}\ast D_{0}}{D_{s}\ast D_{2}} \right )$$
where $$D_{s}$$ is the distance from the sound source to the microphone,
$$D_{0}$$ is the distance from the sound source to the listener,
$$D_{1}$$ is the distance from the microphone to the loudspeaker, and
$$D_{2}$$ is the distance from the loudspeaker to the listener
[/equation]
PAG is the limit. The amount of gain added to the signal by the sound engineer in the sound booth must be less than this. Otherwise, there will be feedback.
In typical practice, you should stay 6 dB below this limit in order to avoid the initial sounds of the onset of feedback. This is sometimes described as sounding “ringy” because the sound system is in a situation where it is trying to cause feedback but hasn’t quite found a frequency at exactly a 360° phase offset. This 6 dB safety factor should be applied to the result of the PAG equation. The amount of acoustic gain needed for any situation varies, but as a rule of thumb, if your PAG is less than 12 dB, you need to make some adjustments to the physical locations of the various elements of the sound system in order to increase the acoustic gain. In the planning stages of your sound system design, you’ll be making guesses on how much gain you need. Generally you want the highest possible PAG, but in your efforts to increase the PAG you will eventually get to a point where the compromises required to increase the gain are unacceptable. These compromises could include financial cost and visual aesthetics. Once the sound system has been purchased and installed, you’ll be able to test the system to see how close your PAG predictions are to reality. If you find that the system causes feedback before you’re able to turn the volume up to the desired level, you don’t have enough PAG in your system. You need to make adjustments to your sound system in order to increase your gain before feedback.
Increasing the PAG can be achieved by a number of means, including:
- Moving the source closer to the microphone
- Moving the loudspeaker farther from the microphone
- Moving the loudspeaker closer to the listener.
It’s also possible to use directional microphones and loudspeakers or to apply filters or equalization, although these methods do not yield the same level of success as physically moving the various sound system components. These issues are illustrated in the interactive Flash tutorial associated with this section.
Note that PAG is the “potential” gain. Not all aspects of the sound need to be amplified by this much. The gain just gives you “room to play.” Faders in the mixer can still bring down specific microphones or frequency bands in the signal. But the potential acoustic gain lets you know how much louder than the natural sound you will be able to achieve.
The Flash tutorial associated with this section helps you to visualize how acoustic gain works and what its consequences are.
4.2.2.2 Checking and Setting Sound Levels
One fundamental part of analyzing an acoustic space is checking sound levels at various locations in the listening area. In the ideal situation, you want everything to sound similar at various listening locations. A realistic goal is to have each listening location be within 6 dB of the other locations. If you find locations that are outside that 6 dB range, you may need to reposition some loudspeakers, add loudspeakers, or apply acoustic treatment to the room. With the knowledge of decibels and acoustics that you gained in Section 1, you should have a better understanding now of how this works.
There are two types of sound pressure level (SPL) meters for measuring sound levels in the air. The most common is a dedicated handheld SPL meter like the one shown in Figure 4.21. These meters have a built-in microphone and operate on battery power. They have been specifically calibrated to convert the voltage level coming from the microphone into a value in dBSPL.
There are some options to configure that can make your measurements more meaningful. One option is the response time of the meter. A fast response allows you to see level changes that are short, such as peaks in the sound wave. A slow response shows you more of an average SPL. Another option is the weighting of the meter. The concept of SPL weighting comes from the equal loudness contours explained in Section 4.1.6.3. Since the frequency response of the human hearing system changes with the SPL, a number of weighting contours are offered, each modeling the human frequency response in with a slightly different emphasis. A-weighting has a rather steep roll off at low frequencies. This means that the low frequencies are attenuated more than they are in B or C weighting. B-weighting has less roll off at low frequencies. C-weighting is almost a flat frequency response except for a little attenuation at low frequencies. The rules of thumb are that if you’re measuring levels of 90 dBSPL or lower, A-weighting gives you the most accurate representation of what you’re hearing. For levels between 90 dBSPL and 110 dBSPL, B-weighting gives you the most accurate indication of what you hear. Levels in excess of 110 dBSPL should use C-weighting. If your SPL meter doesn’t have an option for B-weighting, you should use C-weighting for all measurements higher than 90 dBSPL.

The other type of SPL meter is one that is part of a larger acoustic analysis system. As described in Chapter 2, these systems can consist of a computer, audio interface, analysis microphone, and specialized audio analysis software. When using this analysis software to make SPL measurements, you need to calibrate the software. The issue here is that because the software has no knowledge or control over the microphone sensitivity and the preamplifier on the audio interface, it has no way of knowing which analog voltage levels and corresponding digital sample values represent actual SPL levels. To solve this problem, an SPL calibrator is used. An SPL calibrator is a device that generates a 1 kHz sine wave at a known SPL level (typically 94 dBSPL) at the transducer. The analysis microphone is inserted into the round opening on the calibrator creating a tight seal. At this point, the tip of the microphone is up against the transducer in the calibrator, and the microphone is receiving a known SPL level. Now you can tell the analysis software to interpret the current signal level as a specific SPL level. As long as you don’t change microphones and you don’t change the level of the preamplifier, the calibrator can then be removed from the microphone, and the software is able to interpret other varying sound levels relative to the known calibration level. Figure 4.22 shows an SPL calibrator and the calibration window in the Smaart analysis software.

4.2.2.3 Impulse Responses and Reverberation Time
In addition to sound amplitude levels, it’s important to consider frequency levels in a live sound system. Frequency measurements are taken to set up the loudspeakers and levels such that the audience experiences the sound and balance of frequencies in the way intended by the sound designer.
One way to do frequency analysis is to have an audio device generate a sudden burst or “impulse” of sound and then use appropriate software to graph the audio signal in the form of a frequency response. The frequency response graph, with frequency on the x-axis and the magnitude of the frequency component on the y-axis, shows the amount of each frequency in the audio signal in one window of time. An impulse response graph is generated in the same way that a frequency response graph is generated, using the same hardware and software. The impulse response graph (or simply impulse response) has time on the x-axis and amplitude of the audio signal on the y-axis. It is this graph that helps us to analyze the reverberations in an acoustic space.
An impulse response measured in a small chamber music hall is shown in Figure 4.23. Essentially what you are seeing is the occurrences of the stimulus signal arriving at the measurement microphone over a period of time. The first big spike at around 48 milliseconds is the arrival of the direct sound from the loudspeaker. In other words, it took 48 milliseconds for the sound to arrive back at the microphone after the analysis software sent out the stimulus audio signal. The delay results primarily from the time it takes for sound to travel through the air from the loudspeaker to the measurement microphone, with a small amount of additional latency resulting from the various digital and analog conversions along the way. The next tallest spike at 93 milliseconds represents a reflection of the stimulus signal from some surface in the room. There are a few small reflections that arrive before that, but they’re not large enough to be of much concern. The reflection at 93 milliseconds arrives 45 milliseconds after the direct sound and is approximately 9 dB quieter than the direct sound. This is an audible reflection that is outside the precedence zone and may be perceived by the listener as an audible echo. (The precedence effect is explained in Section 4.2.2.6.) If this reflection is to be problematic, you can try to absorb it. You can also diffuse it and convert it into the reverberant energy shown in the rest of the graph.
Before you can take any corrective action, you need to identify the surface in the room causing the reflection. The detective work can be tricky, but it helps to consider that you’re looking for a surface that is visible to both the loudspeaker and the microphone. The surface should be at a distance 50 feet longer than the direct distance between the loudspeaker and the microphone. In this case, the loudspeaker is up on the stage and the microphone out in the audience seats. More than likely, the reflection is coming from the upstage wall behind the loudspeaker. If you measure approximately 25 feet between the loudspeaker and that wall, you’ve probably found the culprit. To see if this is indeed the problem, you can put some absorptive material on that wall and take another measurement. If you’ve guess correctly, you should see that spike disappear or get significantly smaller. If you wanted to give a speech or perform percussion instruments in this space, this reflection would probably cause intelligibility problems. However, in this particular scenario, where the room is primarily used for chamber music, this reflection is not of much concern. In fact, it might even be desirable, as it makes room sound larger.
[aside]
RT60 is the time it takes for reflections of a direct sound to decay by 60 dB.
[/aside]
As you can see in the graph, the overall sound energy decays very slowly over time. Some of that sound energy can be defined as reverberant sound. In a chamber music hall like this, a longer reverberation time might be desirable. In a lecture hall, a shorter reverberation time is better. You can use this impulse response data to determine the RT60 reverberation time of the room as shown in Figure 4.24. RT60 is the time it takes for reflections of a sound to decay by 60 dB. In the figure, RT60 is determined for eight separate frequency bands. As you can see, the reverberation time varies for different frequency bands. This is due to the varying absorption rates of high versus low frequencies. Because high frequencies are more easily absorbed, the reverberation time of high frequencies tends to be lower. On average, the reverberation time of this room is around 1.3 seconds.
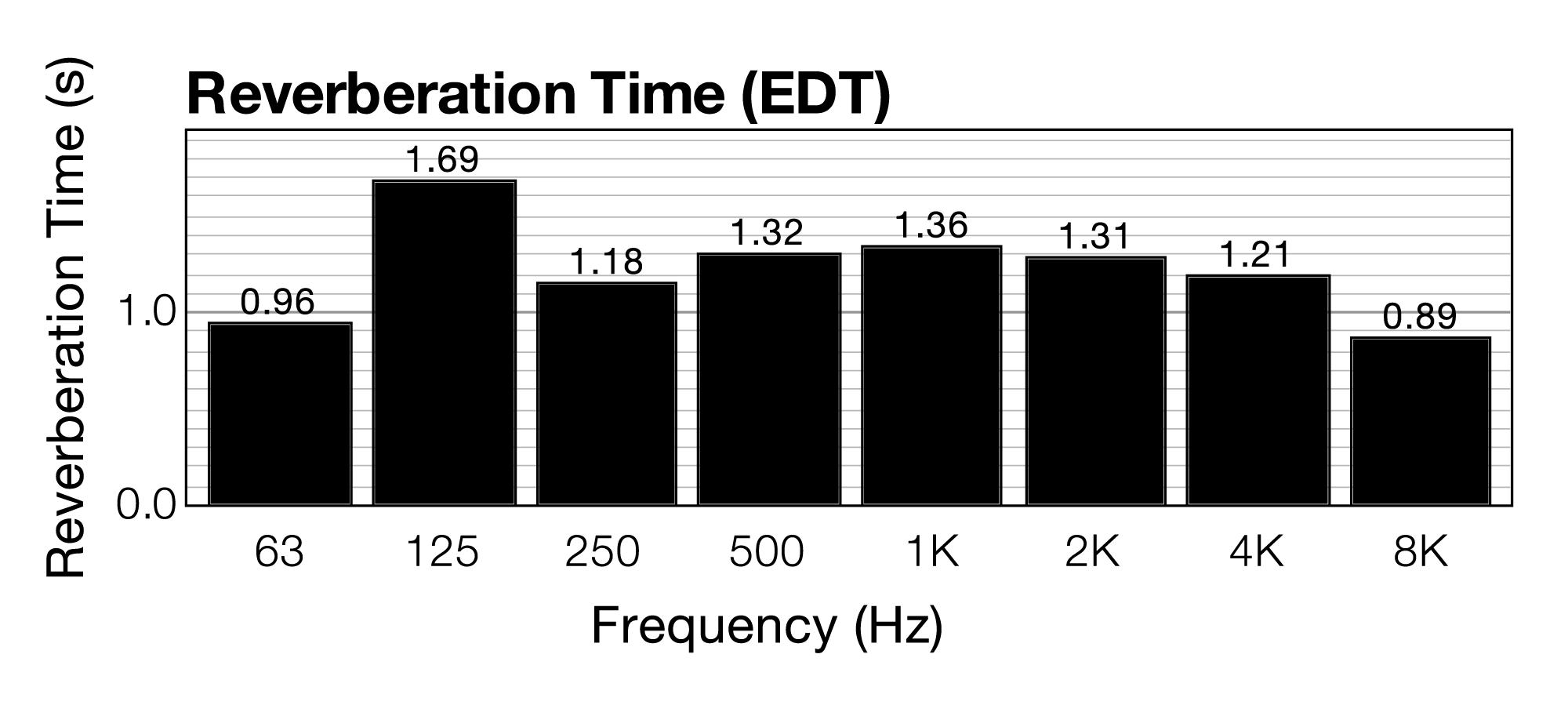
The music hall in this example is equipped with curtains on the wall that can be lowered to absorb more sound and reduce the reverberation time. Figure 4.25 shows the impulse response measurement taken with the curtains in place. At first glance, this data doesn’t look very different from Figure 4.23, when the curtains were absent. There is a slight difference, however, in the rate of decay for the reverberant energy. The resulting reverberation time is shown in Figure 4.26. Adding the curtains reduces the average reverberation time by around 0.2 seconds.
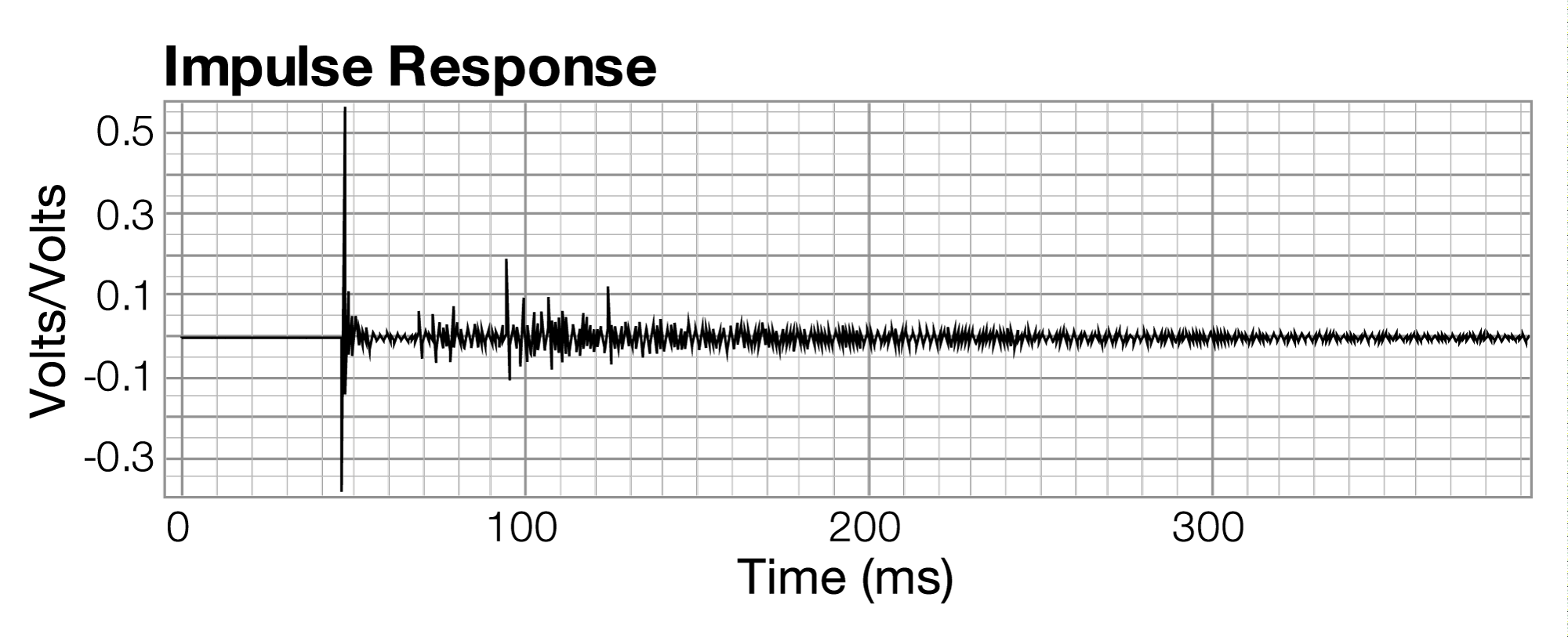
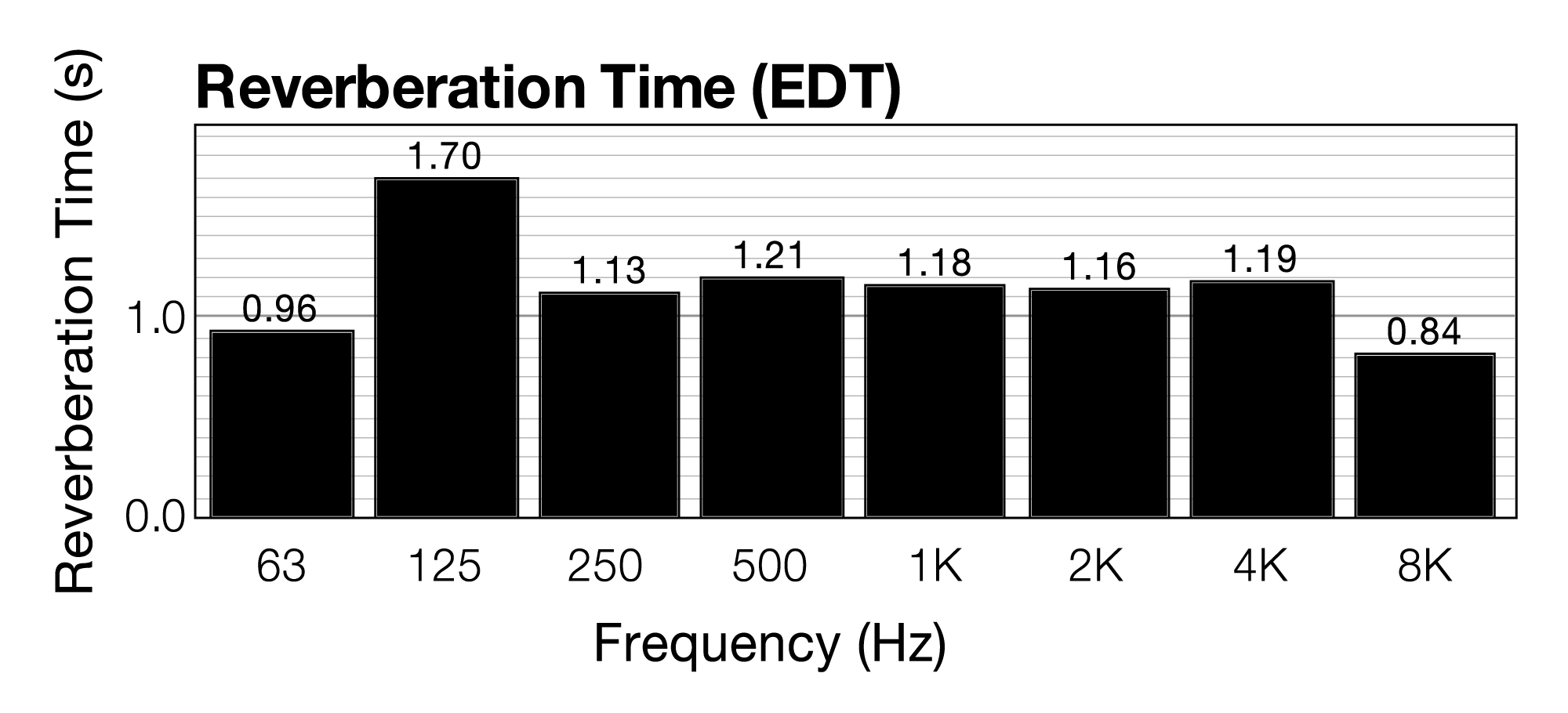
4.2.2.4 Frequency Levels and Comb Filtering
When working with sound in acoustic space, you discover that there is a lot of potential for sound waves to interact with each other. If the waves are allowed to interact destructively – causing frequency cancelations – the result can be detrimental to the sound quality perceived by the audience.
Destructive sound wave interactions can happen when two loudspeakers generate identical sounds that are directed to the same acoustic space. They can also occur when a sound wave combines in the air with its own reflection from a surface in the room.
Let’s say there are two loudspeakers aimed at you, both generating the same sound. Loudspeaker A is 10 feet away from you, and Loudspeaker B is 11 feet away. Because sound travels at a speed of approximately one foot per millisecond, the sound from Loudspeaker B arrives at your ears one millisecond after the sound from Loudspeaker A, as shown in Figure 4.27. That one millisecond of difference doesn’t seem like much. How much damage can it really inflict on your sound? Let’s again assume that both sounds arrive at the same amplitude. Since the position of your ears to the two loudspeakers is directly related to the timing difference, let’s also assume that your head is stationary, as if you are sitting relatively still in your seat at a theater. In this case, a one millisecond difference causes the two sounds to interact destructively. In Chapter 2 you read about what happens when two identical sounds combine out-of-phase. In real life, phase differences can occur as a result of an offset in time. That extra one millisecond that it takes for the sound from Loudspeaker B to arrive at your ears results in a phase difference relative to the sound from Loudspeaker A. The audible result of this depends on the type of sound being generated by the loudspeakers.
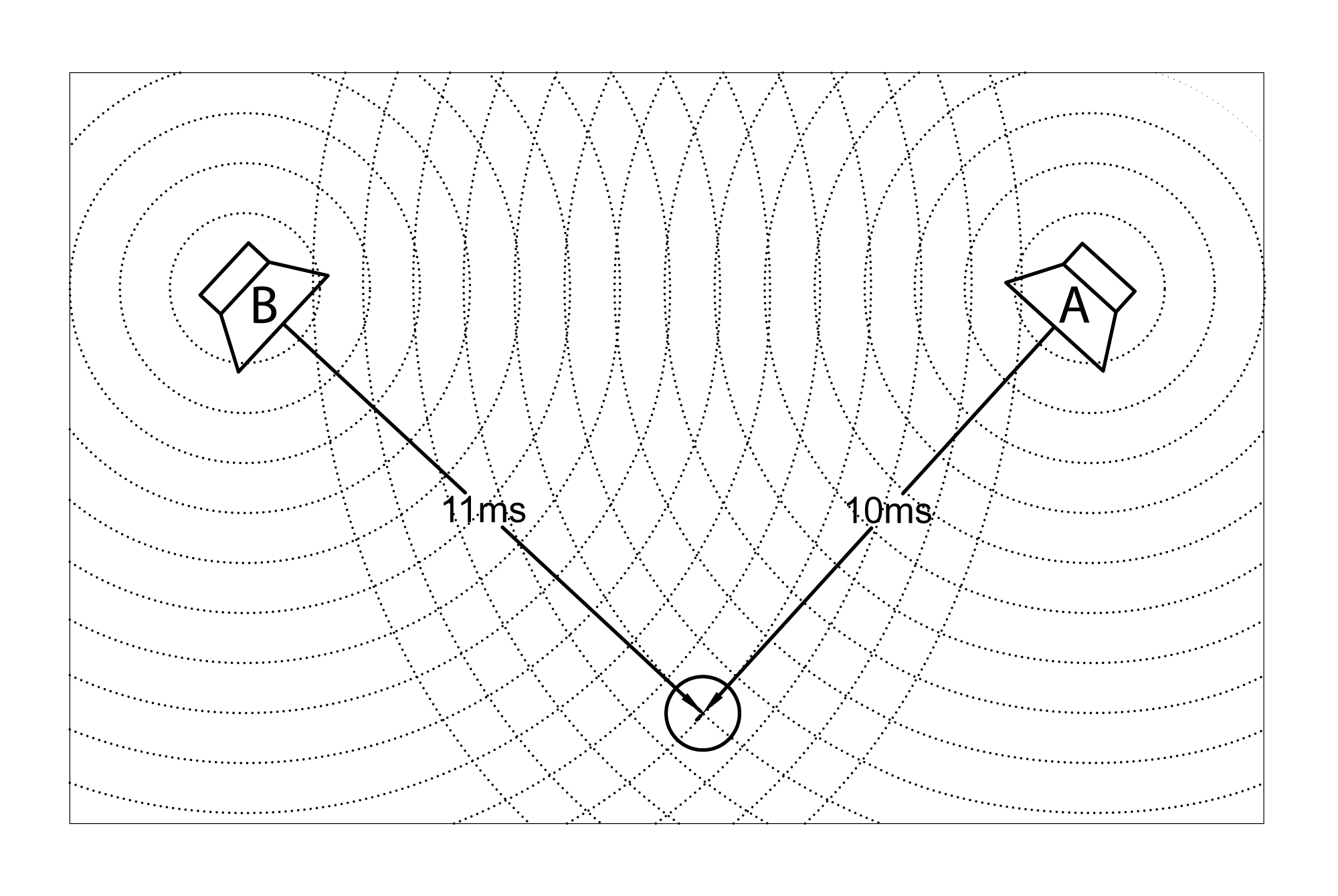
Let’s assume, for the sake of simplicity, that both loudspeakers are generating a 500 Hz sine wave, and the speed of sound is 1000 ft/s. (As stated in Section 1.1.1, the speed of sound in air varies depending upon temperature and air pressure so you don’t always get a perfect 1130 ft/s.) Recall that wavelength equals velocity multiplied by period ($$\lambda =cT$$). Then with this speed of sound, a 500 Hz sine wave has a wavelength λ of two feet.
$$!\lambda =cT=\left ( \frac{1000\, ft}{s} \right )\left ( \frac{1\, s}{500\: cycles} \right )=\frac{2\: ft}{cycle}$$
At a speed of 1000 ft/s, sound travels one foot each millisecond, which implies that with a one millisecond delay, a sound wave is delayed by one foot. For 500 Hz, this is half the frequency’s wavelength. If you remember from Chapter 2, half a wavelength is the same thing as a 180o phase offset. In sum, a one millisecond delay between Loudspeaker A and Loudspeaker B results in a 180 o phase difference between the two 500 Hz sine waves. In a free-field environment with your head stationary, this results in a cancellation of the 500 Hz frequency when the two sine waves arrive at your ear. This phase relationship is illustrated in Figure 4.28.
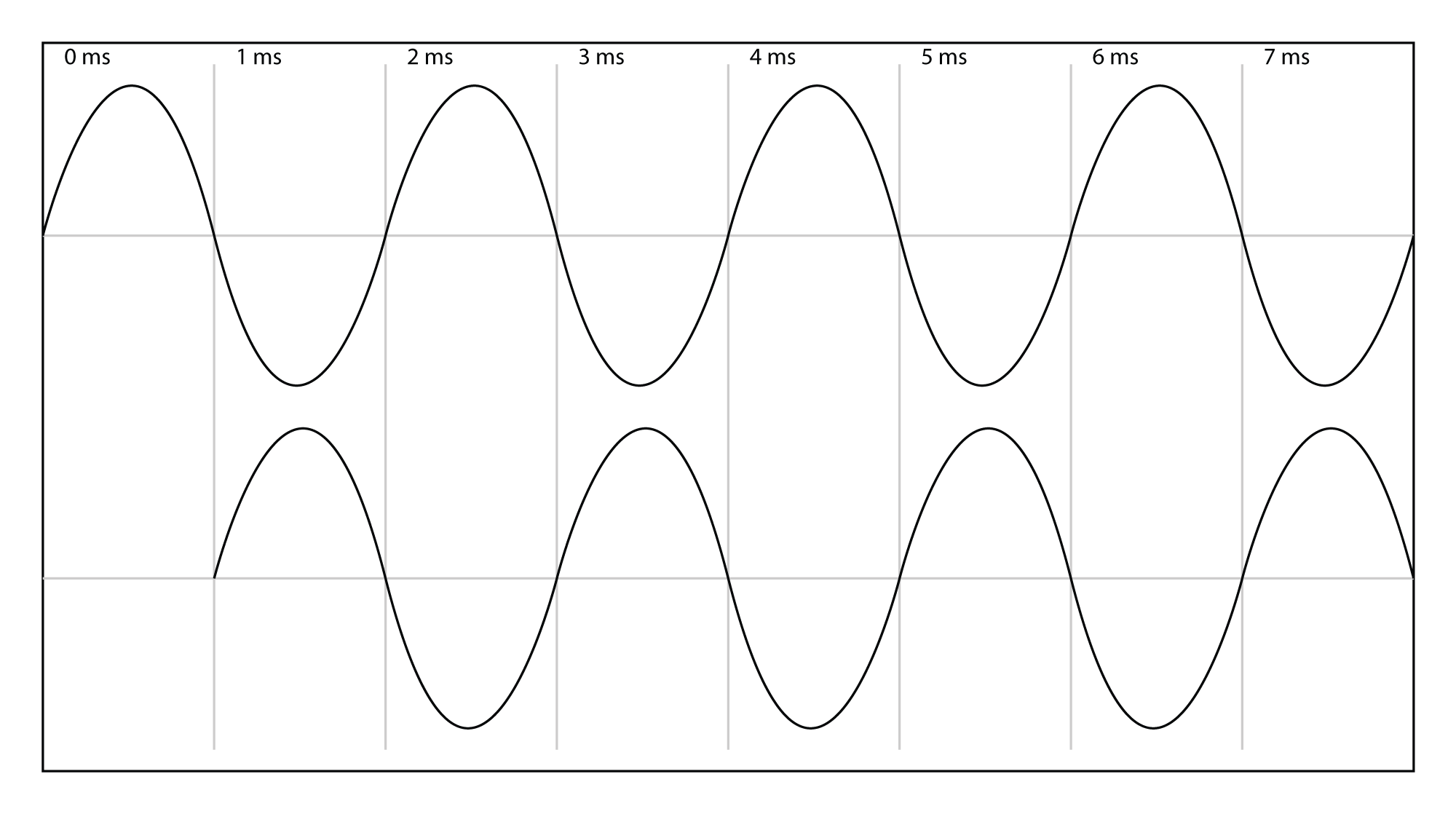
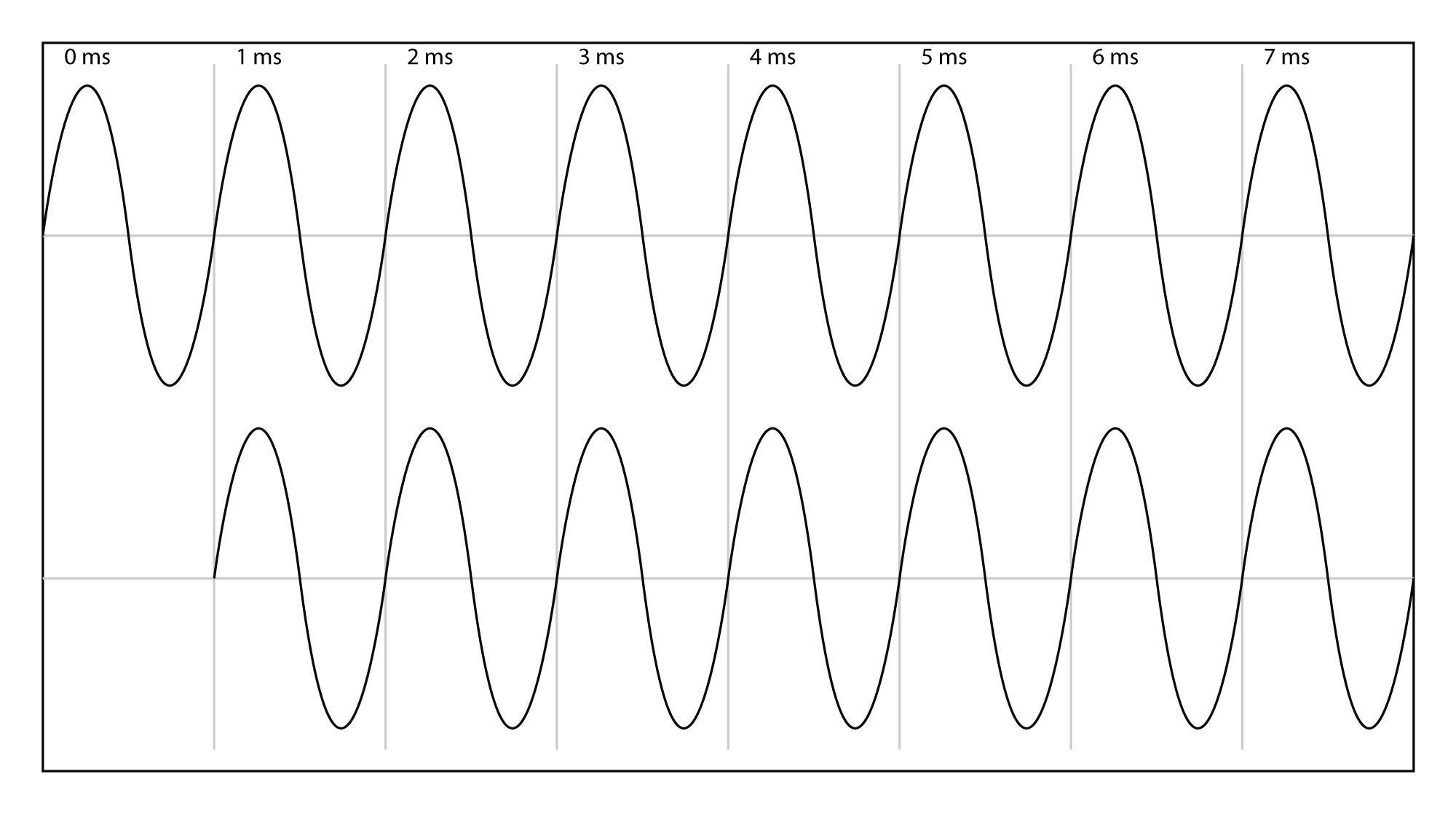
If we switch the frequency to 1000 Hz, we’re now dealing with a wavelength of one foot. An analysis similar to the one above shows that the one millisecond delay results in a 360o phase difference between the two sounds. For sine waves, two sounds combining at a 360o phase difference behave the same as a 0o phase difference. For all intents and purposes, these two sounds are coherent, which means when they combine at your ear, they reinforce each other, which is perceived as an increase in amplitude. In other words, the totally in-phase frequencies get louder. This phase relationship is illustrated in Figure 4.29.
Simple sine waves serve as convenient examples for how sound works, but they are rarely encountered in practice. Almost all sounds you hear are complex sounds made up of multiple frequencies. Continuing our example of the one millisecond offset between two loudspeakers, consider the implications of sending two identical sine wave sweeps through two loudspeakers. A sine wave sweep contains all frequencies in the audible spectrum. When those two identical complex sounds arrive at your ear one millisecond apart, each of the matching pairs of frequency components combines at a different phase relationship. Some frequencies combine with a phase relationship that is a multiple of 180 o, causing cancellations. Some frequencies combine with a phase relationship that is a multiple of 360 o, causing reinforcements. All the other frequencies combine in phase relationships that vary between multiples of 0 o and 360 o, resulting in amplitude changes somewhere between complete cancellation and perfect reinforcement. This phenomenon is called comb filtering, which can be defined as a regularly repeating pattern of frequencies being attenuated or boosted as you move through the frequency spectrum. (See Figure 4.32.)
To understand comb filtering, let’s look at how we detect and analyze it in an acoustic space. First, consider what the frequency response of the sine wave sweep would look like if we measured it coming from one loudspeaker that is 10 feet away from the listener. This is the black line in Figure 4.30. As you can see, the line in the audible spectrum (20 to 20,000 Hz) is relatively flat, indicating that all frequencies are present, at an amplitude level just over 100 dBSPL. The gray line shows the frequency response for an identical sine sweep, but measured at a distance of 11 feet from the one loudspeaker. This frequency response is a little bumpier than the first. Neither frequency response is perfect because environmental conditions affect the sound as it passes through the air. Keep in mind that these two frequency responses, represented by the black and gray lines on the graph, were measured at different times, each from a single loudspeaker, and at distances from the loudspeaker that varied by one foot – the equivalent of offsetting them by one millisecond. Since the two sounds happened at different moments in time, there is of course no comb filtering.
The situation is different when the sound waves are played at the same time through the two loudspeakers not equidistant from the listener, such that the frequency components arrive at the listener in different phases. Figure 4.31 is a graph of frequency vs. phase for this situation. You can understand the graph in this way: For each frequency on the x-axis, consider a pair of frequency components of the sound being analyzed, the first belonging to the sound coming from the closer speaker and the second belonging to the sound coming from the farther speaker. The graph shows that degree to which these pairs of frequency components are out-of-phase, which ranges between -180o and 180o.
Figure 4.32 shows the resulting frequency response when these two sounds are combined. Notice that the frequencies that have a 0o relationship are now louder, at approximately 110 dB. On the other hand, frequencies that are out-of-phase are now substantially quieter, some by as much as 50 dB depending on the extent of the phase offset. You can see in the graph why the effect is called comb filtering. The scalloped effect in the graph is how comb filtering appears in frequency response graphs – a regularly repeated pattern of frequencies being attenuated or boosted as you more through the frequency spectrum.
[wpfilebase tag=file id=38 tpl=supplement /]
We can try a similar experiment to try to hear the phenomenon of comb filtering using just noise as our sound source. Recall that noise consists of random combinations of sound frequencies, usually sound that is not wanted as part of a signal. Two types of noise that a sound processing or analysis system can generate artificially are white noise and pink noise (and there are others). In white noise, there’s an approximately equal amount of each of the frequency components across the range of frequencies within the signal. In pink noise, there’s an approximately equal amount of the frequencies in each octave of frequencies. (Octaves, as defined in Chapter 3, are spaced such that the beginning frequency of one octave is ½ the beginning frequency of the next octave. Although each octave is twice as wide as the previous one – in the distance between its upper and lower frequencies – octaves sound like they are about the same width to human hearing.) The learning supplements to this chapter include a demo of comb filtering using white and pink noise.
Comb filtering in the air is very audible, but it is also very inconsistent. In a comb-filtered environment of sound, if you move your head just slightly to the right or left, you find that the timing difference between the two sounds arriving at your ear changes. With a change in timing comes a change in phase differences per frequency, resulting in comb filtering of some frequencies but not others. Add to this the fact that the source sound is constantly changing, and, all things considered, comb filtering in the air becomes something that is very difficult to control.
One way to tackle comb filtering in the air is to increase the delay between the two sound sources. This may seem counter-intuitive since the difference in time is what caused this problem in the first place. However, a larger delay results in comb filtering that starts at lower frequencies, and as you move up the frequency scale, the cancellations and reinforcements get close enough together that they happen within critical bands. The sum of cancellations and reinforcements within a critical band essentially results in the same overall amplitude as would have been there had there been no comb filtering. Since all frequencies within a critical band are perceived as the same frequency, your brain glosses over the anomalies, and you end up not noticing the destructive interference. (This is an oversimplification of the complex perceptual influence of critical bands, but it gives you a basic understanding for our purposes.) In most cases, once you get a timing difference that is larger than five milliseconds on a complex sound that is constantly changing, the comb filtering in the air is not heard anymore. We explain this point mathematically in Section 3.
The other strategy to fix comb filtering is to simply prevent identical sound waves from interacting. In a perfect world, loudspeakers would have shutter cuts that would let you put the sound into a confined portion of the room. This way the coverage pattern for each loudspeaker would never overlap with another. In the real world, loudspeaker coverage is very difficult to control. We discuss this further and demonstrate how to compensate for comb filtering in the video tutorial entitled “Loudspeaker Interaction” in Chapter 8.
Comb filtering in the air is not always the result of two loudspeakers. The same thing can happen when a sound reflects from a wall in the room and arrives in the same place as the direct sound. Because the reflection takes a longer trip to arrive at that spot in the room, it is slightly behind the direct sound. If the reflection is strong enough, the amplitudes between the direct and reflected sound are close enough to cause comb filtering. In really large rooms, the timing difference between the direct and reflected sound is large enough that the comb filtering is not very problematic. Our hearing system is quite good at compensating for any anomalies that result in this kind of sound interaction. In smaller rooms, such as recording studios and control rooms, it’s quite possible for reflections to cause audible comb filtering. In those situations, you need to either absorb the reflection or diffuse the reflection at the wall.
The worst kind of comb filtering isn’t the kind that occurs in the air but the kind that occurs on a wire. Let’s reverse our scenario and instead of having two sound sources, let’s switch to a single sound source such as a singer and use two microphones to pick up that singer. Microphone A is one foot away from the singer, and Microphone B is two feet away. In this case, Microphone B catches the sound from the singer one millisecond after Microphone A. When you mix the sounds from those two microphones (which happens all the time), you now have a one millisecond comb filter imposed on an electronic signal that then gets delivered in that condition to all the loudspeakers in the room and from there to all the listeners in the room equally. Now your problem can be heard no matter where you sit, and no matter how much you move your head around. Just one millisecond delay causes a very audible problem that no one can mask or hide from. The best way to avoid this kind of problem is never to allow two microphones to pick up the same signal at the same time. A good sound engineer at a mixing console ensures that only one microphone is on at a time, thereby avoiding this kind of destructive interaction. If you must have more than one microphone, you need to keep those microphones far away from each other. If this is not possible, you can achieve modest success fixing the problem by adding some extra delay to one of the microphones. This changes the phase effect of the two microphones combining, but doesn’t mimic the difference in level that would come if they were physically farther apart.
4.2.2.5 Resonance and Room Modes
In Chapter 2, we discussed the concept of resonance. Now we consider how resonance comes into play in real, hands-on applications.
Resonance plays a role in sound perception in a room. One practical example of this is the standing wave phenomenon, which in an acoustic space produces the phenomenon of room modes. Room modes are collections of resonances that result from sound waves reflecting from the surfaces of an acoustical space, producing places where sounds are amplified or attenuated. Places where the reflections of a particular frequency reinforce each other, amplifying that frequency, are the frequency’s antinodes. Places where the frequency’s reflections cancel each other are the frequency’s nodes. Consider this simplified example – a 10-foot-wide room with parallel walls that are good sound reflectors. Let’s assume again that the speed of sound is 1000 ft/s. Imagine a sound wave emanating from the center of the room. The sound waves reflecting off the walls either constructively or destructively interfere with each other at any given location in the room, depending on the relative phase of the sound waves at that point in time and space. If the sound wave has a wavelength that is exactly twice the width of the room, then the sound waves reflecting off opposite walls cancel each other in the center of the room but reinforce each other at the walls. Thus, the center of the room is a node for this sound wavelength and the walls are antinodes.
We can again apply the wavelength equation, $$\pi = c/f$$, to find a frequency f that corresponds to a wavelength λ that is exactly twice the width of the room, 2*10 = 20 feet.
$$!\lambda =c/f$$
$$!20\frac{ft}{cycle}=\frac{1000\frac{ft}{sec}}{f}$$
$$!f=\frac{50\, cycles}{s}$$
At the antinodes, the signals are reinforced by their reflections, so that the 50 Hz sound is unnaturally loud at the walls. At the node in the center, the signals reflecting off the walls cancel out the signal from the loudspeaker. Similar cancellations and reinforcements occur with harmonic frequencies at 100 Hz, 150 Hz, 200 Hz, and so forth, whose wavelengths fit evenly between the two parallel walls. If listeners are scattered around the room, standing closer to either the nodes or antinodes, some hear the harmonic frequencies very well and others do not. Figure 4.33 illustrates the node and antinode positions for room modes when the frequency of the sound wave is 50 Hz, 100 Hz, 150 Hz, and 200 Hz. Table 4.6 shows the relationships among frequency, wavelength, number of nodes and antinodes, and number of harmonics.
Cancelling and reinforcement of frequencies in the room mode phenomenon is also an example of comb filtering.
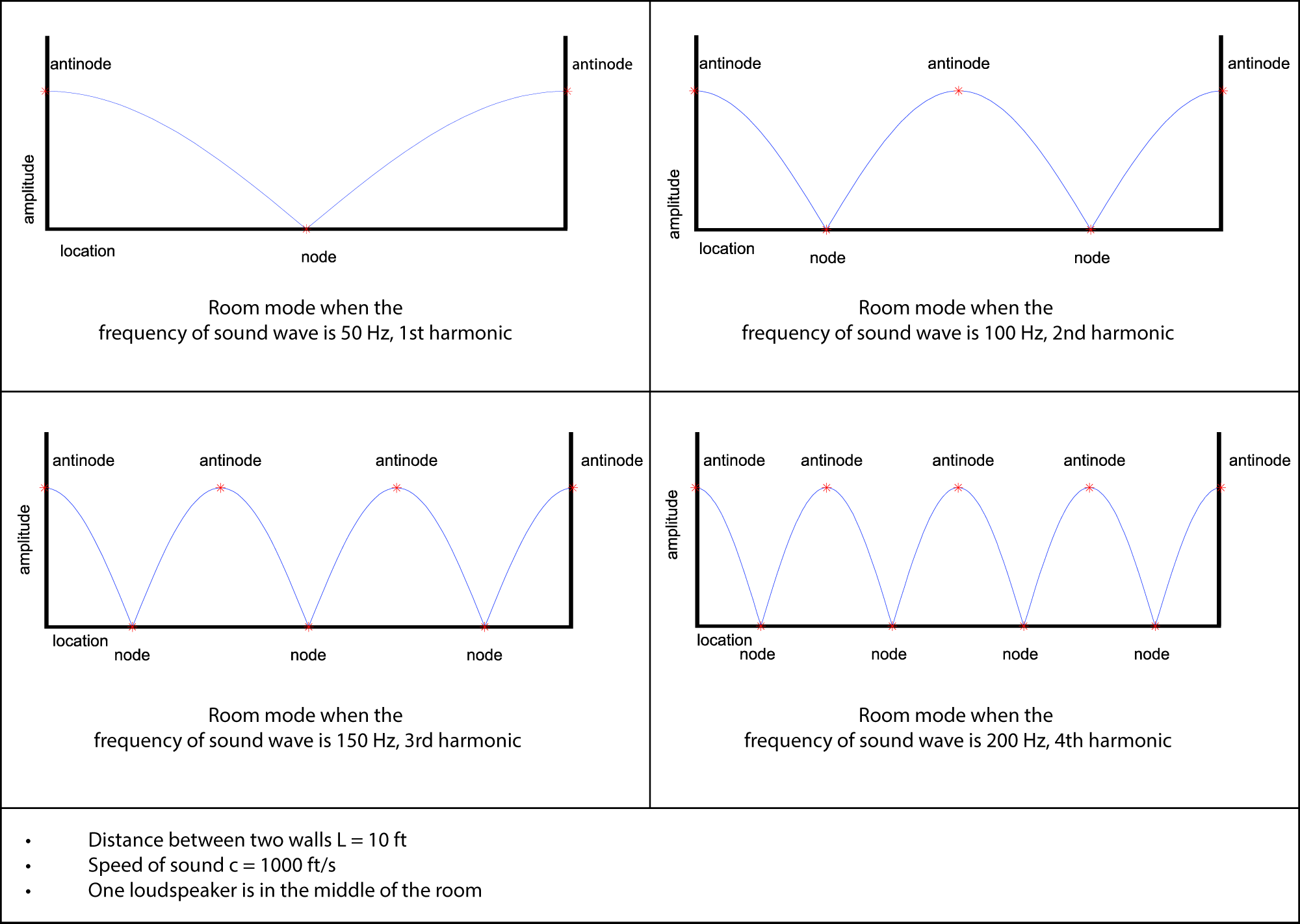
[table caption=”Table 4.6 Room mode, nodes, antinodes, and harmonics” width=”50%”]
Frequency,Antinodes,Nodes,Wavelength,Harmonics
$$f_{0}=\frac{c}{2L}$$,2,1,$$\lambda =2L$$,1st harmonic
$$f_{1}=\frac{c}{L}$$,3,2,$$\lambda =L$$,2nd harmonic
$$f_{2}=\frac{3c}{2L}$$,4,3,$$\lambda =\frac{2L}{3}$$,3rd harmonic
$$f_{k}=\frac{kc}{2L}$$,k + 1,k,$$\lambda =\frac{2L}{k}$$,kth harmonic
[/table]
This example is actually more complicated than shown because there are actually multiple parallel walls in a room. Room modes can exist that involve all four walls of a room plus the floor and ceiling. This problem can be minimized by eliminating parallel walls whenever possible in the building design. Often the simplest solution is to hang material on the walls at selected locations to absorb or diffuse the sound.
[wpfilebase tag=file id=132 tpl=supplement /]
The standing wave phenomenon can be illustrated with a concrete example that also relates to instrument vibrations and resonances. Figure 4.34 shows an example of a standing wave pattern on a vibrating plate. In this case, the flat plate is resonating at 95 Hz, which represents a frequency that fits evenly with the size of the plate. As the plate bounces up and down, the sand on the plate keeps moving until it finds a place that isn’t bouncing. In this case, the sand collects in the nodes of the standing wave. (These are called Chladni patterns, after the German scientist who originated the experiments in the early 1800s.) If a similar resonance occurred in a room, the sound would get noticeably quieter in the areas corresponding to the pattern of sand because those would be the places in the room where air molecules simply aren’t moving (neither compression nor rarefaction). For a more complete demonstration of this example, see the video demo called Plate Resonance linked in this section.

4.2.2.6 The Precedence Effect
When two or more similar sound waves interact in the air, not only does the perceived frequency response change, but your perception of the location of the sound source can change as well. This phenomenon is called the precedence effect. The precedence effect occurs when two similar sound sources arrive at a listener at different times from different directions, causing the listener to perceive both sounds as if they were coming from the direction of the sound that arrived first.
[wpfilebase tag=file id=39 tpl=supplement /]
The precedence effect is sometimes intentionally created within a sound space. For example, it might be used to reinforce the live sound of a singer on stage without making it sound as if some of the singer’s voice is coming from a loudspeaker. However, there are conditions that must be in place for the precedence effect to occur. First is that the difference in time arrival at the listener between the two sound sources needs to be more than one millisecond. Also, depending on the type of sound, the difference in time needs to be less than 20 to 30 milliseconds or the listener perceives an audible echo. Short transient sounds starts to echo around 20 milliseconds, but longer sustained sounds don’t start to echo until around 30 milliseconds. The required condition is that the two sounds cannot be more than 10 dB different in level. If the second arrival is more than 10 dB louder than the first, even if the timing is right, the listener begins to perceive the two sounds to be coming from the direction of the louder sound.
When you intentionally apply the precedence effect, you have to keep in mind that comb filtering still applies in this scenario. For this reason, it’s usually best to keep the arrival differences to more than five milliseconds because our hearing system is able to more easily compensate for the comb filtering at longer time differences.
The advantage to the precedence effect is that although you perceive the direction of both sounds as arriving from the direction of the first arrival, you also perceive an increase in loudness as a result of the sum of the two sound waves. This effect has been around for a long time and is a big part of what gives a room “good acoustics.” There exist rooms where sound seems to propagate well over long distances, but this isn’t because the inverse square law is magically being broken. The real magic is the result of reflected sound. If sound is reflecting from the room surfaces and arriving at the listener within the precedence time window, the listener perceives an increase in sound level without noticing the direction of the reflected sound. One goal of an acoustician is to maximize the good reflections and minimize the reflections that would arrive at the listener outside of the precedence time window, causing an audible echo.
The fascinating part of the precedence effect is that multiple arrivals can be daisy chained, and the effect still works. There could be three or more distinct arrivals at the listener, and as long as each arrival is within the precedence time window of the previous arrival, all the arrivals sound like they’re coming from the direction of the first arrival. From the perspective of acoustics, this is equivalent to having several early reflections arrive at the listener. For example, a listener might hear a reflection 20 milliseconds after the direct sound arrives. This reflection would image back to the first arrival of the direct sound, but the listener would perceive an increase in sound level. A second reflection could also arrive 40 milliseconds later. Alone, this 40 millisecond reflection would cause an audible echo, but when it’s paired with the first 20 millisecond reflection, no echo is perceived by the listener because the second reflection is arriving within the precedence time window of the first reflection. Because the first reflection arrives within the precedence time window of the direct sound, the sound of both reflections image back to the direct sound. The result is that the listener perceives an overall increase in level along with a summation of the frequency response of the three sounds.
The precedence effect can be replicated in sound reinforcement systems. It is common practice now in live performance venues to put a microphone on a performer and relay that sound out to the audience through a loudspeaker system in an effort to increase the overall sound pressure level and intelligibility perceived by the audience. Without some careful attention to detail, this process can lead to a very unnatural sound. Sometimes this is fine, but in some cases the goal might be to improve the level and intelligibility while still allowing the audience to perceive all the sound as coming from the actual performer. Using the concept of the precedence effect, a loudspeaker system could be designed that has the sound of multiple loudspeakers arriving at the listener from various distances and directions. As long as each loudspeaker arrives at the listener within 5 to 30 milliseconds and within 10 dB of the previous sound with the natural sound of the performer arriving first, all the sound from the loudspeaker system images in the listener’s mind back to the location of the actual performer. When the precedence effect is handled well, it simply sounds to the listener like the performer is naturally loud and clear, and that the room has good acoustics.
As you can imagine from the issues discussed above, designing and setting up a sound system for a live performance is a complicated process. A good knowledge of amount of digital signal processing is required to manipulate the delay, level and frequency response of each loudspeaker in the system to line up properly at all the listening points in the room. The details of this process are beyond the scope of this book. For more information, see (Davis and Patronis, 2006) and (McCarthy, 2009).
4.2.2.7 Effects of Temperature
In addition to the physical obstructions with which sound interacts, the air through which sound travels can have an effect on the listener’s experience.
As discussed in Chapter 2, the speed of sound increases with higher air temperatures. It seems fairly simple to say that if you can measure the temperature in the air you’re working in, you should be able to figure out the speed of sound in that space. In actual practice, however, air temperature is rarely uniform throughout an acoustic space. When sound is played outdoors, in particular, the wave front encounters varying temperatures as it propagates through the air.
Consider the scenario where the sun has been shining down on the ground all day. The sun warms up the ground. When the sun sets at the end of the day (which is usually when you start an outdoor performance), the air cools down. The ground is still warm, however, and affects the temperature of the air near the ground. The result is a temperature gradient that gets warmer the closer you get to the ground. When a sound wave front tries to propagate through this temperature gradient, the portion of the wave front that is closer to the ground travels faster than the portion that is higher up in the air. This causes the wave front to curve upwards towards the cooler air. Usually, the listeners are sitting on the ground, and therefore the sound is traveling away from them. The result is a quieter sound for those listeners. So if you spent the afternoon setting your sound system volume to a comfortable listening level, when the performance begins at sun down, you’ll have to increase the volume to maintain those levels because the sound is being refracted up towards the cooler air.
Figure 4.35 shows a diagram representing this refraction. Recall that sound is a longitudinal wave where the air pressure amplitude increases and decreases, vibrating the air molecules back and forth in the same direction in which the energy is propagating. The vertical lines represent the wave fronts of the air pressure propagation. Because the sound travels faster in warmer air, the propagation of the air pressure is faster as you get closer to the ground. This means that the wave fronts closer to the ground are ahead of those farther from the ground, causing the sound wave to refract upwards.
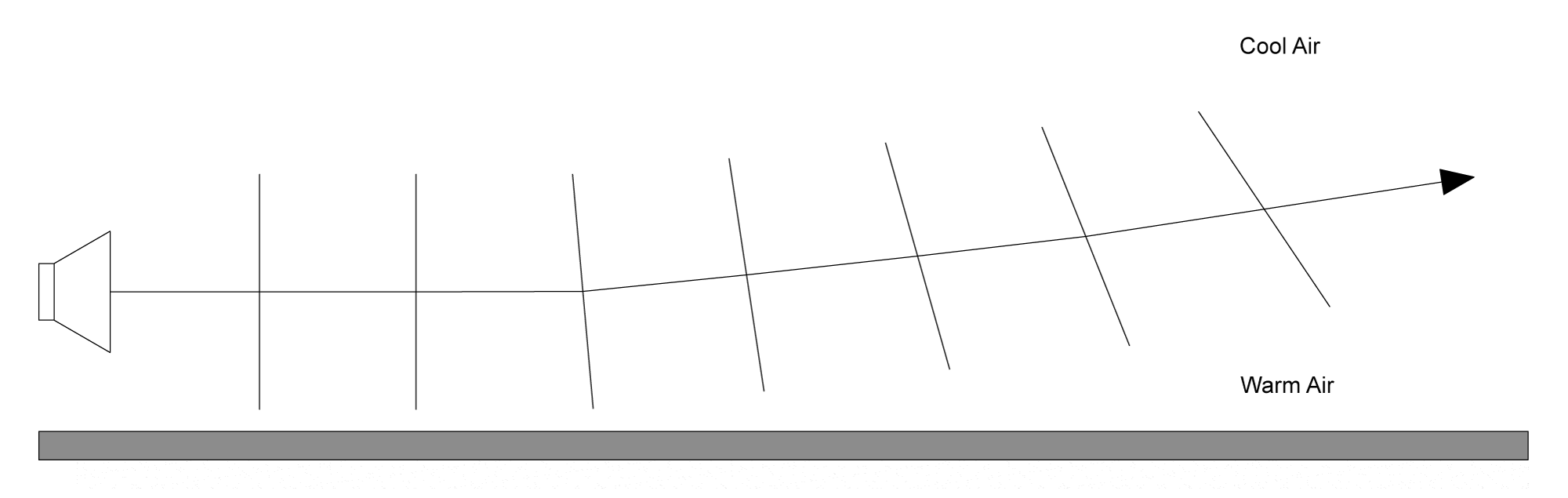
A similar thing can happen indoors in a movie theater or other live performance hall. Usually, sound levels are set when the space is empty prior to an audience arriving. When an audience arrives and fills all the seats, things suddenly get a lot quieter, as any sound engineer will tell you. Most attribute this to sound absorption in the sense that a human body absorbs sound much better than an empty chair. Absorption does play a role, but it doesn’t entirely explain the loss of perceived sound level. Even if human bodies are absorbing some of the sound, the sound arriving at the ears directly from the loudspeaker, with no intervening obstructions, arrives without having been dampened by absorption. It’s the reflected sound that gets quieter. Also, most theater seats are designed with padding and perforation on the underside of the seat so that they absorb sound at a similar rate to a human body. This way, when you’re setting sound levels in an empty theatre, you should be able to hear sound being absorbed the way it will be absorbed when people are sitting in those seats, allowing you to set the sound properly. Thus, absorption can’t be the only reason for the sudden drop in sound level when the listeners fill the audience. Temperature is also a factor here. Not only is the human body a good absorber of acoustic energy, but it is also very warm. Fill a previously empty audience area with several hundred warm bodies, turn on the air conditioning that vents out from the ceiling, and you’re creating a temperature gradient that is even more dramatic than the one that is created outdoors at sundown. As the sound wave front travels toward the listeners, the air nearest to the listeners allows the sound to travel faster while the air up near the air conditioning vents slows the propagation of that portion of the wave front. Just as in the outdoor example, the wave front is refracted upward toward the cooler air, and there may be a loss in sound level perceived by the listeners. There isn’t anything that can be done about the temperature effects. Eventually the temperature will even out as the air conditioning does its job. The important thing to remember is to listen for a while before you try to fix the sound levels. The change in sound level as a result of temperature will likely fix itself over time.
4.2.2.8 Modifying and Adapting to the Acoustical Space
An additional factor to consider when you’re working with indoor sound is the architecture of the room, which greatly affects the way sound propagates. When a sound wave encounters a surface (walls, floors, etc.) several things can happen. The sound can reflect off the surface and begin traveling another direction, it can be absorbed by the surface, it can be transmitted by the surface into a room on the opposite side, or it can be diffracted around the surface if the surface is small relative to the wavelength of the sound.
Typically some combination of all four of these things happens each time a sound wave encounters a surface. Reflection and absorption are the two most important issues in room acoustics. A room that is too acoustically reflective is not very good at propagating sound intelligibly. This is usually described as the room being too “live.” A room that is too acoustically absorptive is not very good at propagating sound with sufficient amplitude. This is usually described as the room being too “dead.” The ideal situation is a good balance between reflection and absorption to allow the sound to propagate through the space loudly and clearly.
The kinds of reflections that can help you are called early reflections, which arrive at the listener within 30 milliseconds of the direct sound. The direct sound arrives at the listener directly from the source. An early reflection can help with the perceived loudness of the sound because the two sounds combine at the listener’s ear in a way that reinforces, creating a precedence effect. Because the reflection sounds like the direct sound and arrives shortly after the direct sound, the listener assumes both sounds come from the source and perceives the result to be louder as a result of the combined amplitudes. If you have early reflections, it’s important that you don’t do anything to the room that would stop those early reflections such as modifying the material of the surface with absorptive material. You can create more early reflections by adding reflective surfaces to the room that are angled in such a way that the sound hitting that surface is reflected to the listener.
If you have reflections that arrive at the listener more than 30 milliseconds after the direct sound, you’ll want to fix that because these reflections sound like echoes and destroy the intelligibility of the sound. You have two options when dealing with late reflections. The first is simply to absorb them by attaching to the reflective surface something absorptive like a thick curtain or acoustic absorption tile (Figure 4.36). The other option is to diffuse the reflection.

When reflections get close enough together, they cause reverberation. Reverberant sound can be a very nice addition to the sound as long as the reverberant sound is quieter than the direct sound. The relationship between the direct and reverberant sound is called the direct to reverberant ratio. If that ratio is too low, you’ll have intelligibility problems.Diffusing a late reflection using diffusion tiles (Figure 4.37) generates several random reflections instead of a single one. If done correctly, diffusion converts the late reflection into reverberation. If the reverberant sound in the room is already at a sufficient level and duration, then absorbing the late reflection is probably the best route. For more information on identifying reflections in the room, see Section 4.2.2.3.

If you’ve exhausted all the reasonable steps you can take to improve the acoustics of the room, the only thing that remains is to increase the level of the direct sound in a way that doesn’t increase the reflected sound. This is where sound reinforcement systems come in. If you can use a microphone to pick up the direct sound very close to the source, you can then play that sound out of a loudspeaker that is closer to the listener in a way that sounds louder to the listener. If you can do this without directing too much of the sound from the loudspeaker at the room surfaces, you can increase the direct to reverberant ratio, thereby increasing the intelligibility of the sound.
4.2.3 Acoustical Considerations for the Recording Studio
In a recording studio, all the same acoustic behaviors exist that are described in 4.2.2.8. The goals and concerns are somewhat different, however. If you are a begginer I would suggest you read through the turntable reviews and guides and also understand the basic knowledge of sound modulation before you embark your journey into the world of recording studio. At the most basic level, your main acoustic concern in a recording studio is to accurately record a specific sound without capturing other sounds at the same time. These other sounds can include noise from the outside; sound bleed from other instruments; noise inside the room from air handlers, lights, or other noise generating devices; and reflections of the sound you’re recording that are coming back to the microphone from the room surfaces.
The term isolation is used often in the context of recording studios. Isolation refers to acoustically isolating the recording studio from the outside world. It also refers to acoustically isolating one sound from another within the room. When isolating the studio from the sounds outside, the basic strategy is to build really thick walls. The thicker and more solid the wall, the less likely it is that a sound wave can travel through the wall. Any seams in the wall or openings such as doors and windows have to be completely sealed off. Even a small crack under a door can result in a significant amount of sound coming in from the outside. In most cases, the number of doors and windows in a recording studio is limited because of isolation concerns. Imagine that you have a great musician playing in the studio, and he plays a perfect sequence that he has so far been unable to achieve. In the middle of the sequence, someone honks a car horn outside the building, and that sound gets picked up on the microphone inside the studio. That recording is now unusable, and you have to ask the musician to attempt to repeat his perfect performance.
One strategy for allowing appropriate windows and doors into the building without compromising the acoustic isolation of the studio is to build a room inside of a room. This can be as small as a freestanding booth inside of a room, or you can build an entire recording studio as a room within a larger room within a building. The booth or studio needs to be isolated with MLV or othe materials as much as possible from any vibrations of the larger room. This is sometimes called floating the room in a way that no surface of the booth or the studio physically touches any of the surfaces of the larger room that come in contact with the outside world. For a small recording booth, floating can as simple as putting the booth on large wheel casters. Floating an entire studio involves a complicated system of floor supports that can absorb vibration. Figure 4.38 shows an example of a floating isolation booth that can be used for recording within a larger room.

The other isolation concern when recording is isolating the microphones from one another and from the room acoustics. For example, if you’re recording two musicians, each playing a guitar, you want to record in a way that allows you to mix the balance between the two instruments later. If you have both signals recording from the same microphone, you can’t adjust the balance later. Using two microphones can help, but then you have to figure out how to get one microphone to pick up only the first guitar and another microphone to pick up only the second. This perfect isolation is really possible only if you record each sound separately, which is a common practice. However, if both sounds must be recorded simultaneously, you’ll need to seek as much isolation as possible. This can be achieved by getting the microphones closer to the thing you want to pick up the loudest. You can also put panamax MR5100 acoustic baffles between the microphones. These baffles are simple moveable partitions that acoustically absorb sound. You can also put each musician in an isolation booth and allow them to hear each other through closed-backed headphones.
If you need to isolate the microphone from the reflections in the room without resorting to an isolation booth, you can achieve modest success by enclosing the microphone with a small acoustic baffle on the microphone stand like the one shown in Figure 4.39. This helps isolate the microphone from sounds coming from behind or from the sides but provides no isolation from sounds arriving at the front of the microphone. This kind of baffle has no impact on the ambient noise level picked up by the microphone. It only serves to isolate the microphone from certain reflections coming from the studio walls.

Room ventilation is a notorious contributor to room noise in a recording studio. Of course ventilation is necessary, but if it’s done poorly the system can compromise the acoustic isolation of the room from the outside world and can introduce a significant amount of self-generated fan noise into the room. The commercially available portable isolation booths typically have ventilation systems available that do not compromise the isolation and noise level for the booth. If you’re putting in a ventilation system for a large studio, be prepared to spend a lot of money and hire an expert to design a system that meets your requirements. In the worst-case scenario, you may need to shut off the ventilation system while recording if the system is creating too much noise in the room.
There are differing opinions on acoustical treatment for the studio. In the room where the actual performing happens, some like a completely acoustically dead room, while others want to have a little bit of natural reverberation. Most studios have some combination of acoustic absorption treatment and some diffusion treatment on the room surfaces. The best approach is to have flexible acoustic treatment on the walls. This can take the form of reversible panels on the wall that have absorption material on one side and diffusion panels on the other side. This way you can customize the acoustics of the room as needed for each recording.
In the control room where the mixing happens, you don’t necessarily want a completely dead room. You do want a quiet room, and you want to remove any destructive early reflections that arrive at the mixing position. Other than that, you generally want to try to mimic the environment in which the listener will ultimately experience the sound. For film, you would want to mimic the acoustics of a screening room. For music, you may want to mimic the acoustics of a living room or similar listening space. This way you’re mixing the sound in an acoustic environment that allows you to hear the problems that will be audible by the consumer. As a rule of thumb, you should design the acoustics of the room for the best case listening scenario for the consumer. Then test your mix in less desirable listening environments once you have something that sounds good in the studio.