1.4 Basic Terminology
1.4.1 Analog vs. Digital
With the evolution of computer technology in the past 50 years, sound processing has become largely digital. Understanding the difference between analog and digital processes and phenomena is fundamental to working with sound.
The difference between analog and digital processes runs parallel to the difference between continuous and discrete number systems. The set of real numbers constitutes a continuous system, which can be thought of abstractly as an infinite line of continuously increasing numbers in one direction and decreasing numbers in the other. For any two points on the line (i.e., real numbers), an infinite number of points exist between them. This is not the case with discrete number systems, like the set of integers. No integers exist between 1 and 2. Consecutive integers are completely separate and distinct, which is the basic meaning of discrete.
Analog processes and phenomena are similar to continuous number systems. In a time-based analog phenomenon, one moment of the phenomenon is perceived or measured as moving continuously into the next. Physical devices can be engineered to behave in a continuous, analog manner. For example, a volume dial on a radio can be turned left or right continuously. The diaphragm inside a microphone can move continuously in response to changing air pressure, and the voltage sent down a wire can change continuously as it records the sound level. However, communicating continuous data to a computer is a problem. Computers “speak digital,” not analog. The word digital refers to things that are represented as discrete levels. In the case of computers, there are exactly two levels – like 0 and 1, or off and on. A two-level system is a binary system, encodable in a base 2 number system. In contrast to analog processes, digital processes measure a phenomenon as a sequence of discrete events encoded in binary.
[aside]One might think, intuitively, that all physical phenomena are inherently continuous and thus analog. But the question of whether the universe is essentially analog or digital is actually quite controversial among physicists and philosophers, a debate stimulated by the development of quantum mechanics. Many now view the universe as operating under a wave-particle duality and Heisenberg’s Uncertainty Principle. Related to this debate is the field of “string theory,” which the reader may find interesting.[/aside]
It could be argued that sound is an inherently analog phenomenon, the result of waves of changing air pressure that continuously reach our ears. However, to be communicated to a computer, the changes in air pressure must be captured as discrete events and communicated digitally. When sound has been encoded in the language that computers understand, powerful computer-based processing can be brought to bear on the sound for manipulation of frequency, dynamic range, phase, and every imaginable audio property. Thus, we have the advent of digital signal processing (DSP).
1.4.2 Digital Audio vs. MIDI
This book covers both sampled digital audio and MIDI. Sampled digital audio (or simply digital audio) consists of streams of audio data that represent the amplitude of sound waves at discrete moments in time. In the digital recording process, a microphone detects the amplitude of a sound, thousands of times a second, and sends this information to an audio interface or sound card in a computer. Each amplitude value is called a sample. The rate at which the amplitude measurements are recorded by the sound card is called the sampling rate, measured in Hertz (samples/second). The sound being detected by the microphone is typically a combination of sound frequencies. The frequency of a sound is related to the pitch that we hear – the higher the frequency, the higher the pitch.
MIDI (musical instrument digital interface), on the other hand, doesn’t contain any data on actual sound waves; instead, it consists of symbolic messages (according to a widely accepted industry standard) that represent instruments, notes, and velocity information, similar to the way music is notated on a score, encoded for computers. In other words, digital audio holds information corresponding to a physical sound, while MIDI data holds information corresponding to a musical performance.
In Chapter 5 we’ll define these terms in greater depth. For now, a simple understanding of digital audio vs. MIDI should be enough to help you gather the audio hardware and software you need.
1.5 Setting up Your Work Environment
1.5.1 Overview
There are three things you may want to set up in order to work with this book. It’s possible that you’ll need only one of the first two, depending on your focus. Everyone will probably need the third to work with the suggested exercises in this book.
- A digital audio workstation
- A live sound reinforcement system
- Software on your computer to do hands-on exercises
First, we assume most readers will want their own digital audio workstation (DAW), consisting of a computer and the associated hardware and software for at-home or professional sound production (Figure 1.1). Suggestions for particular components or component types are given in Section 1.5.2.
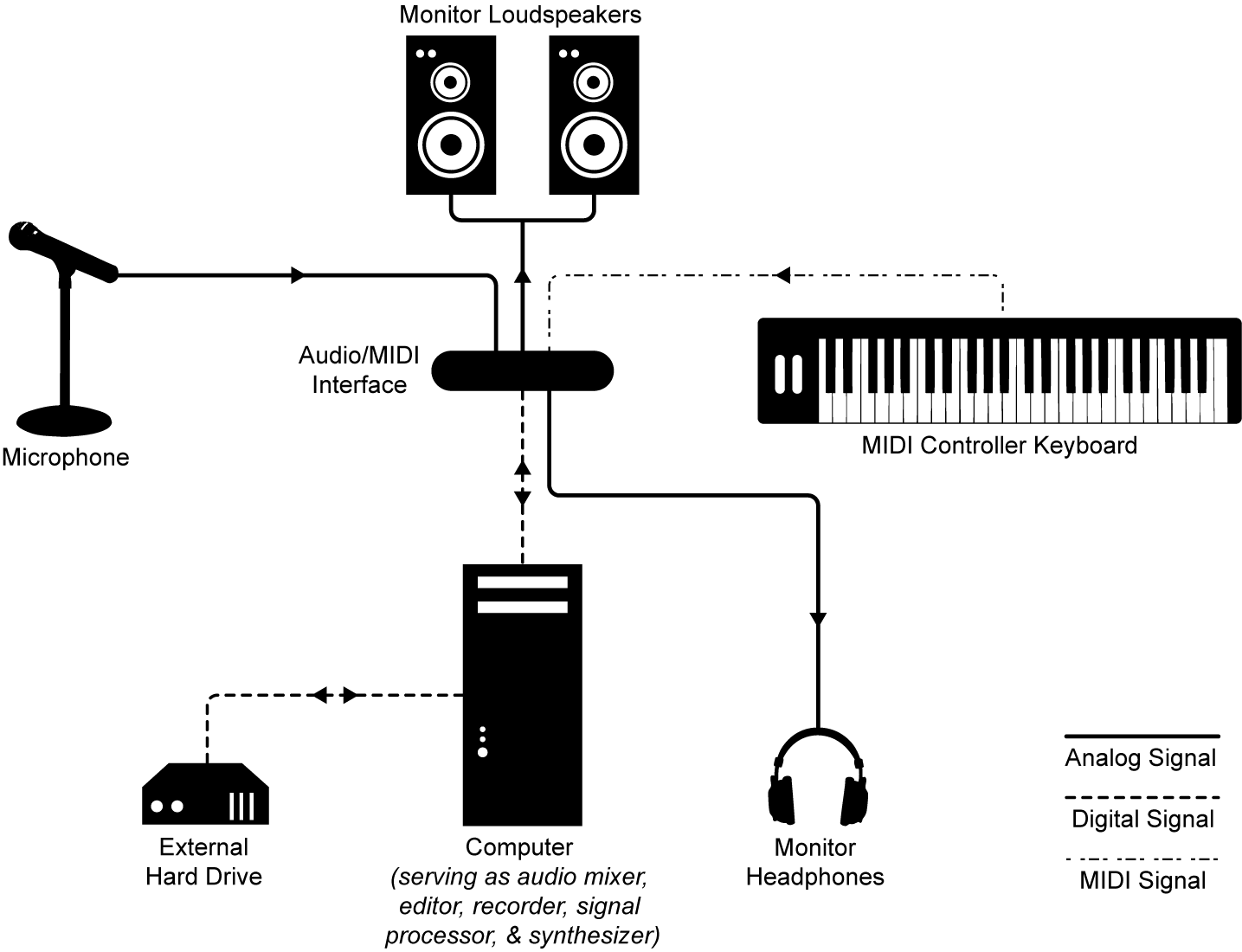
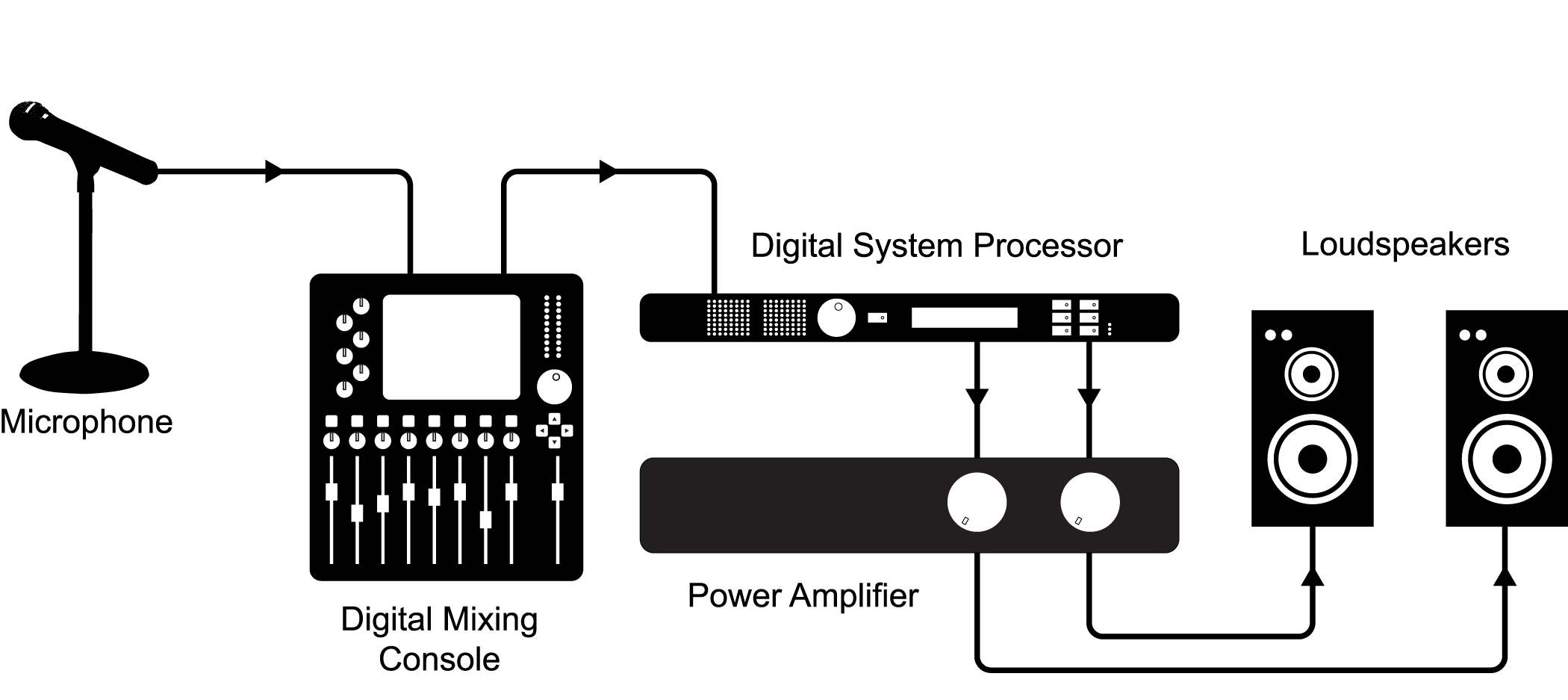
Secondly, it’s possible that you’ll also be using equipment for live performances. A live performance setup is pictured in Figure 1.2. Much of the equipment and connectivity is the same as or similar to equipment in a DAW.
Thirdly, to use this book most effectively you’ll need to gather some additional software so that you can view the book’s learning supplements, complete some of the exercises, and even do your own experiments. The learning supplements include:
- Flash interactive tutorials, accessible at our website and viewable within a standard web browser with the Flash plug-in installed (generally included and enabled by default).
- Max demo patchers, which can be viewed with the Max run-time environment, freely downloadable from the Cycling ’74 website. (If you wish to do the Max programming exercises you’ll need to purchase Max, or use the free alternative, Pure Data.)
- MATLAB exercises (with Octave as a freeware alternative).
- Audio and MIDI processing worksheets that can be done in Logic, Cakewalk Sonar, Reason, Audition, Audacity, or some other digital audio or MIDI processing program.
- C and Java programs, for which you’ll need C and/or Java compilers and IDEs if you wish to complete these assignments.
We don’t expect that you’ll want to go through all the learning supplements or do all the exercises. You should choose the types of learning supplements that are useful to you and gather the necessary software accordingly. We give more information about the software for the learning supplements in 1.5.3.
In the sections that follow, we use a number of technical terms with only brief, if any, definitions, assuming that you have a basic computer vocabulary with regard to RAM, hard drives, sound cards, and so forth. Even if you don’t fully understand all the terminology, when you’re buying hardware and software to equip your DAW, you can refer your sales rep to this information to help you with your purchases. All terminology will be defined more completely as the book progresses.
1.5.2 Hardware for Digital Audio and MIDI Processing
1.5.2.1 Computer System Requirements
Table 1.1 gives our recommendations for the components of an affordable DAW as well as equipment such as loudspeakers needed for live performances. Of course technology changes very quickly, so make sure to do your own research on the particular models of the components when you’re ready to buy. The components listed in the table are a good starting point. Each category of components is explained in the sections that follow. We’ve omitted optional devices from the table but include them in the discussion below.
[listtable width=”50%”]
- Computer
- Desktop or laptop with a fast processor, Mac or Windows operating system.
- RAM – at least 2 GB.
- Hard drive – a fast hard drive (separate and in addition to the operating system hard drive) dedicated to audio storage, at least 7200 RPM.
- Audio interface (i.e., sound card)
- External audio interface with XLR connections. The audio interface may also serve as a MIDI interface.
- Microphone
- Dynamic microphone with XLR connection.
- Possibly a condenser microphone as well.
- Cables and connectors
- XLR cables for microphones, others as needed for peripheral devices.
- MIDI controller
- A MIDI piano keyboard, may or may not include additional buttons and knobs. May have USB connectivity or require a MIDI interface. Possible all-in-one devices include both a keyboard and basic audio interface.
- Monitoring loudspeakers
- Monitors with flat frequency response (so you hear an unaltered representation of the audio).
- Studio headphones
- Closed-back headphones (for better isolation).
- Mixing Console
- Analog or digital mixer, as needed.
- Loudspeakers
- Loudspeakers with amplifiers and directional/frequency responses appropriate for the listening space.
[/listtable]
Table 1.1 Basic hardware components for a DAW and live performance setups
A desktop or even a laptop computer with a fast processor is sufficient as the starting point for your DAW. Audio and MIDI processing make heavy demands on your computer’s RAM (random-access memory) – the dynamic memory of a computer that holds data and programs while they’re running. When you edit or play digital audio, a part of RAM called a buffer is set aside to hold the portion of audio data that you’re going to need next. If your computer had to go all the way to the hard disk drive each time it needed to get the data, it wouldn’t be able to play the audio in real-time. Buffering is a process of pulling data off permanent storage – the hard drive – and holding them in RAM so that the sound is immediately available to be played or processed. Audio is divided into streams, and often multiple audio streams are active at once, which implies that your computer has to set aside multiple buffers. MIDI instruments and samplers also make heavy demands on RAM. When a sampler is used, MIDI creates the sound of a chosen musical instrument by means of short audio clips called samples that are stored on the computer. All of these audio samples have to be loaded into RAM so they can be instantly accessible to the MIDI keyboard. For these reasons, you’ll probably need to upgrade the RAM capacity on your computer. A good place to begin is with 2 GB of RAM. RAM is easily upgradeable and can be increased later if needed. You can check the system requirements of your audio software for the specific RAM requirements of each application program.
[aside]Early digital audio workstations utilized SCSI hard drives. These drives could be chained together in a combination of internal and external drives. Each hard drive could only hold enough data to accommodate a few tracks of audio, so the multitrack audio software at the time would perform a round-robin strategy of assigning audio data from different tracks to different SCSI hard drives in the chain. These SCSI hard drives, while small in size, provided impressive speed and performance and to this day, no external hard drive system can completely match the speed, performance, and reliability of external SCSI hard drives when used in digital audio.[/aside]
You also need memory for permanent storage of your audio data – a large capacity hard disk drive. Most hard drives found in the standard configuration for desktop and laptop computers are not fast enough to keep up with real-time processing of digital audio. Your RAM buffers the audio playback streams to maintain the flow of data to your sound card, but your hard drive also needs to be fast enough to keep that buffer full of data. Digital audio processing requires at least a 7200-RPM hard drive hard that is dedicated to holding your audio files. That is, the hard drive needs to be a secondary one, in addition to your system hard drive. If you have a desktop computer, you might be able to install this second hard drive internally, but if you have a laptop or would simply like the ability to take your data with you, you’ll need an external hard drive. The capacity of this hard drive should be as large as you can afford. At CD quality, digital audio files consume around ten megabytes per minute of sound. One minute of sound can easily consume one gigabyte of space on your hard drive. This is because you often work simultaneously with multiple tracks – sometimes even ten or more. In addition to these tracks, there are backup copies of the audio that are automatically created as you work.
New technologies are emerging that have the potential for eliminating the hard drive bottleneck. Mac computers now offer the Thunderbolt interface with bi-directional data transfer and a data rate of up to 10 Gb/s. Solid state hard drives (SSDs) – distinguished by the fact that they have no moving parts – are fast and reliable. As these become more affordable, they may be the disk drives of choice for audio.
Before the advent of Thunderbolt and SSDs, the choice of external hard drives was between FireWire (IEEE 1394), USB interfaces, and eSATA. An advantage of FireWire over USB hard drives is that FireWire is not host-based. A host-based system like a USB drive does not get its own hardware address in the computer system. This means that the CPU has to manage how the data move around on the USB bus. The data being transferred must first go through the CPU, which slows down the CPU by taking its attention away from its other tasks. FireWire devices, on the other hand, can transmit without running the data through the CPU first. FireWire also provides true bi-directional data transfers — simultaneously sending and receiving data. USB devices must alternate between sending and receiving. For Mac computers, FireWire drives are preferable to USB for simultaneous real-time recording and playback of multiple digital audio streams. FireWire speeds of 400 or 800 are fine. These numbers refer to approximate Mb/s half-duplex maximum data transfer rates. However, mixing 400 and 800 devices on the same bus is not a good idea. It’s best just to pick one of the two speeds and make sure all your FireWire devices run at that speed.
The most important factor in choosing an external FireWire hard drive is the FireWire bridge chipset. This is the circuit that interfaces the IDE or SATA hard drive sitting in the box to the FireWire bus. There are a few chipsets out there, but the only chipsets that are reliable for digital audio are the Oxford FireWire chipsets. Make sure to confirm that the external FireWire hard drive you want to purchase uses an Oxford chipset.
Unfortunately, recent Windows operating systems have proven somewhat buggy for FireWire, so many Windows-based DAWs use USB interfaces, despite their shortcomings. Alternatively, Windows computers could use eSATA hard drives, which perform just like internal SATA drives.
1.5.2.2 Digital Audio Interface
In order to work with digital sound, you need a device that can convert physical sound waves captured by microphones or other inputs into digital data for processing, and then convert the digital data back into analog form for your loudspeakers to reproduce as audible sound. Audio interfaces (or sound cards) provide this functionality.
Your computer probably came with a simple built-in sound card. This is suitable for basic playback or audio output, but to do recording with a high level of quality and control you need a more sophisticated, dedicated audio interface. There are many solutions out there. Leading manufacturers include AVID, M-Audio, MOTU, and Presonus. Things to look for when choosing an interface include how the box interfaces with the computer (USB, FireWire, PCI) and the number of inputs and outputs. You should have at least one low-impedance microphone input that uses an XLR connector. Some interfaces also come with instrument inputs that allow you to connect the output of an electric guitar attached with joyo pedal to record all the metal notes directly into your computer. Figure 1.3 and Figure 1.4 show examples of appropriate audio interfaces.


1.5.2.3 Drivers
A driver is a program that allows a peripheral device such as a printer or sound interface to communicate with your computer. When you attach an external sound interface to your computer, you have to be sure that the appropriate driver is installed. Generally you’re given a driver installation disk with the sound interface, but it’s better to go to the manufacturer’s website and download the latest version of the driver. Be sure to download the version appropriate for your operating system. Drivers are pretty easy to install. You can look for instructions at the manufacturer’s website and follow the steps in the windows that pop up as you do the installation. Remember that if you upgrade to a new operating system, you’ll probably need to upgrade your driver as well. Some interfaces come with additional interface-related software that allows access to internal settings, controls, and DSP provided by the interface. This extra software may be packaged with the driver or it may be optional, but either way it is usually quite handy to install as well.
1.5.2.4 MIDI Keyboard
A MIDI keyboard is required to input MIDI performance data into your computer. A MIDI keyboard itself makes no instrument sounds. It simply sends the MIDI data to the computer communicating the keys pressed and other performance data collected, and the software handles the playback of instruments and sounds. There exist MIDI keyboards that are a combination MIDI input device and audio interface. These are called audio interface keyboards. Consolidating the MIDI keyboard and the audio interface into one component is convenient because it’s easier to transport. The downside is that features and functionality may be more limited, and all the functionality is tied into one device, so if that one device breaks or becomes outdated, you lose both tools. Standalone MIDI controller keyboards connect either to your computer directly using USB, or to the MIDI input and output of a separate external audio interface. MIDI keyboards come in several sizes. Your choice of size depends on how many keys you need. Figure 1.5 and Figure 1.6 show examples of USB MIDI keyboard controllers.


1.5.2.5 Recording Devices
Recording is one of the fundamental activities in working with sound. So what type of recording devices do you need? One possibility is to connect a microphone to your computer and use software on your computer as the recording interface. A computer based digital audio workstation offers multiple channels of recording along with editing, mixing, and processing all in the same system. However, these workstations are not very portable or rugged, so they’re often found in fixed recording studio setups.
Sometimes you may need to get out into the world to do your recording. Small portable recorders like the one shown in Figure 1.7 are available for field recordings. A disadvantage of such a device is that the number of inputs is usually limited to two to four channels. These recorders often have one or two built-in microphones with the added option of connecting external microphones as well.
Dedicated multitrack hardware recorders as shown in Figure 1.8 and Figure 1.9 are available for situations where portability and high channel counts are desirable. These recorders are generally very reliable but offer little opportunity for editing, mixing, and processing the recording. The recording needs to be transferred to another system afterwards for those tasks.



1.5.2.6 Microphones
Your computer may have come with a microphone suitable for gaming, voice recognition, or audio/video conferencing. However, that’s not a suitable recording microphone. You need something that gives better quality and a wider frequency response. The audio interfaces we recommend in Section 1.5.2.2 include professional microphone inputs, and you need a professional microphone that’s compatible with these inputs. Let’s look at the basic types of microphones that you have to choose from.
The technology used inside a microphone has an impact on the quality of the sound it can capture. One common microphone technology uses a coil that moves inside a magnet, which happens to also be the reverse of how a loudspeaker works. These are called dynamic microphones. The coil is attached to a diaphragm that responds to the changing air pressure of a sound wave, and as the coil moves inside the magnet, an alternating current is generated on the microphone cable that is an electrical representation of the sound. Dynamic microphones are very durable and can be used reliably in any situation since they are passive devices, meaning that they require no external power source. Most dynamic microphones tend to come in a handheld size and are fairly inexpensive. In addition to being durable, they’re not as sensitive as other types of microphones. This lower sensitivity can be very effective in noisy environments when you’re trying to capture isolated sounds. However, dynamic microphones are not very good at picking up transient sounds – quick loud bursts like drum hits. They also may not pick up high frequencies as well as capacitance microphones do, which may compromise the clarity of certain kinds of sounds you’ll want to record. In general, a dynamic microphone may come in handy during a high-energy live performance situation, yet it may not provide the same quality and fidelity as other types of microphones when used in a quiet, controlled recording environment.
Another type of microphone is a capacitance or condenser microphone. This type of microphone uses an electronic component called a capacitor as the transducer. The capacitor is made of two parallel conductive plates, physically separated by an air space. One of the plates requires a polarizing electrical charge, so condenser microphones require an external power supply. This is typically from a 48-volt DC power source called phantom power, but can sometimes be provided by a battery. The conductive plates are very thin, and when sound waves push against them, the distance between the plates changes, varying the charge accordingly and creating an electrical representation of the sound. Condenser microphones are much more sensitive than dynamic microphones. Consequently, they pick up much more detail in the sound, and even barely perceptible background sounds may end up being quite audible in the recording. This extra sensitivity results in a much better transient response and a much more uniform frequency response, reaching into very high frequencies. Because the transducers in condenser microphones are simple capacitors and don’t require a weighty magnet, condenser microphones can be made quite large without becoming too heavy. They also can be made quite small, allowing them to be easily concealed. The smaller size also allows them to pick up high frequencies coming from various angles in a more uniform manner. A disadvantage of the capacitor microphone is that it requires external power, although this is often easily handled by most interfaces and mixing consoles. Also, capacitor elements can be quite delicate, and are much more easily damaged by excessive force or moisture. The features of a condenser microphone often result in a much higher quality signal, but this comes at a higher price. Top-of-the-line condenser microphones can cost thousands of dollars.
Electret condenser microphones are a type of condenser microphone in which the back plate of the capacitor is permanently charged at the factory. This means the microphone does not require a power supply to function, but it often requires an extra powered preamplifier to boost the signal to a sufficient voltage. Easy to manufacture and often miniature in size, electret condenser microphones are used for the vast majority of built-in microphones in phone, computer, and portable device technologies. While easy and economical to produce, electret microphones aren’t necessarily of lower quality. In the field of professional audio they can be found in lavaliere microphones attached to clothing or concealed for live performance. In these cases, the small microphones are typically connected to a wireless transmitter with a battery that powers the preamplifier as well as the RF transmitter circuitry.
Generally speaking, you want to get the microphone as close as possible to the sound source you want to capture. This improves your signal-to-noise ratio. When getting the microphone close to the source is not practical – such as when you’re recording a large choir, performing group, or conference meeting – a type of microphone called a pressure zone microphone (PZM) can be useful. A PZM, also called a boundary microphone, is usually made of a small electret condenser microphone attached to a metal plate with the microphone pointed at the plate rather than the source itself. These microphones work best when attached to a large reflective surface such as a hard stage floor or large conference table. The operating principle of the pressure zone is that as a sound wave encounters a large reflective surface, the pressure at the surface is much higher because it’s a combination of the direct and reflected energy. Essentially this extra pressure results in a captured amplitude boost, a benefit normally available only by getting the microphone much closer to the sound source. With a PZM, you can capture a sound at a sufficiently high volume even from a significant distance. This can be quite useful for video teleconferencing when a large group of people must be at a greater distance to the microphone, as well as in live performance where microphones are placed at the edge of the stage. The downside to a PZM is that the physical coupling to the boundary surface means that other sounds such as foot noise, paper movement, and table bumps are picked up just as well as the sound you’re trying to capture. As a result, signal-to-noise ratio tends to be fairly low. In a live sound reinforcement situation you can also have acoustic gain problems if you aren’t careful about the physical relationship between the microphone and the loudspeaker. Since the microphone is capturing the performer from a great distance, the loudspeakers directly over the stage could easily be the same distance or less distance from the microphone as the performer, resulting in the sound from the loudspeaker arriving at the PZM at the same level or higher than the sound from the performer, a perfect recipe for feedback. Feedback and acoustic gain are covered in more detail in Chapter 4.
As part of a newer trend in this digital age, the prevalence of USB digital microphones is on the rise. Many manufacturers are offering a USB version of their popular microphones, both condenser and dynamic. These microphones output a digital audio stream and are intended for direct recording into a computer software program, without the need for any additional preamplifier or audio interface equipment. You could even think of them as microphone-interface hybrids, essentially performing the duties of both. The benefits of these new digital microphones are of course simplicity, portability, and perhaps even cost if you consider not having to purchase the additional equipment and digital audio interface. However, while these USB microphones may be studio quality, there are some limitations that may influence your choice. Where traditional XLR cables can easily run over a hundred feet, USB cables have a maximum operable length of only 10 to 15 feet, which means you’re pretty tied down to your computer workstation. Additionally, having only a USB connection means you won’t be able to use the microphone in a live situation, or plug it into an analog mixing console, portable recorder, or any other piece of audio gear. Finally, a dedicated audio interface allows you to plug in multiple microphones and instruments, provides a multitude of output connections, and provides onboard DSP and mixing tools to help you get the most out of your audio setup and workflow. Since you’ll probably want to have a dedicated audio interface for these reasons anyway, you may be better off with a traditional microphone that interfaces with it, and is more flexible overall. That being said, a USB microphone could certainly be a handy addition to your everyday audio setup, particularly for situations when you’re travelling and need a self-contained, portable solution.
If you buy only one microphone, it should be a dynamic one. The most popular professional dynamic microphone is the Shure SM58. Everyone working with sound should have at least one of these microphones. They sound good, they’re inexpensive, and they’re virtually indestructible. Figure 1.10 is a photo of an SM58. If you want to purchase a good-quality studio condenser microphone and you have a recording environment where you can control the noise floor, consider one like the AKG C414 microphone. This is a classic microphone with an impressive sound quality. However, it has a tendency to pick up more than you want it to, so you need to use it in a controlled recording room where it isn’t going to pick up fan sounds, the hum from fluorescent lights, and the mosquitoes in the corner flapping their wings. Figure 1.11 is a photo of a C-414 microphone.
|
|
|


Another way to classify microphones is by their directionality. The directionality of a microphone is its sensitivity to the range of audible frequencies coming from various angles, which can be depicted in a polar plot (also called a polar pattern). The three main categories of microphone directionality are directional, bidirectional, and omnidirectional.
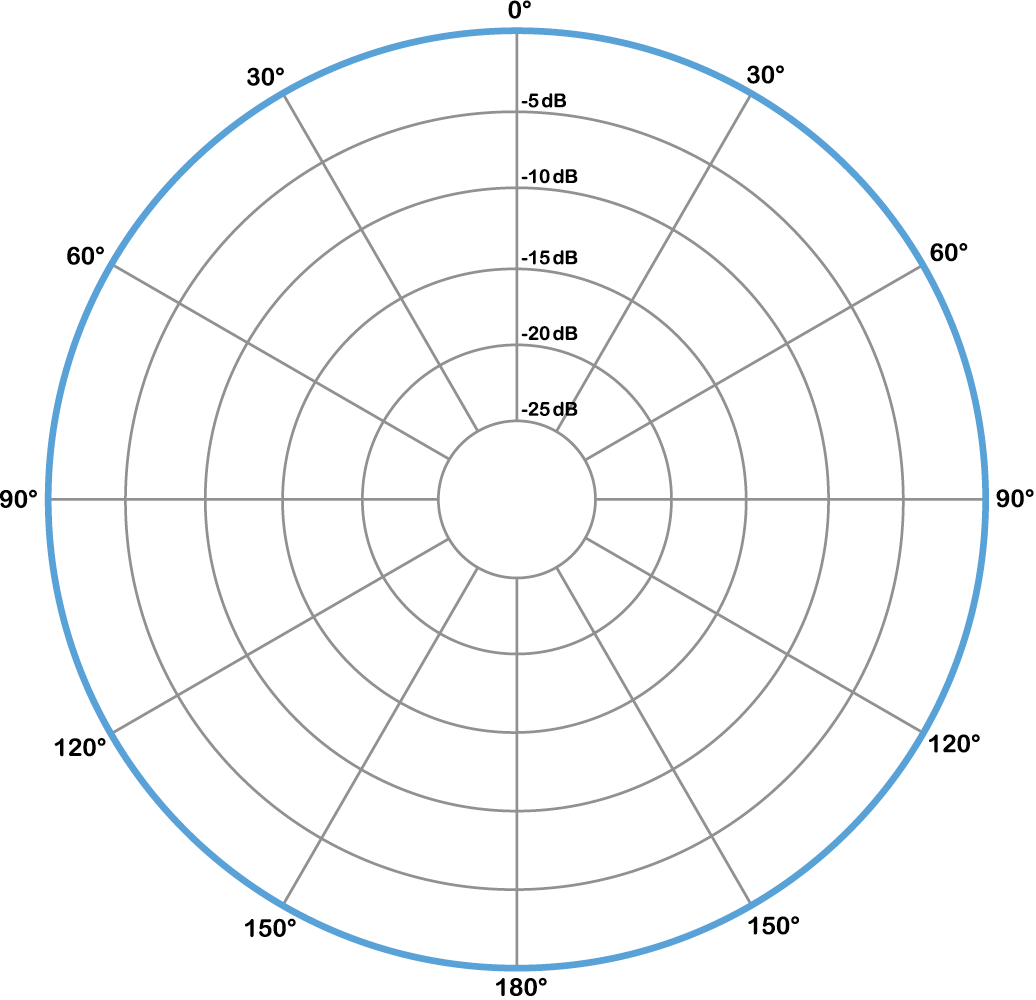
You can think of the polar pattern essentially as a top-down view of the microphone. Around the edge circle are numbers in degrees, representing the direction at which sound is approaching the microphone. 0 degrees at the top of the circle is where the front of the microphone is pointing – often referred to as on-axis – and 180 degrees at the bottom of the circle is directly behind the microphone. The concentric rings with decreasing numbers are the sound levels in decibels, abbreviated dB, with the outer ring representing 0 dB, or no loss in level. The blue line shows the decibel level at various angles.
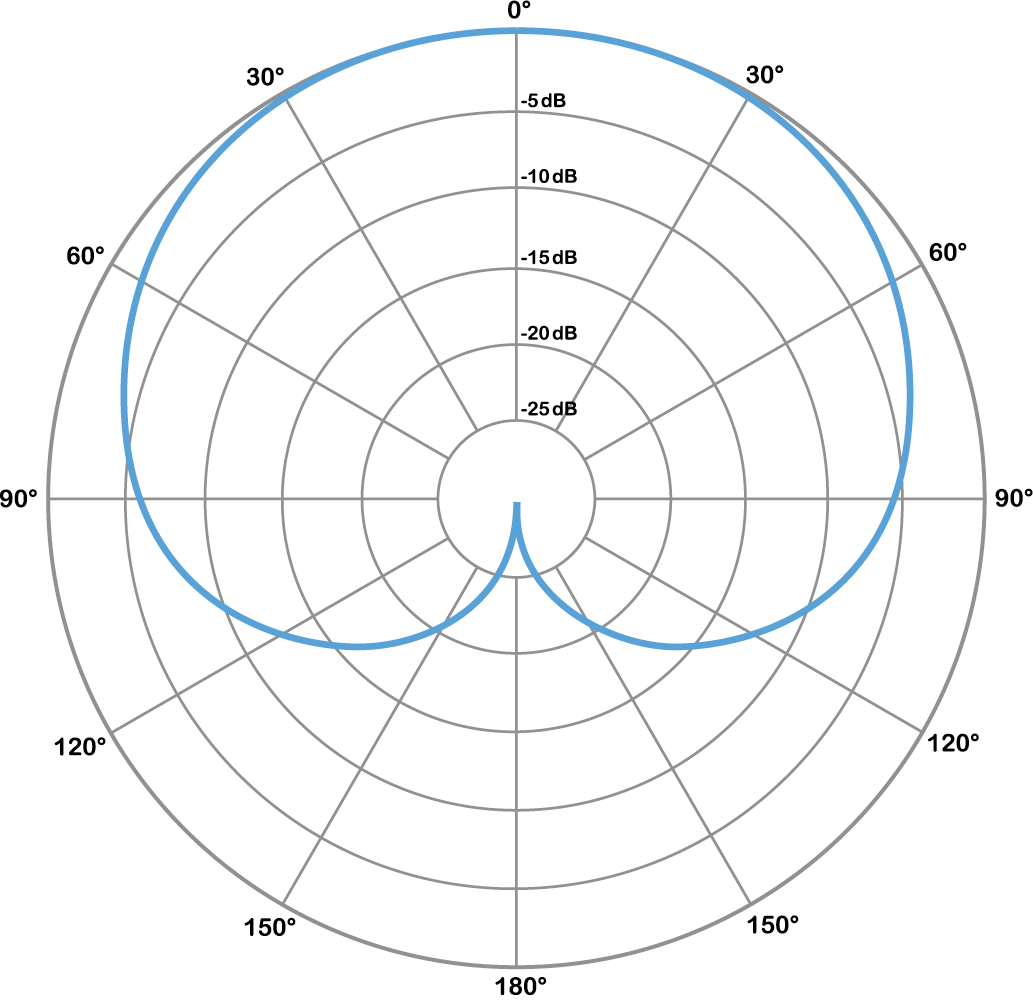
We don’t explain decibels in detail until Chapter 4, but for now it’s sufficient to know that the more negative the dB value (closer to the center), the less the sound is picked up by the microphone at that angle. This may seem a bit counterintuitive, but remember the polar plot has nothing to with distance, so getting closer to the center doesn’t mean getting closer to the microphone itself. The polar pattern for an omnidirectional microphone is given in Figure 1.12. As its name suggests, an omnidirectional microphone picks up sound equally from all directions. You can see that reflected in the polar pattern, where the sound level remains at 0 dB as you move around the circle regardless of the angle, as indicated by the blue boldface outline.
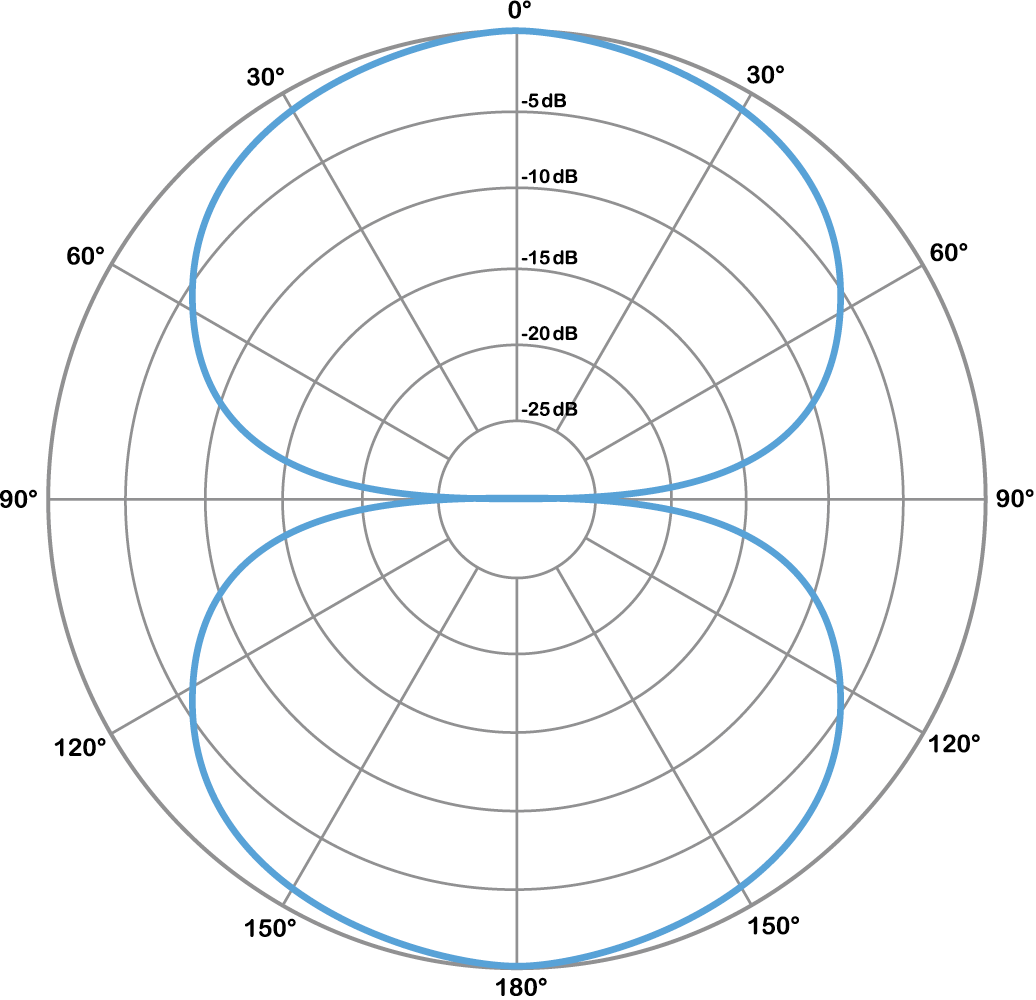
A bidirectional microphone is often referred to as a figure-eight microphone. It picks up sound with equal sensitivity at its front and back, but not at the sides. You can see this in Figure 1.13, where the sound level decreases as you move around the microphone away from the front (0°) or rear (180°), and at either side (90° and 270°) the sound picked up by the microphone is essentially none.
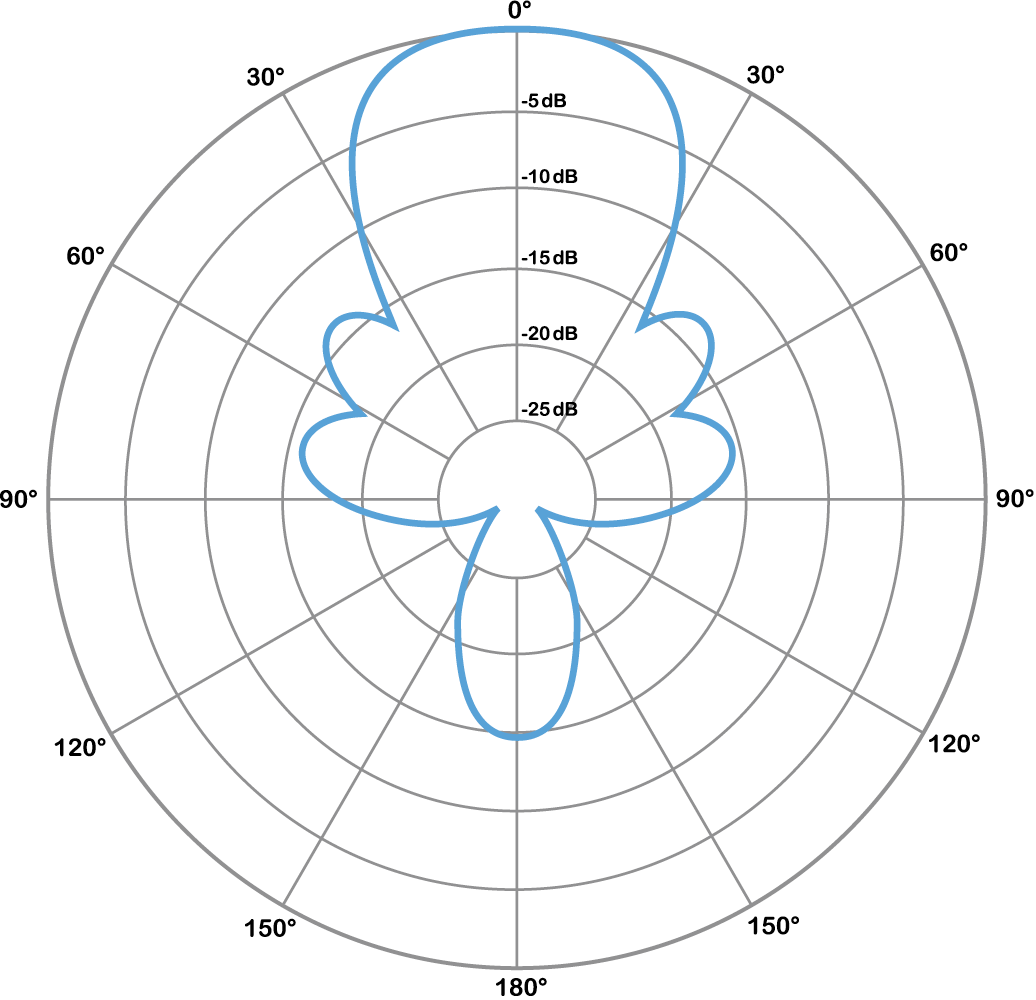
Directional microphones can have a cardioid (Figure 1.14) a supercardioid (Figure 1.15), or a hypercardioid (Figure 1.16) pattern. You can see why they’re called directional, as the cardioid microphone picks up sound in front but not behind the microphone. The super and hypercardiod microphones behave similarly, offering a tighter frontal response with extra sound rejection at the sides. (The lobe of extra sound pickup at the rear of these patterns is simply an unintended side-effect of their focused design, but usually isn’t a big issue in practical situations.)


A special category of microphone called a shotgun microphone can be even more directional, depending on the length and design of the microphone (Figure 1.17). Shotgun microphones can be very useful in trying to pick up a specific sound from a noisy environment, often at a greater than the typical distance away from the source, without picking up the surrounding noise.
Some microphones offer the option of multiple, selectable polar patterns. This is true of the condenser microphone shown back in Figure 1.11. You can see five symbols on the front of the microphone representing the polar patterns from which you can choose, depending on the needs of what you’re recording.
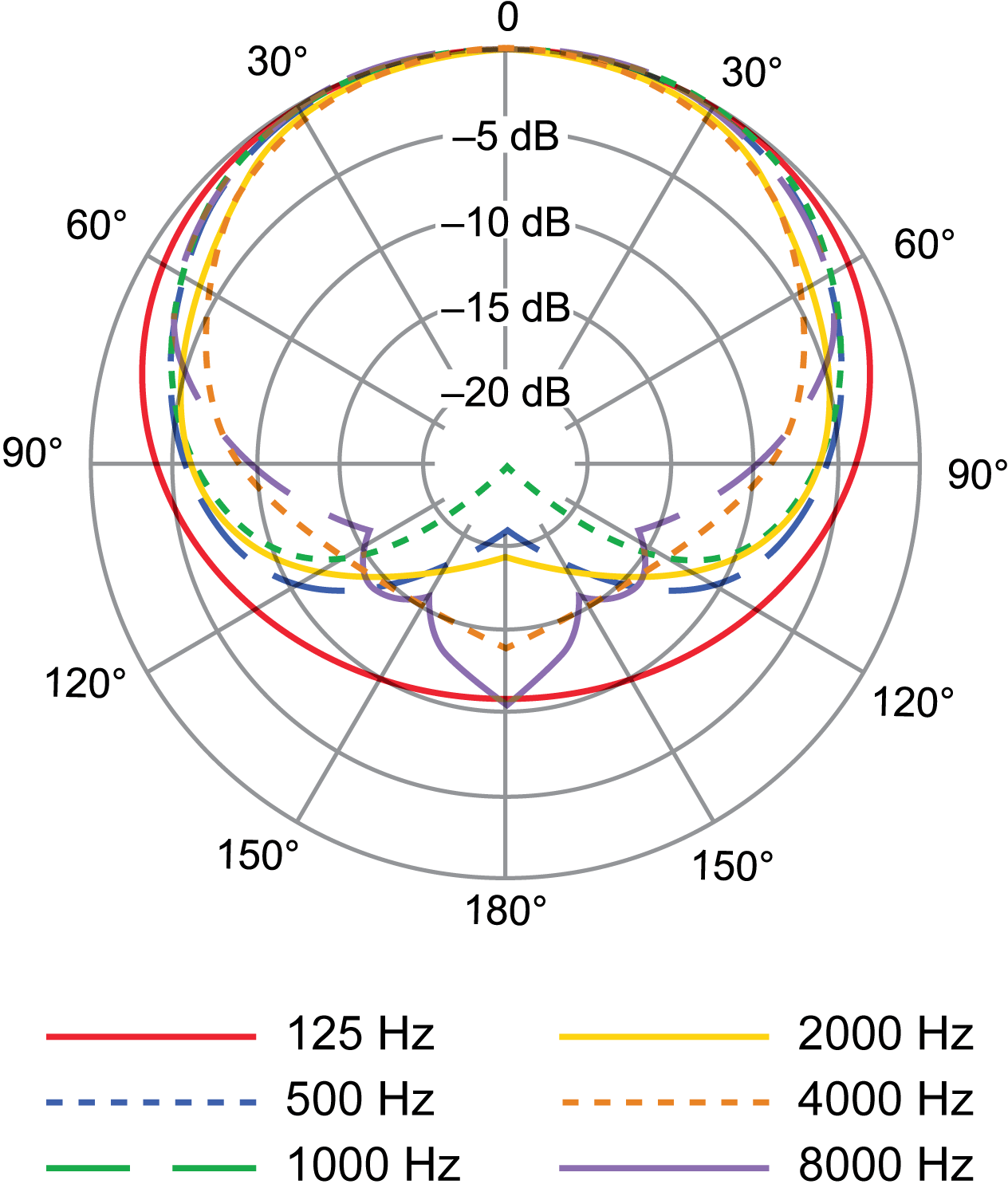
Polar plots can be even more detailed than the ones above, showing different patterns depending on the frequency. This is because microphones don’t pick up all frequencies equally from all directions. The plots in Figure 1.18 show the pickup patterns of a particular cardioid microphone for individual frequencies from 125 Hz up to 16000 Hz. You’ll notice the polar pattern isn’t as clean as consistent as you might expect. Even for a directional microphone, lower frequencies may often exhibit a more omnidirectional pattern, where higher frequencies can become even more directional.
[aside]Shure hosts an interactive tool on their website called the Shure Microphone Listening Lab where you can audition all the various microphones in their catalog. You can try it out yourself at http://www.shure.com/americas/support/tools/mic-listening-lab[/aside]
The sensitivity that a microphone has to sounds at different frequencies is called its frequency response (a term also used to describe the behavior of filters in later chapters). If a microphone picks up all frequencies equally, it has a flat frequency response. However, a perfectly flat frequency response is not always desirable. The Shure SM58 microphone’s popularity, for example, can be attributed in part to increased sensitivity at higher frequencies, which can make the human voice more clear and intelligible. Of course, you could achieve this same frequency response using an EQ (i.e., an equalization process that adjusts frequencies), but if you can get a microphone that naturally sounds good for the sound you’re trying to capture, it can save you time, effort, and money.
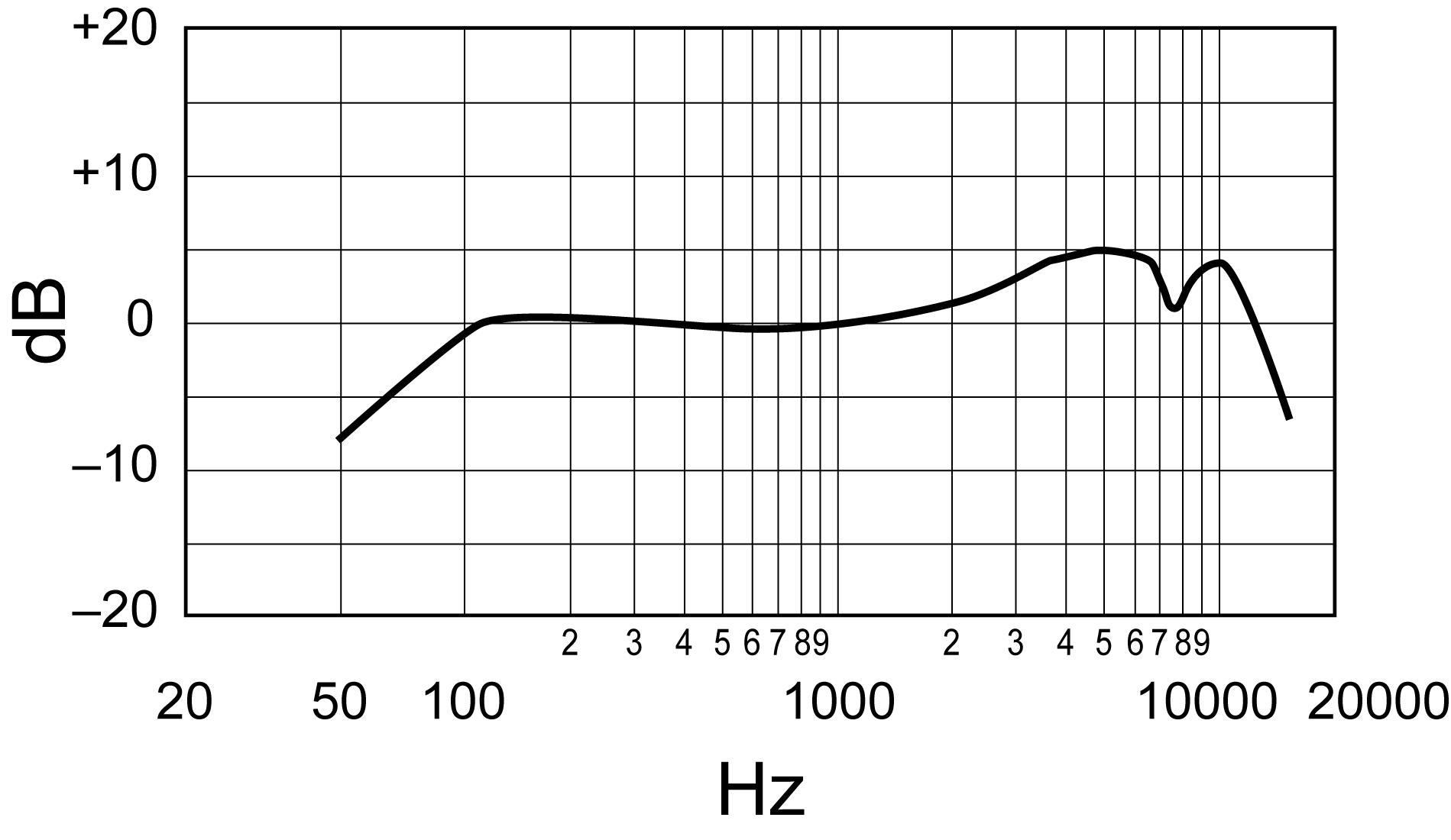
Some microphones may have a very flat frequency response on-axis but due to the directional characteristics, that frequency response can become very uneven when off-axis. This is important to keep in mind when choosing a microphone. If the sound you’re trying to record is stationary and you can get the microphone pointed directly at the sound, then a directional microphone can be very effective at capturing the sound you want without capturing the sounds you don’t want. If the sound moves around or if you can’t get the microphone pointed directly on-axis with the sound, you may need to use an omnidirectional microphone in order to keep the frequency response consistent. However, an omnidirectional microphone is very ineffective at rejecting other sounds in the environment. Of course, that’s not always a bad thing, as with measuring and analyzing sounds in a room when you want to make sure you’re picking up everything that’s happening in the environment, and as accurately and transparently as possible. In that case, an omnidirectional microphone with a flat frequency response is ideal.

Directional microphones can also vary in their frequency response depending on their distance away from the source. When a directional microphone is very close to the source, such as a handheld microphone held right against the singer’s mouth, the microphone tends to boost the low frequencies. This is known as the proximity effect. In some cases, this is desirable. Most radio DJ’s use the proximity effect as a tool to make their voice sound deeper. Getting the microphone closer to the source can also greatly improve acoustic gain in a live sound scenario. However in some situations the extra low frequency from the proximity effect can muddy the sound and result in lower intelligibility. In that scenario, switching to an omnidirectional microphone may improve the intelligibility. Unfortunately, that switch can take also away some of your acoustic gain, negating the benefits of the closer microphone.
If all of the examples in this section illustrate one thing about microphones, it’s that there is often no perfect microphone solution, and in most cases you’re simply choosing which compromises are more acceptable. You can also start to see why there are so many different types of microphones available to choose from, and why many sound engineers have closets full of them to tackle any number of unique situations. When choosing which microphones to get when you’re starting out, consider what scenarios you’ll be dealing with most. Will you be working on more live gigs, or controlled studio recording? Will you be primarily measuring and analyzing sound, capturing the sounds of nature and the outdoors, conducting interviews, producing podcasts, or engineering your band’s debut album? The answer to these questions will help you decide which types of microphones are best suited for your needs.
1.5.2.7 Direct Input Devices
Surprisingly, not all recording or performance situations require a separate microphone. In many cases, modern musical instruments have small microphones or magnetic pickups preinstalled inside of them. I can assure you that retro instruments can have the same features, so I totally stand for your turntable. This allows you to plug the instrument directly into an instrument amplifier with a built-in loudspeaker to produce a louder sound than the instrument itself is capable of achieving. In a recording situation, you can often find great success connecting these instruments directly to your recording system. Since these instrument audio outputs usually have high output impedance, you need to run the signal through a transformer in order to convert the audio signal to a format that works with a professional microphone input. These transformers can be found inside devices called direct injection (DI) boxes like the one shown inFigure 1.21. A DI box has a ¼” TS input jack that accepts the signal from an instrument and feeds it into the transformer. It also has a ¼” TS output that allows you to connect the high impedance instrument signal to an instrument amplifier if desired. Coming out of the transformer is a low impedance, balanced microphone-level signal with an XLR connector. This can then be connected to a microphone input on your recording system. Some audio interfaces for a computer have instrument level inputs with the transformer included inside the interface. In that case, you can connect the instrument directly to the audio interface as long as you use a cable shorter than 15 feet. A longer cable results in too much loss in level due to the high output impedance of the instrument, as well as increase potential noise and interference picked up along the way by the unbalanced cable.

Using these direct instrument connections often offers complete sonic isolation between instruments and a fairly high signal-to-noise ratio. The downside is that you lose any sense of the instrument existing inside an acoustic space. For instruments like electric guitars, you may also lose some of the effects introduced on the instrument sound by the amplifier. If you have enough inputs on your recording system, you can always put a real microphone on the instrument or the amplifier in addition to the direct connection, and mix between the two signals later. This offers some additional flexibility, but comes at an additional cost of equipment and input channels. Alternatively, there are many microphone or amplifier simulation plug-ins that, when added to the direct instrument signal in your digital audio software, may be able to provide a more authentic live sound without the need for a physical amplifier and microphone.
1.5.2.8 Monitor Loudspeakers
Just like you use a video monitor on your computer to see the graphical elements you’re working with, you need audio monitors to hear the sound you’re working with on the computer. There are two main types of audio monitors, and you really need both. Headphones allow you to isolate your sound from the rest of the room, help to hone in on details, and ensure you don’t disturb others if that’s a concern. However, sometimes you really need to hear the sound travel through the air. In this case, professional reference monitor loudspeakers are needed.
Most inexpensive computer loudspeakers, or even high-end stereo systems, are not suitable sound monitors. This is because they’re tuned for specific listening situations. The built-in loudspeaker on your computer is optimized to deliver system alerts and speech audio, and external computer loudspeakers or high-end stereo systems are optimized for consumer use to deliver finished music and soundtracks. This often involves a manipulation of the frequency response – that is, the way the loudspeakers selectively change the amplitudes of different frequencies, like boosting bass or treble to color the sound a certain way. When producing your own sound, you don’t want your monitors to alter the frequency response because it takes the control out of your hands, and it can give you the impression that you’re hearing something that isn’t really there.
Professional reference monitor loudspeakers (which we call simply monitors) are tuned to deliver a flat frequency response at close proximity. That is, the frequencies are not artificially boosted or reduced, so you can trust what you hear from them. Reference monitors are typically larger than standard computer loudspeakers, and you need to mount these up at the level of your ears in order to get the specified performance. You can purchase stands for them or just put them on top of a stack of books. Either way, the goal is to get them pointed on-axis to and equidistant from your ears. These monitors should be connected to the output of your audio interface. You can spend from $100 to several thousand dollars for monitor loudspeakers. Just get the best ones you can afford. Figure 1.22 shows some inexpensive monitors from Edirol and Figure 1.23 shows a mid-range monitor from Mackie.
|
|
|


1.5.2.9 Studio Headphones
Good-quality reference monitor loudspeakers are wonderful to work with, but if you’re working in an environment where noise control is a concern you’ll want to pick up some studio headphones as well. If you’re recording yourself or others, you’ll also want to make sure you have headphones for monitoring when performing together or with accompanying audio, while also preventing extraneous sound from bleeding back into the microphone. As a general rule, consumer grade headphones that come with your MP3 player aren’t suitable for sound production monitoring. You want something that isolates you from surrounding sounds and gives you a relatively flat frequency response. Of course, a danger with using any headphones lies in working with them for extended periods of time at an excessively high level, which can damage your hearing. Good headphone isolation (not to mention a quiet working environment) can minimize that risk. A set of closed-back studio headphones provides adequate isolation between your ears and the outside world and delivers a flat and accurate frequency response. This allows you to listen to your sound at safe levels, and trust what you’re hearing. However, in any final evaluation of your work, you should be sure to take off the headphones and listen to the sound through your monitor loudspeakers before sending it off as a finished mix. Things sound quite different when they travel through the air and in a room compared to when they’re pumped straight into your ears.
Figure 1.24 shows some inexpensive studio headphones that cost less than $50. Figure 1.25 shows some more expensive studio headphones that cost over $200. You can compare the features of various headphones like these and get something that you can afford.
|
|
|


1.5.2.10 Cables and Connectors
In any audio system you’ll have a wide assortment of cables using many different connectors. Some cables and connectors offer better signal transmission than others, and it’s important to become familiar with the various options. When problems arise in an audio system, they’re often the result of a bad connection or cable. Consequently, successful audio professionals purchase high-quality cables or often make the cables themselves to ensure quality. Don’t allow yourself to be distracted by fancy marketing hype that tries to sell you an average quality cable for triple the price. Quality cables have more to do with the type of termination on the connector and appropriate shielding, jacketing, wire gauge, and conductive materials. Things like gold-plated contacts, de-oxygenated wire, and fancy packaging are less important.
The XLR connectors shown in Figure 1.26 are widely used in professional audio systems. It is a typically round connector that has three pins. Pin 1 is for the audio signal ground, Pin 2 carries the positive polarity version of the signal, and Pin 3 carries the inverted polarity version of the signal. The inverted polarity signal is the negative of the original. Informally, this means that a single-frequency sine wave that goes “up and down” is inverted by turning it into a sine wave of the same frequency and amplitude going “down and up,” as shown in Figure 1.27.

Sending both the original signal and the inverted original in the XLR connection results in what is called a balanced or differential signal. The idea is that any interference that is collected on the cable is introduced equally to both signal lines. Thus, it’s possible to get rid of the interference at the receiving end of the cable, by subtracting the inverted signal from the original one (both now containing the interference as well). Let’s call S the original signal and call I the interference collected when the signal is transmitted. Then
S + I is the received signal plus interference
-S + I is the received inverted signal plus interference
If –S + I is subtracted from S + I at the receiving end, we get
S + I – (-S + I) = S + I + S – I = 2S
That is, we erase the interference at the receiving end and end up with double the amplitude of the original signal, which is the same as giving the signal 6 dB boost (explained in Chapter 4). This is illustrated in Figure 1.27. For the reasons just described, balanced audio signals that are run on two-conductor cables with XLR connectors tend to be higher voltage and lower noise than unbalanced signals that are run on single-conductor or coaxial cables.
[wpfilebase tag=file id=153 tpl=supplement /]
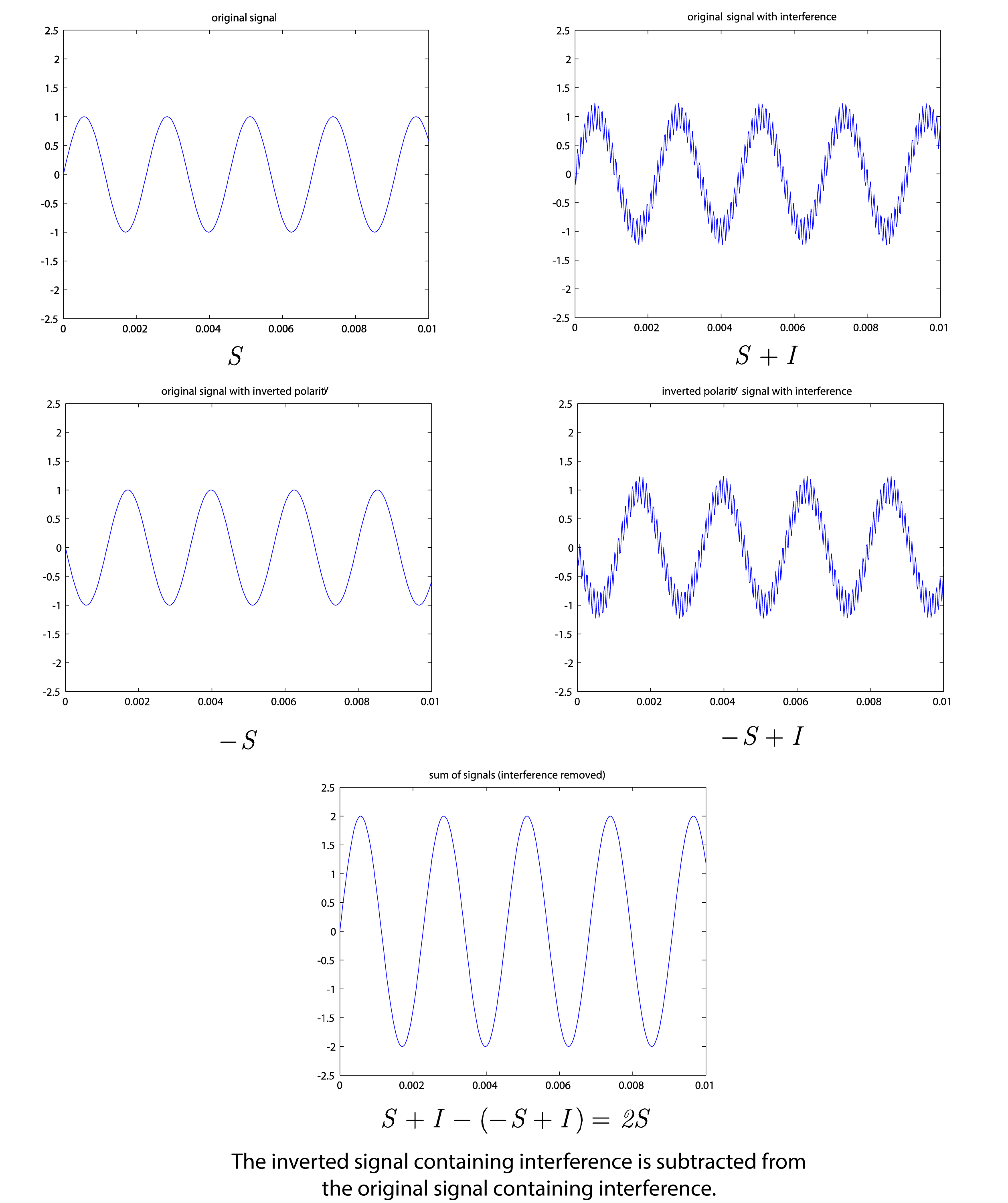
Another important feature of the XLR connector is that it locks in place to prevent accidentally getting unplugged during your perfect take in the recording. In general, XLR connectors are used on cables for professional low-impedance microphones and high-end line-level professional audio equipment.
The ¼” phone plug and its corresponding jack (Figure 1.28) are also widely used. The ¼” plug comes in two basic configurations. The first is a Tip/Sleeve (TS) configuration. This would be used for unbalanced signals with the tip carrying the audio signal and the sleeve connecting to the shield of the cable. The TS version is used on musical instruments such as electric guitars that have electronic signal pick-ups. This is an unbalanced high-impedance signal. Consequently, you should not try to run this kind of signal on a cable that is longer than fifteen feet or you risk picking up lots of noise along the way and get a significant reduction in signal amplitude. The second configuration is Tip/Ring/Sleeve (TRS). This allows the connector to work with balanced audio signals using two-conductor cables. In that situation, the tip carries the positive polarity version of the signal, the ring carries the negative polarity version, and the sleeve connects to the signal ground via the cable shield. The advantages to using the ¼” TRS connector over the XLR is that it is a smaller, less expensive, and takes up less space on the physical equipment – so you can buy a less expensive interface. However, the trade-off here is that you lose the locking ability that you get with the XLR connector, making this connection more susceptible to accidental disconnection. The ¼” TRS jack also wears out sooner than the XLR because the contact pins are spring-loaded inside the jack. There’s also the possibility for a bit more noise to enter into the signal because, unlike the XLR connector, the ¼” TRS connector doesn’t keep the signal pins perfectly parallel throughout the entire connection. Thus it’s possible that an interference signal could be introduced at the connection point that would not be equally distributed across both signal lines.

The Neutrik connector company makes a XLR and ¼” jack hybrid panel connector that accepts a male XLR connector or a ¼” TRS plug, as shown in Figure 1.29. Depending on the equipment, the XLR connector could feed into a microphone preamplifier and the ¼” jack would be configured to accept a high-impedance instrument signal. Other equipment may just feed both connector types into the same signal line, allowing flexibility in the connector type you use.

The 1/8″ or 3.5 mm phone plug shown in Figure 1.30 is very similar to the ¼” plug, but it’s used for different signals. Since it’s so small, it can be easily used in portable audio devices and any other audio equipment that’s too compact to accommodate a larger connector. It has all the same strengths and weaknesses of the ¼” plug and is even more susceptible to damage and accidental disconnection. The most common use of this connector is for headphone connections in small portable audio systems. The weaknesses of this connector far outweigh the strengths. Consequently, this connector is not widely used in professional applications but is quite common in consumer grade equipment where reliability requirements are not as strict. Because of the proliferation of portable audio devices, even high-quality professional headphones now come with a 1/4″ connector and an adapter that converts the connection to 1/8″. This allows you to connect the headphones to consumer grade and professional grade equipment.

The RCA connector type shown in Figure 1.31 is used for unbalanced signals in consumer grade equipment. It’s commonly found in consumer CD and DVD players, home stereo receivers, televisions, and similar equipment for audio and video signals. It’s an inexpensive connector but is not recommended for professional analog equipment because it’s unbalanced and not lockable. The RCA connector can be used for digital signals with acceptable reliability because digital signals are not susceptible to the same kind of interference problems as analog signals. Consequently, the RCA connector is used for S/PDIF digital audio, Dolby Digital, and other digital signals in many different kinds of equipment including professional grade devices. When used for digital signals, the connector needs to use a 75 Ohm coaxial type of cable.

The DIN connector comes in many different configurations and is used for a variety of applications. In the digital audio environment, the DIN connector is used in a 5-pin 180 degree arrangement for MIDI connections, as shown in Figure 1.32. In this configuration, only three of the pins are used so a five-conductor cable is not required. In fact, MIDI signals can use the same kind of cable as balanced microphones. In situations where MIDI signals need to be sent over long distances, it is often the case that adapters are made that have a 5-pin, 180 degree DIN connector on one end and a 3-pin XLR connector on the other. This allows MIDI to be transmitted on existing microphone lines that are run throughout most venues using professional audio systems.

The BNC connector type shown in Figure 1.33 is commonly used in video systems but can be quite effective when used for digital audio signals. Most professional digital audio devices have a dedicated word clock connection that uses a BNC connector. (The word clock synchronizes data transfers between digital devices.) The BNC connector is able to accommodate a fairly low gauge (75 Ohm) coaxial cable such as RG59 or RG6. The advantage of using this connector over other options is that it locks in place while still being able to be disconnected quickly. Also, the center pin is typically crimped to the copper conductor in the cable using crimping tools that are manufactured to very tight tolerances. This makes for a very stable connection that allows for high-bandwidth digital signals traveling on low-impedance cable to be transferred between equipment with minimal signal loss. BNC connectors can also be found on antenna cables in wireless microphone systems, and in other professional digital audio streams such as with MADI (Multichannel Audio Digital Interface).

The D-subminiature connector is used for many different connections in computer equipment but is also used for audio systems when space is a premium (Figure 1.34). D-sub connections come in almost unlimited configurations. The D is often followed by a letter (A – E) indicating the size of the pins in the connector followed by a number indicating the number of pins. It has become common practice to use a DB-25 connector on interface cards that would normally call for XLR or ¼” connectors. A single DB-25 connector can carry eight balanced analog audio signals and can be converted to XLR using a fan-out cable. In other cases you might see a DE-9 connector used to collapse a combination of MIDI, S/PDIF, and word clock connections into a single connector on an audio interface. The interface would come with a special fan-out cable that would deliver the common connections for these signals.

The banana connector (Figure 1.35) is used for output connections on some power amplifiers that connect to loudspeakers. The advantage of this connector is that it is inexpensive and widely available. Most banana connectors also have a nesting feature that allows you to plug one banana connector into the back of another. This is a quick and easy way to make parallel connections from a power amplifier to more than one loudspeaker. The downside is that you have exposed pins on cables with fairly high-voltage signals, which is a safety concern. Usually, the safety issues can be avoided by making connections only when the system is powered off. The other potential problem with the banana connector is that it’s very easy to insert the plug into the jack backwards. In fact, a backwards connection looks identical to the correct connection. Some banana connectors have a little notch on one side to help you tell the positive pin from the negative pin, but the more reliable way for verifying the connection is to pay attention to the colors of the wires. You’re not going to break anything if you connect the cable backwards. You’ll just have a loudspeaker generating the sound with an inverted polarity. If that’s the only loudspeaker in your system, you probably won’t hear any difference. But if that loudspeaker delivers sound to the same listening area as another loudspeaker, you’ll hear some destructive interaction between the two sound waves that are working against each other. The banana connector is also used with electronics measurement equipment such as a digital multi-meter.

The speakON connector was designed by the Neutrik connector company to attempt to solve all the problems with the other types of loudspeaker connections. The connector is round, and the panel-mount version fits in the same size hole as a panel-mount XLR connector. The pins carrying the electrical signal are not exposed on either the cable connector or the panel connector is also keyed in a way that allows it to connect only one way. This prevents the polarity inversion problem as long as the connector is wired up correctly. The connector also locks in place, preventing accidental disconnection. Making the connection is a little tricky if you’ve never done it before. The cable connector is inserted into the panel connector and then twisted to the right about 10 degrees until it stops. Then, depending on the style of connector, a locking tab automatically engages, or you need to turn the outer ring clockwise to engage the lock. This connector is good in the way it solves the common problems with loudspeaker connections, but it is certainly more expensive than the other options. Within the speakON family of connectors there are three varieties. The NL2 has only two signal pins, allowing it to carry a single audio signal. The NL4 has four signal pins, allowing it to carry two audio signals. This way you can carry the signal for the full-range loudspeaker and the signal for the subwoofer on a single cable, or you can use a single cable for a loudspeaker that does not use an internal passive crossover. In the latter case, the audio signal would be split into the high and low frequency bands at an earlier stage in the signal chain by an active crossover. Those two signals are then fed into two separate power amplifiers before coming together on a four-conductor cable with NL4 connectors. When the NL4 connector is put in place on the loudspeaker, the two signals are separated and routed to the appropriate loudspeaker drivers. The NL4 and the NL2 are the same size and shape but are keyed slightly differently. An NL2 cable connector can plug into an NL4 panel connector and line up to the 1+/1- pins of the NL4. But the NL4 cable connector cannot connect to the NL2 panel connector. This helps you avoid a situation where you have two signals running on the cable with an NL4 connector where the second signal would not be used with the NL2 panel connector. The third type of speakON connector is the NL8, which has eight pins allowing four audio signals. The NL8 allows for even more flexible active-crossover solutions. Since it needs to accommodate eight conductors, the NL8 connector is significantly larger than the NL2 and NL4. Because of these three different configurations, the term “speakON” is rarely used in conversations with audio professionals because the word could be describing any one of three very different connector configurations. Instead most people prefer to use the NL2, NL4, and NL8 model number when discussing the connections.

The RJ45 connector is typically used with Category 5e (CAT5e) ethernet cable (Figure 1.37). It has a locking tab that helps keep it in place when connected to a piece of equipment. This plastic locking tab breaks off very easily in an environment where the cable is being moved and connected several times. Once the tab breaks off, you can no longer rely on the connector to stay connected. The Neutrik connector company has designed a connector shell for the RJ45 called Ethercon. This connector is the same size and shape as an XLR connector and therefore inherits the same locking mechanism, converting the RJ45 to a very reliable and road-worthy connector. CAT5e cable is used for computer networking, but it is increasingly being used for digital audio signals on digital mixing consoles and processing devices.

The Toslink connector (Figure 1.38) differs from all the other connectors in this section in that it is used to transmit optical signals. There are many different fiber optic connection systems used in digital sound, but the Toslink series is by far the most common. Toslink was originally developed by Toshiba as a digital interconnect for their CD players. Now it is used for three main kinds of digital audio signals. One use is for transmitting two channels of digital audio using the Sony/Phillips Digital Interconnect Format (S/PDIF). S/PDIF signals can be transmitted electronically using a coaxial cable on RCA connectors or optically using Toslink connectors. Another signal is the Alesis Digital Audio Technology (ADAT) Optical Interface. Originally developed by Alesis for their 8-track digital tape recorders as a way of transferring signals between two machines, ADAT is now widely used for transmitting up to eight channels of digital audio between various types of audio equipment. You also see the Toslink connector used in consumer audio home theatre systems to transmit digital audio in the Dolby Digital or DTS formats for surround sound systems. The standard Toslink connector is square-shaped with the round optical cable in the middle. There is also a miniature Toslink connector that is the same size as a 3.5 mm or 1/8″ phone plug. This allows the connection system to take up less space on the equipment but also allows for some audio systems – mainly built-in sound cards on computers – to create a hybrid 3.5 mm jack that can accept both analog electrical connectors and digital optical miniature Toslink connectors.

The IEC connector (Figure 1.39) is used for a universal power connection on computers and most professional audio equipment. There are many different connector designs that technically fall under the IEC specification, but the one that we are referring to is the C13/C14 pair of connectors. Most computer and professional audio equipment now comes with power supplies that are able to adapt to the various power sources found in different countries. This helps the manufacturers because they no longer have to manufacture a different version of their product for each country. Instead, they put an IEC C14 inlet connector on their power supply and then ship the equipment with a few different power cables that have an IEC C13 connector on one end and the common power connector for each country on the other end. The only significant problem is that this connector has no locking mechanism, which makes it very easy for the power cable to be accidentally disconnected. Some power supplies come with a simple wire bracket that goes down over the IEC connecter and attaches just behind the strain relief to keep the connector from falling out.

Neutrik decided to take what they learned from designing the speakON connector and apply it to the problems of the IEC connector. The powerCON connector (Figure 1.40) looks very similar to the speakON. The biggest difference is that it has three pins. Some professional audio equipment such as self-powered loudspeakers and power amplifiers have powerCON connectors instead of IEC. The advantage is that you get a locking connector with no exposed contacts. You can also create powerCON patch cables that allow you to daisy chain a power connection between several devices such as a stack of self-powered loudspeakers. PowerCON connectors are color-coded. A blue connector is used for a power input connection to a device. A white connector is used for a power output connection from a device.

1.5.2.11 Dedicated Hardware Processors
While the software and hardware tools available for working with digital audio on a modern personal computer have become quite powerful and sophisticated, they are still susceptible to all the weaknesses of crashes, bugs, and other unreliable behavior. In a well-tuned system, these problems are rare enough that the systems are reliable to use in most professional and home recording studios. In those cases when problems happen during a session, it’s possible to reboot and get another take of the recording. In a live performance, however, the tolerance for failure is very low. You only get one chance to get it right and for many, the so-called “virtual sound systems” that can be operated on a personal computer are simply not reliable enough to be trusted on a multi-million dollar live event.
These productions tend to rely more on dedicated hardware solutions. In most cases these are still digital systems that essentially run on computers under the hood, but each device in the system is designed and optimized for only a single dedicated task – mixing the signals together, applying equalization, or playing a sound file, for example. When a computer-based digital audio workstation experiences a glitch, it’s usually due to some other task the computer is trying to perform at the same time, such as checking for a software update, running a virus scan, or refreshing a Facebook page. Dedicated hardware solutions like the one shown in Figure 1.41 have only one task, and they can perform that task very reliably.

Other hardware devices you might include with your system would be an analog or digital mixing console or dedicated hardware processing units such as equalizers, compressors, and reverberation processors. These dedicated processing units can be helpful in situations where you’re working with live sound reinforcement and can’t afford the latency that comes with completely software-based solutions. Some people simply prefer the sound of a particular analog processing unit and use it in place of more convenient software plug-ins. There may also be dedicated processing units that are calibrated in a way that’s difficult to emulate in a software plug-in. One example of this is the Dolby LM100 loudness meter shown in Figure 1.42. Many television stations require programming that complies with certain loudness levels corresponding to this specific hardware device. Though some attempts have been made to emulate the functions of this device in a software plug-in, many audio engineers working in broadcasting still use this dedicated hardware device to ensure their programming is in compliance with regulations.

1.5.2.12 Mixers
Mixers are an important part of any sound arsenal. Audio mixing is the process of combining multiple sounds, adjusting their levels and balance individually, dividing the sounds into one or more output channels, and either saving a permanent copy of the resulting sound or playing the sound live through loudspeakers. From this definition you can see that mixing can be done live, “on the fly,” as sound is being produced, or it can be done off-line, as a post-production step applied to recorded sound or music.
Mixers can analog or digital. Digital mixers can be hardware or software. Picture first a live sound engineer working at an analog mixer like the one shown in Figure 1.43. His job is to use the vertical sliders (called faders) to adjust the amplitudes of the input channels, possibly turn other knobs to apply EQ, and send the resulting audio to the chosen output channels. He may also add dynamics processing and special effects by means of an external processor inserted in the processing chain. A digital mixer is used in essentially the same way. In fact, the physical layout often looks remarkably similar as well. The controls of digital mixers tend to be modeled after analog mixers to make it easier for sound engineers to make the transition between devices. More detailed information on mixing consoles can be found in Chapter 8.

Music producers and sound designers for film and video do mixing as well. In the post-production phase, mixing is applied off-line to all of the recorded instrument, voice, or sound effects tracks captured during filming, foley, or tracking sessions. Some studios utilize large hardware mixing consoles for this mixing process as well, or the mixer may be part of a software program like Logic, ProTools, or Sonar. The graphical user interfaces of software mixers are often also made to look similar to hardware components. The purpose of the mixing process in post-production is, likewise, to make amplitude adjustments, and to add EQ, dynamics processing, and special effects to each track individually or in groups. Then the mixed-down sound is routed into a reduced number of channels for output, be it stereo, surround sound, or individual groups (often called “stems”) in case they need to be edited or mixed further down the road.
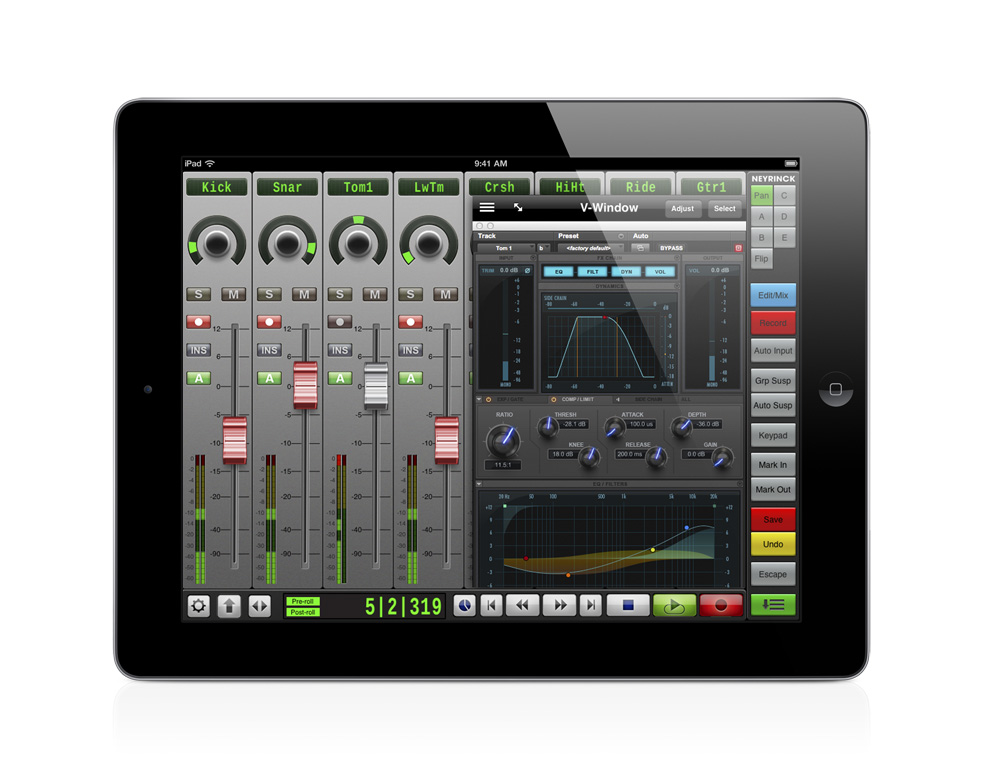
If you’re just starting out, you probably won’t need a massive mixing console in your setup, many of which can cost thousands if not tens or hundreds of thousands of dollars. If you’re doing live gigs, particularly where computer latency can be an issue, a small to mid-size mixing console may be necessary, such as a 16-channel board. In all other situations, current DAW software does a great job providing all the mixing power you’ll need for just about any size project. For those who prefer hands-on mixing over a mouse and keyboard, mixer-like control surfaces are readily available that communicate directly with your software DAW. These control surfaces work much like MIDI keyboards, not ever touching any actual audio signals, but instead remotely controlling your software’s parameters in a traditional mixer-like fashion, while your computer does all the real work. These days, you can even do your mix on a touch capable device like an iPad, communicating wirelessly with your DAW.

1.5.2.13 Loudspeakers
If you plan to work in sound for the theatre, then you’ll also need some knowledge of loudspeakers. While the monitors we described in Section 1.5.2.8 are appropriate for studio work where you are often sitting very close, these aren’t appropriate for distributing sound over long distances in a controlled way. For that you need loudspeakers which are specifically designed to maintain a controlled dispersion pattern and frequency response when radiating over long distances. These can include constant directivity horns and rugged cabinets with integrated rigging points for overhead suspension. Figure 1.46 shows an example of a popular loudspeaker for live performance.
These loudspeakers also require large power amplifiers. Most loudspeakers are specified with a sensitivity that defines how many dBSPL the loudspeaker can generate one meter away with only one watt of power. Using this specification along with the specification for the maximum power handling of the loudspeaker, you can figure out what kind of power amplifiers are needed to drive the loudspeakers, and how loud the loudspeakers can get. The process for aiming and calculating performance for loudspeakers is described in Chapters 4 and 8.

1.5.2.14 Analysis Hardware
When setting up sound systems for live sound, you need to make some acoustic measurements to help you configure the system for optimal use. There are dedicated hardware solutions available, but when you’re just starting out, you can use software on your personal computer to analyze the measurements if you have the appropriate hardware interfaces for your computer. The audio interface you have for recording is sufficient as long as it can provide phantom power to the microphone inputs. The only other piece of hardware you need is at least one good analysis microphone. This is typically an omnidirectional condenser microphone with a very flat frequency response. High-quality analysis microphones such as the Earthworks M30 (shown previously in Figure 1.20) come with a calibration sheet showing the exact frequency response and sensitivity for that microphone. Though the microphones are all manufactured together to the same specifications, there are still slight variations in each microphone even with the same model number. The calibration data can be very helpful when making measurements to account for any anomalies. In some cases, you can even get a digital calibration file for your microphone to load into your analysis software so it can make adjustments based on the imperfections in your microphone. When looking for an analysis microphone, make sure it’s an omnidirectional condenser microphone with a very small diaphragm like the one shown in Figure 1.47. The small diaphragm allows it to stay omnidirectional at high frequencies.

1.5.3 Software for Digital Audio and MIDI Processing
1.5.3.1 The Basics
Although the concepts in this book are general and basic, they are often illustrated in the context of specific application programs. The following sections include descriptions of the various programs that our examples and demonstrations use. The software shown can be used through two types of user interfaces: sample editors and multitrack editors.
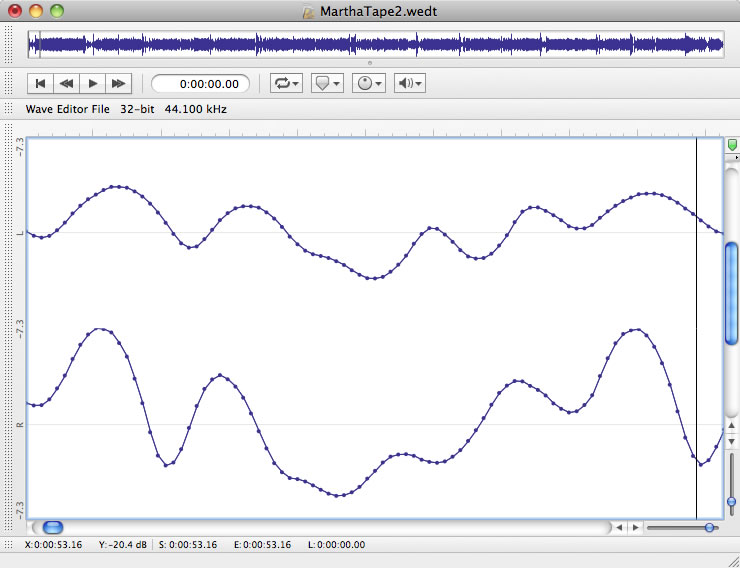
A sample editor, as the name implies, allows you to edit down to the level of individual samples, as shown in Figure 1.48. Sample editors are based on the concept of destructive editing where you are making changes directly to a single audio file – for example, normalizing an audio file, converting the sampling rate or bit depth, adding meta-data such as loop markers or root pitches, or performing any process that needs to directly and permanently alter the actual sample data in the audio file. Many sample editors also have batch processing capability, which allows you to perform a series of operations on several audio files at one time. For example, you could create a batch process in a sample editor that converts the sampling rate to 44.1 kHz, normalizes the amplitude values, and saves a copy of the file in AIFF format, applying these processes to an entire folder of 50 audio files. These kinds of operations would be impractical to accomplish with a multitrack editor.
Multitrack editors divide the interface into tracks. A track is an editable area on your audio arranging interface that corresponds to an individual input channel, which will eventually be mixed with others. One track might hold a singer’s voice while another holds a guitar accompaniment, for example. Tracks can be of different types. For example, one might be an audio track and one a MIDI track. Each track has its own settings and routing capability, allowing for flexible, individual control. Within the tracks, the audio is represented by visual blocks, called regions, which are associated with specific locations in memory where the audio data corresponding to that region is stored. In other words, the regions are like little “windows” onto your hard disk where the audio data resides. When you move, extend, or delete a region, you’re simply altering the reference “window” to the audio file. This type of interaction is known as non-destructive editing, where you can manipulate the behavior of the audio without physically altering the audio file itself, and is one of the most powerful aspects of multitrack editors. Multitrack editors are well-suited for music and post-production because they allow you to record sounds, voices, and multiple instruments separately, edit and manipulate them individually, layer them together, and eventually mix them down into a single file.
The software packages listed below handle digital audio, MIDI, or a combination of the two. Cakewalk, Logic, and Audition include both sample editors and multitrack editors, though are primarily suited for one or the other. The list of software is not comprehensive, and versions of software change all the time, so you should compare our list with similar software that is currently available. There are many software options out there ranging from freeware to commercial applications that cost thousands of dollars. You generally get what you pay for with these programs, but everyone has to work within the constraints of a reasonable budget. This book shows you the power of working with professional quality commercial software, but we also do our best to provide examples using software that is affordable for most students and educational institutions. Many of these software tools are available for academic licensing with reduced prices, so you may want to investigate that option as well. Keep in mind that some of these programs run on only one operating system, so be sure to buy something that runs on your preferred system.
1.5.3.2 Logic
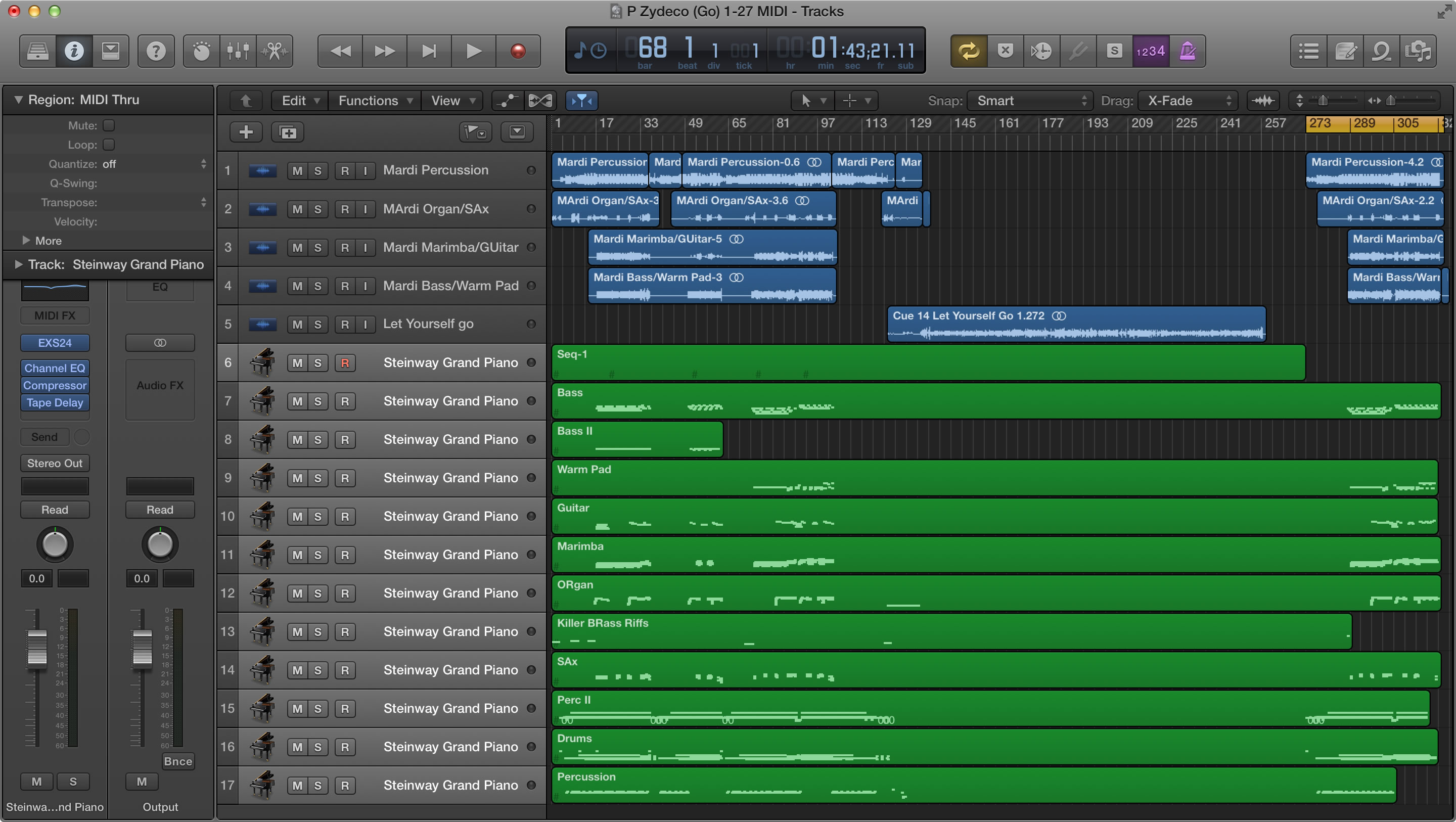
Logic is developed by Apple and runs on the Mac operating system. This is a very comprehensive and powerful program that includes audio recording, editing, multitrack mixing, score notation, and a MIDI sequencer – a software interface for recording and editing MIDI. There are two versions of Logic: Logic Studio and Logic Express. Logic Studio is actually a suite of software that includes Logic Pro, Wave Burner, Soundtrack Pro, and a large library of music loops and software instruments. Logic Express is the core Logic program without all the extras, but it still comes with an impressive collection of audio and software instrument content. There is a significant price difference between the two, so if you’re just starting out, try Logic Express. It’s very affordable, especially when you consider all the features that are included. Figure 1.49 is a screenshot from the Logic Pro workspace.
1.5.3.3 Cakewalk Sonar and Music Creator
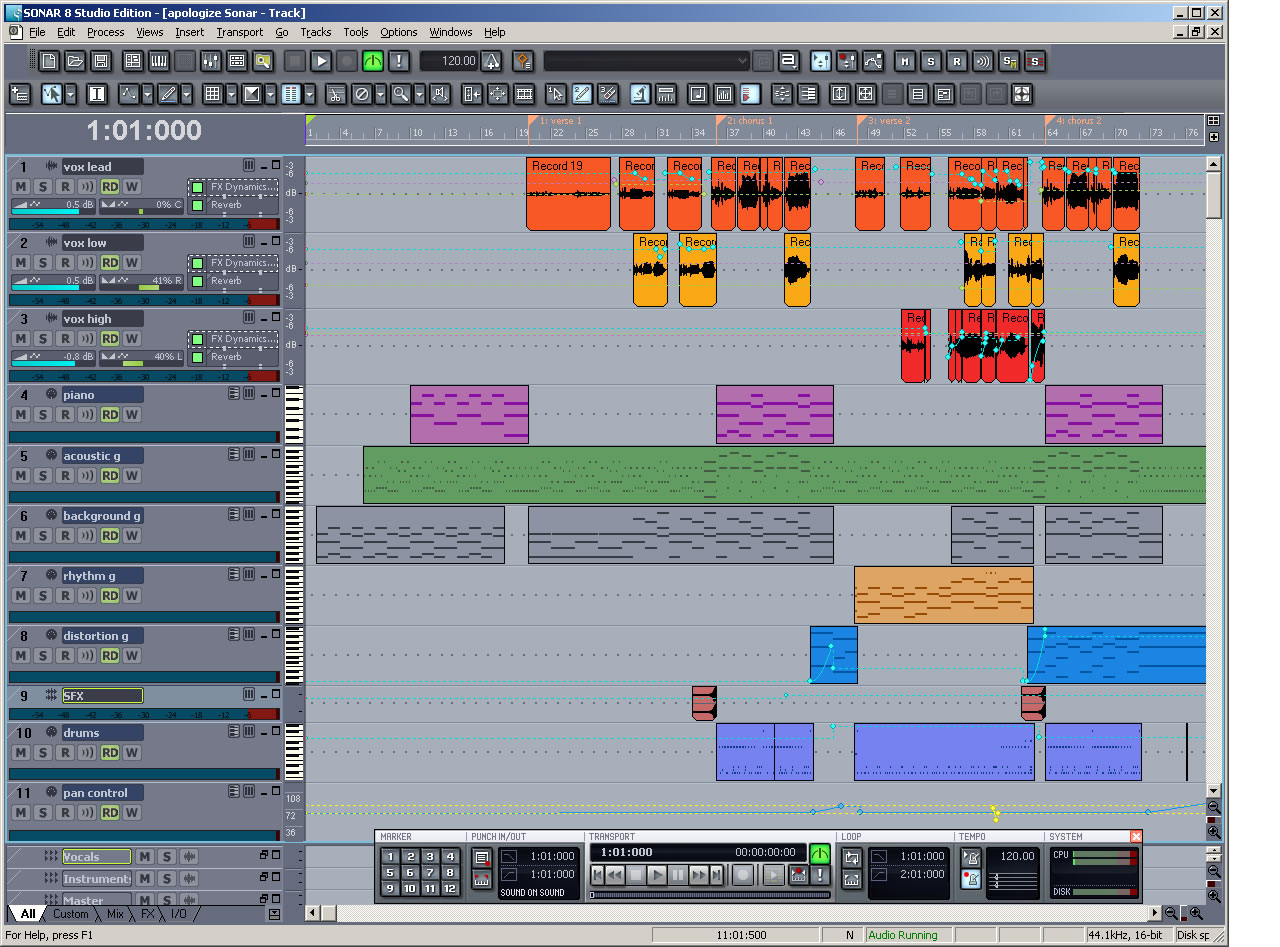
Cakewalk is a class of digital audio workstation software made by Roland. It features audio recording, editing, multitrack mixing, and MIDI sequencing. Cakewalk comes in different versions, all of which run only on the Windows operating system. Cakewalk Sonar is the high-end version with the highest price tag. Cakewalk Music Creator is a scaled-back version of the software at a significantly lower price. Most beginners find the features that come with Music Creator to be more than adequate. Figure 1.50 is a screenshot of the Cakewalk Sonar workspace.
1.5.3.4 Adobe Audition
Audition is DAW software made by Adobe. It was originally developed independently under the name “Cool Edit Pro” but was later purchased by Adobe and is now included in several of their software suites. The advantage to Audition is that you might already have it depending on which Adobe software suite you own. Audition runs on Windows or Mac operating systems and features audio recording, editing, and multitrack mixing. Traditionally, Audition hasn’t included MIDI sequencing support. The latest version has begun to implement more advanced MIDI sequencing and software instrument support, but Audition’s real power lies in its sample editing and audio manipulation tools.
1.5.3.5 Audacity
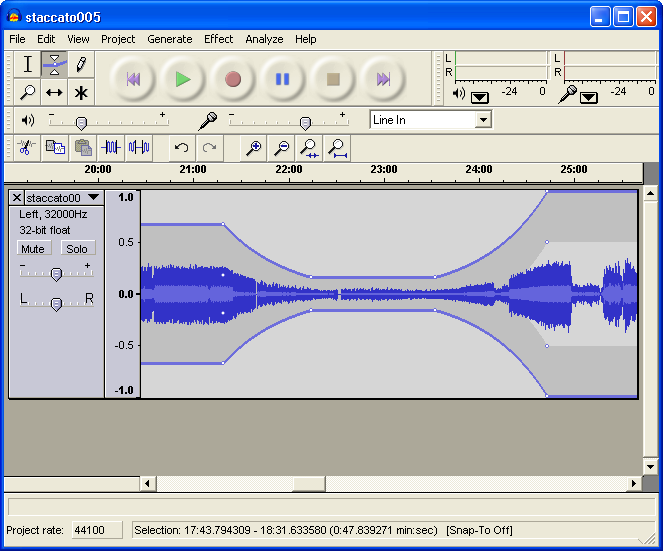
Audacity is a free, open-source audio editing program. It features audio recording, editing, and basic multitrack mixing. Audacity has no MIDI sequencing features. It’s not nearly as powerful as programs like Logic, Cakewalk, and Audition. If you really want to do serious work with sound, it’s worth the money to purchase a more advanced tool, but since it’s free, Audacity is worth taking a look at if you’re just starting out. Audacity runs on Windows, Mac, and Linux operating systems. Figure 1.51 is a screenshot of the Audacity workspace.
1.5.3.6 Reason
Reason, a software synthesis program made by Propellerhead, is designed to emulate electronic musical instruments. The number of instruments you can load in the program is limited only by the speed and capacity of your computer. Reason comes with an impressive instrument library and includes a simple MIDI sequencer. Its real power lies is its ability to be integrated with other programs like Logic and Cakewalk, giving those programs access to great sounding software instruments. Recent versions of Reason have added audio recording or editing features. Reason runs on both Mac and Windows operating systems. Figure 1.52 is a screenshot of the Reason workspace.
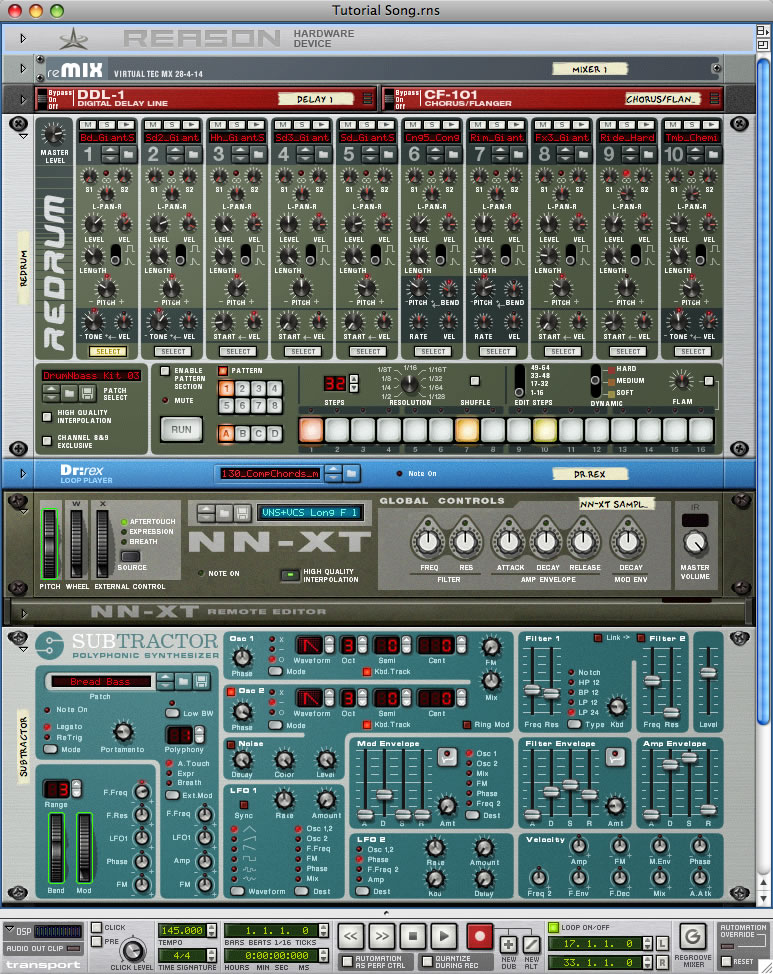
1.5.3.7 Software Plug-Ins
Multitrack editors include the ability to use real-time software plug-ins to process the audio on specific tracks. The term plug-in likely grew out of the days of analog mixing consoles when you would physically plug in an external processing device to the signal chain on a specific channel of an analog mixing console. Most analog mixing consoles have specific connections labeled “Insert” on each channel of the mixing console to allow these external processors to be connected. In the world of digital multitrack editing software, a plug-in refers to an extra processing program that gets inserted to the signal chain of a channel in the software multitrack editor. For example, you might want to change the frequency response of the audio signal on Track 1 of your project. To do this, you’d insert an equalizer plug-in on Track 1 that performs this kind of processing in real time as you play back the audio. Most DAW applications come with a variety of included plug-ins. Additionally, because plug-ins are treated as individual bits of software, it is possible to add third-party plug-ins to your computer that expand the processing options available for use in your projects, regardless of your specific DAW.
1.5.3.8 Music Composing and Notation Software
Musicians working with digital audio and MIDI often have need of software to help them compose and notate music. Examples of such software include Finale, Sibelius, and the free MuseScore. This software allows you to input notes via the mouse, keyboard, or external MIDI device. Some can also read and convert scanned sheet music or import various file types such as MIDI or MusicXML. Figure 1.53 shows a screen capture of Finale.
1.5.3.9 Working in the Linux Environment
If you want to work with audio in the Linux environment, you can do so at different levels of abstraction.
Ardour is free digital audio processing software that operates on the Linux and OS X operating systems. Ardour has extensive features for audio processing, but it doesn’t support MIDI sequencing. A screen capture of the Ardour environment is in Figure 1.54. Ardour allows you to work at the same high level of abstraction as Logic or Music Creator.
Ardour works in conjunction with Jack, an audio connection kit, and the GUI for Jack, qjackctl. A screenshot of the Jack interface is in Figure 1.55. On the Linux platform, Jack can talk to the sound card through ALSA, which stands for Advanced Linux Sound Architecture.
If you want to work at a lower level of abstraction, you can also use functions of one of the Linux basic sound libraries. Two libraries in use at the time of the writing of this chapter are ALSA and OSS, both illustrated in Chapter 2 examples.
1.5.4 Software for Live Performances
There are software packages that are used specifically in live sound. The first category is analysis software. This is software that you can run on your computer to analyze acoustic measurements taken through an analysis microphone connected to the audio interface. Current popular software solutions include Smaart from Rational Acoustics (Mac/Win), FuzzMeasure Pro (Mac), and EASERA (Win). Most of the impulse, frequency, and phase response figures you see in this book were created using FuzzMeasure Pro, shown in Figure 1.56. More information on these systems can be found in Chapter 2 and Chapter 8.
Another category of software used in live sound is sound playback software. Though it’s possible to play sound cues from your DAW, the interface is really designed for recording and editing. A dedicated playback software application is much more reliable and easy to use for sound playback on a live show. Popular playback solutions include QLab (Mac) from Figure 53 and SFX (Win) from Stage Research, shown in Figure 1.57. These systems allow you to create lists of cues that play and route the sound to multiple outputs on your audio interface. You can also automate the cues to fade in and out, layer sounds together, and even remotely trigger other systems such as lighting and projections.
6.1.1 The Beginnings of Sound Synthesis
Sound synthesis has an interesting history in both the analog and digital realms. Precursors to today’s sound synthesizers include a colorful variety of instruments and devices that generated sound electrically rather than mechanically. One of the earliest examples was Thaddeus Cahill’s Telharmonium (also called the Dynamophone), patented in 1897. The Telharmonium was a gigantic 200-ton contraption built of “dynamos” that were intended to broadcast musical frequencies over telephone lines. The dynamos, precursors of the tonewheels to be used later in the Hammond organ, were specially geared shafts and inductors that produced alternating currents of different audio frequencies controlled by velocity sensitive keyboards. Although the Telharmonium was mostly unworkable, generating too strong a signal for telephone lines, it opened people’s minds to the possibilities of electrically-generated sound.
The 1920s through the 1950s saw the development of various electrical instruments, most notably the Theremin, the Ondes Martenot, and the Hammond organ. The Theremin, patented in 1928, consisted of two sensors allowing the player to control frequency and amplitude with hand gestures. The Martenot, invented in the same year, was similar to the Theremin in that it used vacuum tubes and produced continuous frequencies, even those lying between conventional note pitches. It could be played in one of two ways: either by sliding a metal ring worn on the right-hand index finger in front of the keyboard or by depressing keys on the six-octave keyboard, making it easier to master than the Theremin. The Hammond organ was invented in 1938 as an electric alternative to wind-driven pipe organs. Like the Telharmonium, it used tonewheels, in this case producing harmonic combinations of frequencies that could be mixed by sliding drawbars mounted on two keyboards.
As sound synthesis evolved, researchers broke even farther from tradition, experimenting with new kinds of sound apart from music. Sound synthesis in this context was a process of recording, creating, and compiling sounds in novel ways. The musique concrète movement of the 1940s, for example, was described by founder Pierre Schaeffer as “no longer dependent upon preconceived sound abstractions, but now using fragments of sound existing concretely as sound objects (Schaeffer 1952).” “Sound objects” were to be found not in conventional music but directly in nature and the environment – train engines rumbling, cookware rattling, birds singing, etc. Although it relied mostly on naturally occurring sounds, musique concrète could be considered part of the electronic music movement in the way in which the sound montages were constructed, by means of microphones, tape recorders, varying tape speeds, mechanical reverberation effects, filters, and the cutting and resplicing of tape. In contrast, the contemporaneous elektronische musik movement sought to synthesize sound primarily from electronically produced signals. The movement was defined in a series of lectures given in Darmstadt, Germany, by Werner Meyer-Eppler and Robert Beyer and entitled “The World of Sound of Electronic Music.” Shortly thereafter, West German Radio opened a studio dedicated to research in electronic music, and the first elektronische music production, Musica su Due Dimensioni, appeared in 1952. This composition featured a live flute player, a taped portion manipulated by a technician, and artistic freedom for either one of them to manipulate the composition during the performance. Other innovative compositions followed, and the movement spread throughout Europe, the United States, and Japan.
There were two big problems in early sound synthesis systems. First, they required a great deal of space, consisting of a variety of microphones, signal generators, keyboards, tape recorders, amplifiers, filters, and mixers. Second, they were difficult to communicate with. Live performances might require instant reconnection of patch cables and a wide range of setting changes. “Composed” pieces entailed tedious recording, re-recording, cutting, and splicing of tape. These problems spurred the development of automated systems. The Electronic Music Synthesizer, developed at RCA in 1955, was a step in the direction of programmed music synthesis. Its second incarnation in 1959, the Mark II, used binary code punched into paper to represent pitch and timing changes. While it was still a large and complex system, it made advances in the way humans communicate with a synthesizer, overcoming the limitations of what can be controlled by hand in real-time.
Technological advances in the form of transistors and voltage controllers made it possible to reduce the size of synthesizers. Voltage controllers could be used to control the oscillation (i.e., frequency) and amplitude of a sound wave. Transistors replaced bulky vacuum tubes as a means of amplifying and switching electronic signals. Among the first to take advantage of the new technology in the building of analog synthesizers were Don Buchla and Robert Moog. The Buchla Music Box and the Moog Synthesizer, developed in the 1960s, both used voltage controllers and transistors. One main difference was that the Moog Synthesizer allowed standard keyboard input, while the Music Box used touch-sensitive metal pads housed in wooden boxes. Both, however, were analog devices, and as such, they were difficult to set up and operate. The much smaller MiniMoog, released in 1970, were more affordable and user-friendly, but the digital revolution in synthesizers was already under way.
When increasingly inexpensive microprocessors and integrated circuits became available in the 1970s, digital synthesizers began to appear. Where analog synthesizers were programmed by rearranging a tangle of patch cords, digital synthesizers could be adjusted with easy-to-use knobs, buttons, and dials. Synthesizers took the form of electronic keyboards like the one shown in Figure 6.1, with companies like Sequential Circuits, Electronics, Roland, Korg, Yamaha, and Kawai taking the lead in their development. They were certainly easier to play and program than their analog counterparts. A limitation to their use, however, was that the control surface was not standardized, and it was difficult to get multiple synthesizers to work together.

In parallel with the development of synthesizers, researchers were creating languages to describe the types of sounds and music they wished to synthesize. One of the earliest digital sound synthesis systems was developed by Max V. Mathews at Bell Labs. In its first version, created in 1957, Mathews’ MUSIC I program could synthesize sounds with just basic control over frequency. By 1968, Mathews had developed a fairly complete sound synthesis language in MUSIC V. Other sound and music languages that were developed around the same time or shortly thereafter include CSound (created by Barry Vercoe, MIT, in the 1980s), Structured Audio Orchestras Language (SAOL, part of MPEG 4 standard), Music 10 (created by John Chowning, Stanford, in 1966), cmusic (created by F. Richard Moore, University of California San Diego in the 1990s), and pcmusic (also created by F. Richard Moore).
In the early 1980s, led by Dave Smith from Sequential Circuits and Ikutaru Kakehashi from Roland, a group of the major synthesizer manufacturers decided that it was in their mutual interest to find a common language for their devices. Their collaboration resulted in the 1983 release of the MIDI 1.0 Detailed Specification. The original document defined only basic instructions, things like how to play notes and control volume. Later revisions added messages for greater control of synthesizers and branched out to messages controlling stage lighting. General MIDI (1991) attempted to standardize the association between program numbers and instruments synthesized. It also added new connection types (e.g., USB, FireWire, and wireless), and new platforms such as mobile phones and video games.
This short history lays the ground for the two main topics to be covered in this chapter: symbolic encoding of music and sound information – in particular, MIDI – and how this encoding is translated into sound by digital sound synthesis. We begin with a definition of MIDI and an explanation of how it differs from digital audio, after which we can take a closer look at how MIDI commands are interpreted via sound synthesis.
6.1.2 MIDI Components
MIDI (Musical Instrument Digital Interface) is a term that actually refers to a number of things:
- A symbolic language of event-based messages frequently used to represent music
- A standard interpretation of messages, including what instrument sounds and notes are intended upon playback (although the messages can be interpreted to mean other things, at the user’s discretion)
- A type of physical connection between one digital device and another
- Input and output ports that accommodate the MIDI connections, translating back and forth between digital data to electrical voltages according to the MIDI protocol
- A transmission protocol that specifies the order and type of data to be transferred from one digital device to another
Let’s look at all of these associations in the context of a simple real-world example. (Refer to the Preface for an overview of your DAW and MIDI setup.) A setup for recording and editing MIDI on a computer commonly has these five components:
- A means to input MIDI messages: a MIDI input device, such as a MIDI Keyboard or MIDI controller. This could be something that looks like a piano keyboard, only it doesn’t generate sound itself. Often MIDI keyboards have controller functions as well, such as knobs, faders, and buttons, as shown in Figure 1.5 in Chapter 1. It’s also possible to use your computer keyboard as an input device if you don’t have any other controller. The MIDI input program on your computer may give you an interface on the computer screen that looks like a piano keyboard, as shown in Figure 6.2.

[aside]We use the term synthesizer in a broad sense here, including samplers that produce sound from memory banks of recorded samples. We’ll explain the distinction between synthesizers and samplers in more detail in Section 7.1.6.[/aside]
- A means to transmit MIDI messages: a cable connecting your computer and the MIDI controller via MIDI ports or another data connection such as USB or FireWire.
- A means to receive, record, and process MIDI messages: a MIDI sequencer, which is software on your computer providing a user interface to capture, arrange, and manipulate the MIDI data. The interfaces of two commonly used software sequencers – Logic (Mac-based) and Cakewalk Sonar (Windows-based) are shown in Figures 1.29 and 1.30 of Chapter 1. The interface of Reason (Mac or Windows) is shown in Figure 6.3.
- A means to interpret MIDI messages and create sound: either a hardware or a software synthesizer. All three of the sequencers pictured in the aforementioned figures give you access to a variety of software synthesizers (soft synths, for short) and instrument plug-ins (soft synths often created by third-party vendors). If you don’t have a dedicated hardware of software synthesizer within your system, you may have to resort to the soft synth supplied by your operating system. For example, Figure 6.4 shows that the only choice of synthesizer for that system setup is the Microsoft GS Wavetable Synth. Some sound cards have hardware support for sound synthesis, so this may be another option.
- A means to do digital-to-analog conversion and listen to the sound: a sound card in the computer or external audio interface connected to a set of loudspeakers or headphones.
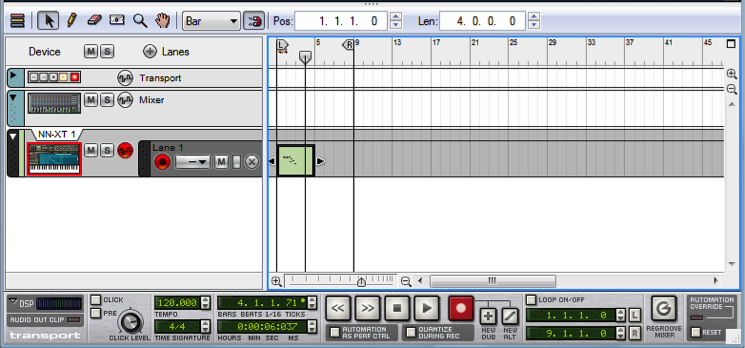
The basic setup for your audio/MIDI processing was described in Chapter 1 and is illustrated again here in Figure 6.5. This setup shows the computer handling the audio and MIDI processing. These functions are generally handled by audio/MIDI processing programs like Apple Logic, Cakewalk Sonar, Ableton Live, Steinberg Nuendo, or Digidesign Pro Tools, all of which provide a software interface for connecting the microphone, MIDI controller, sequencer, and output. All of these software systems handle both digital audio and MIDI processing, with samplers and synthesizers embedded. Details about particular configurations of hardware and software are given in Section 6.1.2.
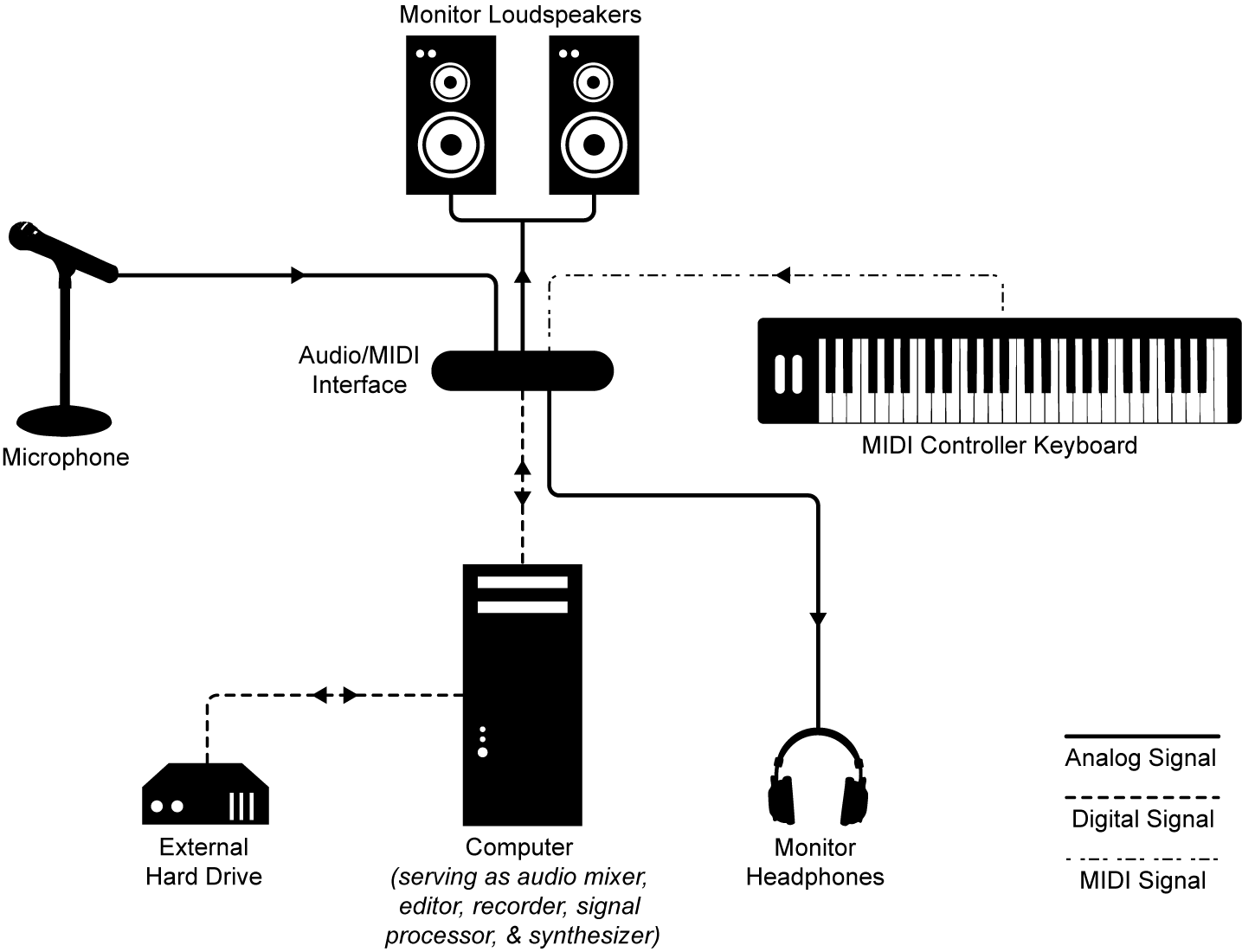
When you have your system properly connected and configured, you’re ready to go. Now you can “arm” the sequencer for recording, press a key on the controller, and record that note in the sequencer. Most likely pressing that key doesn’t even make a sound, since we haven’t yet told the sound where to go. Your controller may look like a piano, but it’s really just an input device sending a digital message to your computer in some agreed upon format. This is the purpose of the MIDI transmission protocol. In order for the two devices to communicate, the connection between them must be designed to transmit MIDI messages. For example, the cable could be USB at the computer end and have dual 5-pin DIN connections at the keyboard end, as shown in Figure 6.6. The message that is received by your MIDI sequencer is in a prescribed MIDI format. In the sequencer, you can save this and any subsequent messages into a file. You can also play the messages back and, depending on your settings, the notes upon playback can sound like any instrument you choose from a wide variety of choices. It is the synthesizer that turns the symbolic MIDI message into digital audio data and sends the data to the sound card to be played.

6.1.3 MIDI Data Compared to Digital Audio
Consider how MIDI data differs from digital audio as described in Chapter 5. You aren’t recording something through a microphone. MIDI keyboards don’t necessarily make a sound when you strike a key on a piano keyboard-like controller, and they don’t function as stand-alone instruments. There’s no sampling and quantization going on at all. Instead, the controller is engineered to know that when a certain key is played, a symbolic message should be sent detailing the performance information.
[aside]Many systems interpret a Note On message with velocity 0 as “note off” and use this as an alternative to the Note Off message.[/aside]
In the case of a key press, the MIDI message would convey the occurrence of a Note On, followed by the note pitch played (e.g., middle C) and the velocity with which it was struck. The MIDI message generated by this action is only three bytes long. It’s essentially just three numbers, as shown in Figure 6.7. The first byte is a value between 144 and 159. The second and third bytes are values between 0 and 127. The fact that the first value is between 144 and 159 is what makes it identifiable by the receiver as a Note On message, and the fact that it is a Note On message is what identifies the next two bytes as the specific note and velocity. A Note Off message is handled similarly, with the first byte identifying the message as Note Off and the second and third giving note and velocity information (which can be used to control note decay).
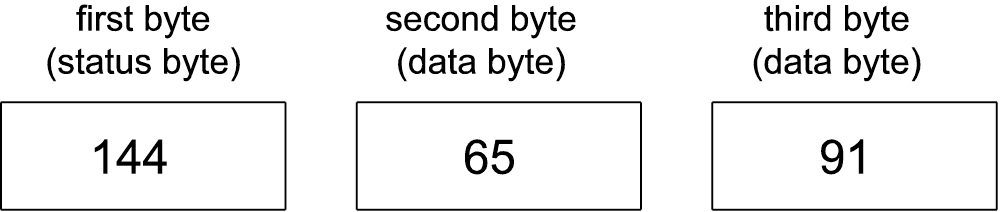
Let’s say that the key is pressed and a second later it is released. Thus, the playing of a note for one second requires six bytes. (We can set aside the issue of how the time between the notes is stored symbolically, since it’s handled at a lower level of abstraction.) How does this compare to the number of bytes required for digital audio? One second of 16-bit mono audio at a sampling rate of 44,100 Hz requires 44,100 samples/s * 2 bytes/sample = 88,200 bytes/s. Clearly, MIDI can provide a more concise encoding of sound than digital audio.
MIDI differs from digital audio in other significant ways as well. A digital audio recording of sound tries to capture the sound exactly as it occurs by sampling the sound pressure amplitude over time. A MIDI file, on the other hand, records only symbolic messages. These messages make no sound unless they are interpreted to do so by a synthesizer. When we speak of a MIDI “recording,” we mean it only in the sense that MIDI data has been captured and stored – not in the sense that sound has actually been recorded. While MIDI messages are most frequently interpreted and synthesized into musical sounds, they can be interpreted in other ways (as we’ll illustrate in Section 6.1.8.5.3). The messages mean only what the receiver interprets them to mean.
With this caveat in mind, we’ll continue from here under the assumption that you’re using MIDI primarily for music production since this is MIDI’s most common application. When you “record” MIDI music via a keyboard controller, you’re saving information about what notes to play, how hard or fast to play them, how to modulate them with pitch bend or with a sustain pedal, and what instrument the notes should sound like upon playback. If you already know how to read music and play the piano, you can enjoy the direct relationship between your input device – which is essentially a piano keyboard – and the way it saves your performance – the notes, the timing, even the way you strike the keys if you have a velocity-sensitive controller. Many MIDI sequencers have multiple ways of viewing your file, including a track view, a piano roll view, an event list view, and even a staff view – which shows the notes that you played in standard music notation. These are shown in Figure 6.8 through Figure 6.11.

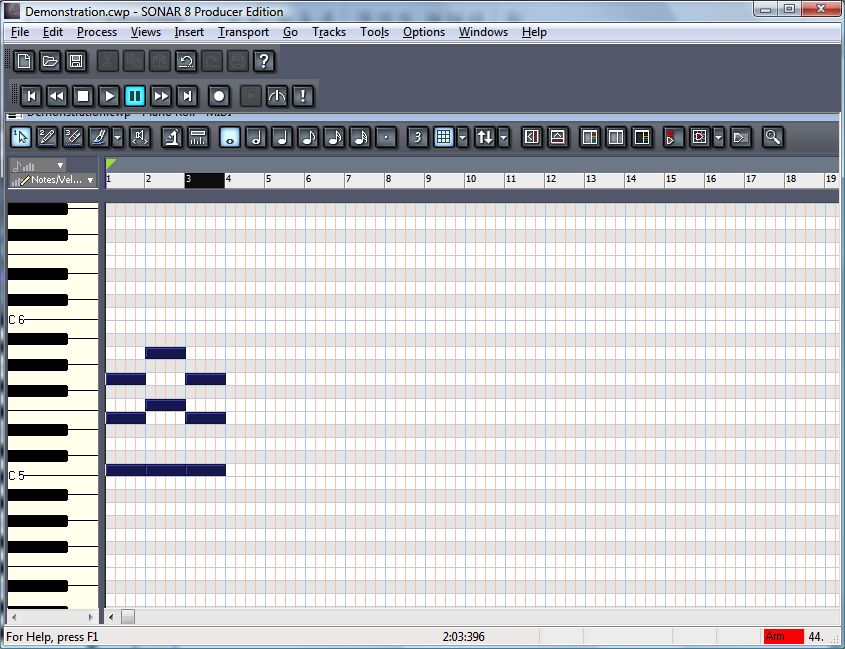

[aside]The word sample has different meanings in digital audio and MIDI. In MIDI, a sample is a small sound file representing a single instance of sound made by some instrument, like a note played on a flute.[/aside]
MIDI and digital audio are simply two different ways of recording and editing sound – with an actual real-time recording or with a symbolic notation. They serve different purposes. You can actually work with both digital audio and MIDI in the same context, if both are supported by the software. Let’s look more closely now at how this all happens.Another significant difference between digital audio and MIDI is the way in which you edit them. You can edit uncompressed digital audio down to the sample level, changing the values of individual samples if you like. You can requantize or resample the values, or process them with mathematical operations. But always they are values representing changing air pressure amplitude over time. With MIDI, you have no access to individual samples, because that’s not what MIDI files contain. Instead, MIDI files contain symbolic representations of notes, key signatures, durations of notes, tempo, instruments, and so forth, making it possible for you to edit these features with a simple menu selection or an editing tool. For example, if you play a piece of music and hit a few extra notes, you can get rid of them later with an eraser tool. If your timing is a little off, you can move notes over or shorten them with the selection tool in the piano roll view. If you change your mind about the instrument sound you want or the key you’d like the piece played in, you can change these with a click of the mouse. Because the sound has not actually been synthesized yet, it’s possible to edit its properties at this high level of abstraction.
6.1.6 Synthesizers vs. Samplers
As we’ve emphasized from the beginning, MIDI is a symbolic encoding of messages. These messages have a standard way of being interpreted, so you have some assurance that your MIDI file generates a similar performance no matter where it’s played in the sense that the instruments played are standardized. How “good” or “authentic” those instruments sound all comes down to the synthesizer and the way it creates sounds in response to the messages you’ve recorded.
We find it convenient to define synthesizer as any hardware or software system that generates sound electronically based on user input. Some sources distinguish between samplers and synthesizers, defining the latter as devices that use subtractive, additive AM, FM, or some other method of synthesis as opposed to having recourse to stored “banks” of samples. Our usage of the term is diagrammed in Figure 6.17.
A sampler is a hardware or software device that can store large numbers of sound clips for different notes played on different instruments. These clips are called samples (a different use from this term, to be distinguished from individual digital audio samples). A repertoire of samples stored in memory is called a sample bank. When you play a MIDI data stream via a sampler, these samples are pulled out of memory and played – a C on a piano, an F on a cello, or whatever is asked for in the MIDI messages. Because the sounds played are actual recordings of musical instruments, they sound realistic.
The NN-XT sampler from Reason is pictured in Figure 6.18. You can see that there are WAV files for piano notes, but there isn’t a WAV file for every single note on the keyboard. In a method called multisampling, one audio sample can be used to create the sound of a number of neighboring ones. The notes covered by a single audio sample constitute a zone. The sampler is able to use a single sample for multiple notes by pitch-shifting the sample up or down by an appropriate number of semitones. The pitch can’t be stretched too far, however, without eventually distorting the timbre and amplitude envelope of the note such that the note no longer sounds like the instrument and frequency it’s supposed to be. Higher and lower notes can be stretched more without our minding it, since our ears are less sensitive in these areas.
There can be more than one audio sample associated with a single note, also. For example, a single note can be represented by three samples where notes are played at three different velocities – high, medium, and low. The same note has a different timbre and amplitude envelope depending on the velocity with which it is played, so having more than one sample for a note results in more realistic sounds.
Samplers can also be used for sounds that aren’t necessarily recreations of traditional instruments. It’s possible to assign whatever sound file you want to the notes on the keyboard. You can create your own entirely new sound bank, or you can purchase additional sound libraries and install them (depending on the features offered by your sampler). Sample libraries come in a variety of formats. Some contain raw audio WAV or AIFF files which have to be mapped individually to keys. Others are in special sampler file formats that are compressed and automatically installable.

[aside]Even the term analog synthesizer can be deceiving. In some sources, an analog synthesizer is a device that uses analog circuits to generate sound electronically. But in other sources, an analog synthesizer is a digital device that emulates good old fashioned analog synthesis in an attempt to get some of the “warm” sounds that analog synthesis provides. The Subtractor Polyphonic Synthesizer from Reason is described as an analog synthesizer, although it processes sound digitally.[/aside]
A synthesizer, if you use this word in the strictest sense, doesn’t have a huge memory bank of samples. Instead, it creates sound more dynamically. It could do this by beginning with basic waveforms like sawtooth, triangle, or square waves and performing mathematical operations on them to alter their shapes. The user controls this process by knobs, dials, sliders, and other input controls on the control surface of the synthesizer – whether this is a hardware synthesizer or a soft synth. Under the hood, a synthesizer could be using a variety of mathematical methods, including additive, subtractive, FM, AM, or wavetable synthesis, or physical modeling. We’ll examine some of these methods in more detail in Section 6.3.1. This method of creating sounds may not result in making the exact sounds of a musical instrument. Musical instruments are complex structures, and it’s difficult to model their timbre and amplitude envelopes exactly. However, synthesizers can create novel sounds that we don’t often, if ever, encounter in nature or music, offering creative possibilities to innovative composers. The Subtractive Polyphonic Synthesizer from Reason is pictured in Figure 6.19.
[wpfilebase tag=file id=24 tpl=supplement /]
In reality, there’s a good deal of overlap between these two ways of handling sound synthesis. Many samplers allow you to manipulate the samples with methods and parameter settings similar to those in a synthesizer. And, similar to a sampler, a, synthesizer doesn’t necessarily start from nothing. It generally has basic patches (settings) that serve as a starting point, prescribing, for example, the initial waveform and how it should be shaped. That patch is loaded in, and the user can make changes from there. You can see that both devices pictured allow the user to manipulate the amplitude envelope (the ADSR settings), apply modulation, use low frequency oscillators (LFOs), and so forth. The possibilities seem endless with both types of sound synthesis devices.
[separator top=”0″ bottom=”1″ style=”none”]
6.1.7 Synthesis Methods
There are several different methods for synthesizing a sound. The most common method is called subtractive synthesis. Subtractive synthesizers, such as the one shown in Figure 6.19, use one or more oscillators to generate a sound with lots of harmonic content. Typically this is a sawtooth, triangle, or square wave. The idea here is that the sound you’re looking for is hiding somewhere in all those harmonics. All you need to do is subtract the harmonics you don’t want, and you’ll expose the properties of the sound you’re trying to synthesize. The actual subtraction is done using a filter. Further shaping of the sound is accomplished by modifying the filter parameters over time using envelopes or low frequency oscillators. If you can learn all the components of a subtractive synthesizer you’re well on your way to understanding the other synthesis methods because they all use similar components.
The opposite of subtractive synthesis is additive synthesis. This method involves building the sound you’re looking for using multiple sine waves. The theory here is that all sounds are made of individual sine waves that come together to make a complex tone. While you can theoretically create any sound you want using additive synthesis, this is a very cumbersome method of synthesis and is not commonly used.
Another common synthesis method is called frequency modulation (FM) synthesis. This method of synthesis works by using two oscillators with one oscillator modulating the signal from the other. These two oscillators are called the modulator and the carrier. Some really interesting sounds can be created with this synthesis method that would be difficult to achieve with subtractive synthesis. The Yamaha DX7 synthesizer is probably the most popular FM synthesizer and also holds the title of the first commercially available digital synthesizer. Figure 6.20 shows an example of an FM synthesizer from Logic Pro.
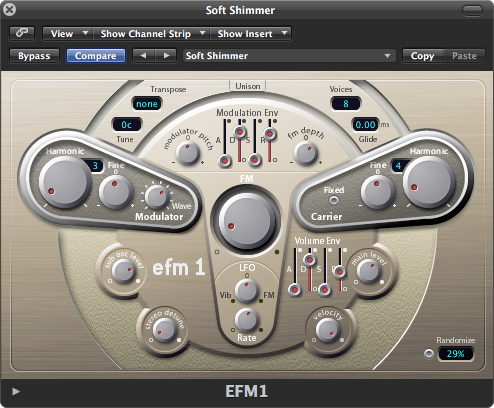
Wavetable synthesis is a synthesis method where several different single-cycle waveforms are strung together in what’s called a wavetable. When you play a note on the keyboard, you’re triggering a predetermined sequence of waves that transition smoothly between each other. This synthesis method is not very good at mimicking acoustic instruments, but it’s very good at creating artificial sounds that are constantly in motion.
Other synthesis methods include granular synthesis, physical modeling synthesis, and phase distortion synthesis. If you’re just starting out with synthesizers, begin with a simple subtractive synthesizer and then move on to a FM synthesizer. Once you’ve run out of sounds you can create using those two synthesis methods, you’ll be ready to start experimenting with some of these other synthesis methods.
6.1.8 Synthesizer Components
6.1.8.1 Presets
Now let’s take a closer look at synthesizers. In this section, we’re referring to synthesizers in the strict sense of the word – those that can be programmed to create sounds dynamically, as opposed to using recorded samples of real instruments. Synthesizer programming entails selecting an initial patch or waveform, filtering it, amplifying it, applying envelopes, applying low frequency oscillators to shape the amplitude or frequency changes, and so forth, as we’ll describe below. There are many different forms of sound synthesis, but they all use the same basic tools to generate the sounds. The difference is how the tools are used and connected together. In most cases, the software synthesizer comes with a large library of pre-built patches that configure the synthesizer to make various sounds. In your own work, you’ll probably use the presets as a starting point and modify the patches to your liking. Once you learn to master the tools, you can start building your own patches from scratch to create any sound you can imagine.
6.1.8.2 Sound Generator
The first object in the audio path of any synthesizer is the sound generator. Regardless of the synthesis method being used, you have to start by creating some sort of sound that is then shaped into the specific sound you’re looking for. In most cases, the sound generator is made up of one or more oscillators that create simple sounds like sine, sawtooth, triangle, and square waves. The sound generator might also consist of a noise generator that plays pink noise or white noise. You might also see a wavetable oscillator that can play a pre-recorded complex shape. If your synthesizer has multiple sound generators, there is also some sort of mixer that merges all the sounds together. Depending on the synthesis method being used, you may also have an option to decide how the sounds are combined (i.e. through addition, multiplication, modulation, etc.). Because synthesizers are most commonly used as musical instruments, there typically is a control on the oscillator that adjusts the frequency of the sound that is generated. This frequency can usually be changed remotely over time but typically, you choose some sort of starting point and any pitch changes are applied relative to the starting frequency. Figure 6.21 shows an example of a sound generator. In this case we have two oscillators and a noise generator. For the oscillators you can select the type of waveform to be generated. Instead of your being allowed to control the pitch of the oscillator in actual frequency values, the default frequency is defined by the note A (according to the manual). You get to choose which octave you want the A to start in and can further tune up or down from there in semitones and cents. An option included in a number of synthesizer components is keyboard tracking, which allows you to control how a parameter is set or a feature is applied depending on which key on the keyboard is pressed. The keyboard tracking (Kbd. Track) button in our example sound generator defines whether you want the oscillator’s frequency to change relative to the MIDI note number coming in from the MIDI controller. If this button is off, the synthesizer plays the same frequency regardless of the note played on the MIDI controller. The Phase, FM, Mix, and Mode controls determine the way these two oscillators interact with each other.

6.1.8.3 Filters
A filter is another object that is often found in the audio path. A filter is an object that modifies the amplitude of specified frequencies in the audio signal. There are several types of filters. In this section, we describe the basic features of filters most commonly found in synthesizers. For more detailed information on filters, see Chapter 7. Low-pass filters attempt to remove all frequencies above a certain point defined by the filter cutoff frequency. There is always a slope to the filter that defines the rate at which the frequencies are attenuated above the cutoff frequency. This is often called the filter order. A first order filter attenuates frequencies above the cutoff frequency at the rate of 6 dB per octave. If your cutoff frequency is 1 kHz, a first order filter attenuates 2 kHz by -6dB below the cutoff frequency, 4 kHz by -12 dB, 8 kHz by -18 dB, etc. A second order filter attenuates 12 dB per octave, a third order filter is 18 dB per octave, and a fourth order is 24 dB per octave. In some cases, the filter order is fixed, but more sophisticated filters allow you to choose the filter order that is the best fit for the sound you’re looking for. The cutoff frequency is typically the frequency that has been attenuated -6 dB from the level of the frequencies that are unaffected by the filter. The space between the cutoff frequency and frequencies that are not affected by the filter is called the filter typography. The typography can be shaped by the filter’s resonance control. Increasing the filter resonance creates a boost in the frequencies near the cutoff frequency. High-pass filters are the opposite of low-pass. Instead of removing all the frequencies above a certain point, a high-pass filter removes all the frequencies below a certain point. A high-pass filter has a cutoff frequency, filter order, and resonance control just like the low-pass filter. Bandpass filters are a combination of a high-pass and low-pass filter. A bandpass filter has a low cutoff frequency and a high cutoff frequency with filter order and resonance controls for each. In some cases, a bandpass filter is implemented with a fixed bandwidth or range of frequencies between the two cutoff frequencies. This simplifies the number of controls needed because you simply need to define a center frequency that positions the bandpass at the desired location in the frequency spectrum. Bandstop filters (also called notch filters) creates a boost or cut of a defined range of frequencies. In this case the filter frequency defines the center of the notch. You might also have a bandwidth control that adjusts the range of frequencies to be boosted or cut. Finally, you have a control that adjusts the amount of change applied to the center frequency. Figure 6.22 shows the filter controls in our example synthesizer. In this case we have two filters. Filter 1 has a frequency and resonance control and allows you to select the type of filter. The filter type selected in the example is a low-pass second order (12 dB per octave) filter. This filter also has a keyboard tracking knob where you can define the extent to which the filter cutoff frequency is changed relative to different frequencies. When you set the filter cutoff frequency using a specific key on the keyboard, the filter is affecting harmonic frequencies relative to the fundamental frequency of the key you pressed. If you play a key one octave higher, the new fundamental frequency generated by the oscillator is the same as the first harmonic of the key you were pressing when you set the filter. Consequently, the timbre of the sound changes as you move to higher and lower frequencies because the filter frequency is not changing when the oscillator frequency changes. The filter keyboard tracking allows you to change the cutoff frequency of the filter relative to the key being pressed on the keyboard. As you move to lower notes, the cutoff frequency also lowers. The knob allows you to decide how dramatically the cutoff frequency gets shifted relative to the note being pressed. The second filter is a fixed filter type (second order low-pass) with its own frequency and resonance controls and has no keyboard tracking option.

We’ll discuss the mathematics of filters in Chapter 7.
6.1.8.4 Signal Amplifier
The last object in the audio path of a synthesizer is a signal amplifier. The amplifier typically has a master volume control that sets the final output level for the sound. In the analog days this was a VCA (Voltage Controlled Amplifier) that allowed the amplitude of the synthesized sound to be controlled externally over time. This is still possible in the digital world, and it is common to have the amplifier controlled by several external modulators to help shape the amplitude of the sound as it is played. For example, you could control the amplifier in a way that lets the sound fade in slowly instead of cutting in quickly.

6.1.8.5 Modulation
Modulation is the process of changing a shape of a waveform over time. This is done by continuously changing one of the parameters that defines the waveform by multiplying it by some coefficient. All the major parameters that define a waveform can be modulated, including its frequency, amplitude, and phase. A graph of the coefficients by which the waveform is modified shows us the shape of the modulation over time. This graph is sometimes referred to as an envelope that is imposed over the chosen parameter, giving it a continuously changing shape. The graph might correspond to a continuous function, like a sine, triangle, square, or sawtooth. Alternative, the graph might represent a more complex function, like the ADSR envelope illustrated in Figure 6.25 illustrates a particular type of envelope, called ADSR. We’ll see look at mathematics of amplitude, phase, and frequency modulation in Section 3. For now, we’ll focus on LFOs and ADSR envelopes, commonly-used tools in synthesizers.
6.1.8.6 LFO
LFO stands for low frequency oscillator. An LFO is simply an oscillator just like the ones found in the sound generator section of the synthesizer. The difference here is that the LFO is not part of the audio path of the synthesizer. In other words, you can’t hear the frequency generated by the LFO. Even if the LFO was put into the audio path, it oscillates at frequencies well below the range of human hearing so it isn’t heard anyway. A LFO oscillates anywhere from 10 Hz down to a fraction of a Hertz. LFO’s are used like envelopes to modulate parameters of the synthesizer over time. Typically you can choose from several different waveforms. For example, you can use an LFO with a sinusoidal shape to change the pitch of the oscillator over time, creating a vibrato effect. As the wave moves up and down, the pitch of the oscillator follows. You can also use an LFO to control the sound amplitude over time to create a pulsing effect. Figure 6.24 shows the LFO controls on a synthesizer. The Waveform button toggles the LFO between one of six different waveforms. The Dest button toggles through a list of destination parameters for the LFO. Currently, the LFO is set to create a triangle wave and apply it to the pitch of Oscillators 1 and 2. The Rate knob defines the frequency of the LFO and the Amount knob defines the amplitude of the wave or the amount of modulation that is applied. A higher amount creates a more dramatic change to the destination parameter. When the Sync button is engaged, the LFO frequency is synchronized to the incoming tempo for your song based on a division defined by the Rate knob such as a quarter note or a half note.

6.1.8.7 Envelopes
[wpfilebase tag=file id=42 tpl=supplement /] The attack and decay values control how the sound begins. If the attack is set to a positive value, the sound fades in to the level defined by the master volume level over the period of time indicated in the attack. When the attack fade-in time completes, the amplitude moves to the sustain level. The decay value defines how quickly that move happens. If the decay is set to the lowest level, the sound jumps instantly to the sustain level once the attack completes. If the decay time has a positive value, the sound slowly fades down to the sustain level over the period of time defined by the decay after the attack completes.Most synthesizers have at least one envelope object. An envelope is an object that controls a synthesizer parameter over time. The most common application of an envelope is an amplitude envelope. An amplitude envelope gets applied to the signal amplifier for the synthesizer. Envelopes have four parameters: attack time, decay time, sustain level, and release time. The sustain level defines the amplitude of the sound while the note is held down on the keyboard. If the sustain level is at the maximum value, the sound is played at the amplitude defined by the master volume controller. Consequently, the sustain level is typically an attenuator that reduces rather than amplifies the level. If the other three envelope parameters are set to zero time, the sound is simply played at the amplitude defined by the sustain level relative to the master volume level. The release time defines the amount of time it takes for the sound level to drop to silence after the note is released. You might also call this a fade-out time. Figure 6.25 is a graph showing these parameters relative to amplitude and time. Figure 6.26 shows the amplitude envelope controls on a synthesizer. In this case, the envelope is bypassed because the sustain is set to the highest level and everything else is at the lowest value.
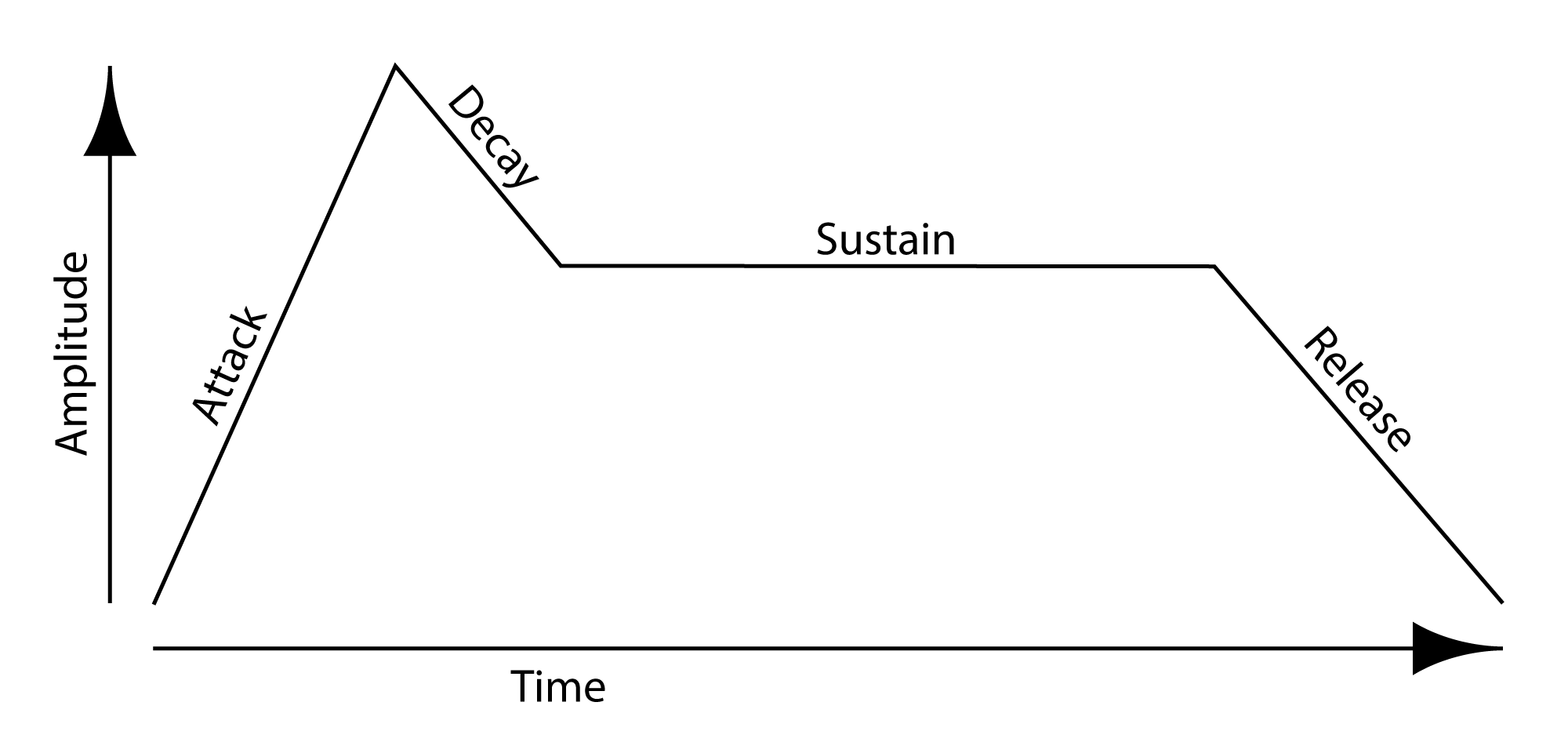

Envelopes can be used to control almost any synthesizer parameter over time. You might use an envelope to change the cutoff frequency of a filter or the pitch of the oscillator over time. Generally speaking, if you can change a parameter with a slider or a knob, you can modulate it over time with an envelope.
6.1.8.8 MIDI Modulation
You can also use incoming MIDI commands to modulate parameters on the synthesizer. Most synthesizers have a pre-defined set of MIDI commands it can respond to. More powerful synthesizers allow you to define any MIDI command and apply it to any synthesizer parameter. Using MIDI commands to modulate the synthesizer puts more power in the hands of the performer. Here’s an example of how MIDI modulation can work. Piano players are used to getting a different sound from the piano depending on how hard they press the key. To recreate this touch sensitivity, most MIDI keyboards change the velocity value of the Note On command depending on how hard the key is pressed. However, MIDI messages can be interpreted in whatever way the receiver chooses. Figure 6.27 shows how you might use velocity to modulate the sound in the synthesizer. In most cases, you would expect for the sound to get louder when the key is pressed harder. If you increase the Amp knob in the velocity section of the synthesizer, the signal amplifier level increases and decreases with the incoming velocity information. In some cases, you might also expect to hear more harmonics with the sound if the key is pressed harder. Increasing the value for the F.Env knob adjusts the depth at which the filter envelope is applied to the filter cutoff frequency. A higher velocity means that the filter envelope makes a more dramatic change to the filter cutoff frequency over time.

Some MIDI keyboards can send After Touch or Channel Pressure commands if the pressure at which the key is held down changes. You can use this pressure information to modulate a synthesizer parameter. For example, if you have a LFO applied to the pitch of the oscillator to create a vibrato effect, you can apply incoming key pressure data to adjust the LFO amount. This way the vibrato is only applied when the performer desires it by increasing the pressure at which he or she is holding down the keys. Figure 6.28 shows some controls on a synthesizer to apply After Touch and other incoming MIDI data to four different synthesizer parameters.

6.2.1 Linking Controllers, Sequencers, and Synthesizers
In this section, we’ll look at how MIDI is handled in practice.
First, let’s consider a very simple scenario where you’re generating electronic music in a live performance. In this situation, you need only a MIDI controller and a synthesizer. The controller collects the performance information from the musician and transmits that data to the synthesizer. The synthesizer in turn generates a sound based on the incoming control data. This all happens in real-time, the assumption being that there is no need to record the performance.
Now suppose you want also want to capture the musician’s performance. In this situation, you have two options. The first option involves setting up a microphone and making an audio recording of the sounds produced by the synthesizer during the performance. This option is fine assuming you don’t ever need to change the performance, and you have the resources to deal with the large file size of the digital audio recording.
The second option is simply to capture the MIDI performance data coming from the controller. The advantage here is that the MIDI control messages constitute much less data than the data that would be generated if a synthesizer were to transform the performance into digital audio. Another advantage to storing in MIDI format is that you can go back later and easily change the MIDI messages, which generally is a much easier process than digital audio processing. If the musician played a wrong note, all you need to do is change the data byte representing that note number, and when the stored MIDI control data is played back into the synthesizer, the synthesizer generates the correct sound. In contrast, there’s no easy way to change individual notes in a digital audio recording. Pitch correction plug-ins can be applied to digital audio, but they potentially distort your sound, and sometimes can’t fix the error at all.
So let’s say you go with option two. For this, you need a MIDI sequencer between the controller and the synthesizer. The sequencer captures the MIDI data from the controller and sends it on to the synthesizer. This MIDI data is stored in the computer. Later, the sequencer can recall the stored MIDI data and send it again to the synthesizer, thereby perfectly recreating the original performance.
The next questions to consider are these: Which parts of this setup are hardware and which are software? And how do these components communicate with each other? Four different configurations for linking controllers, sequencers, and synthesizers are diagrammed in Figure 6.28. We’ll describe each of these in turn.
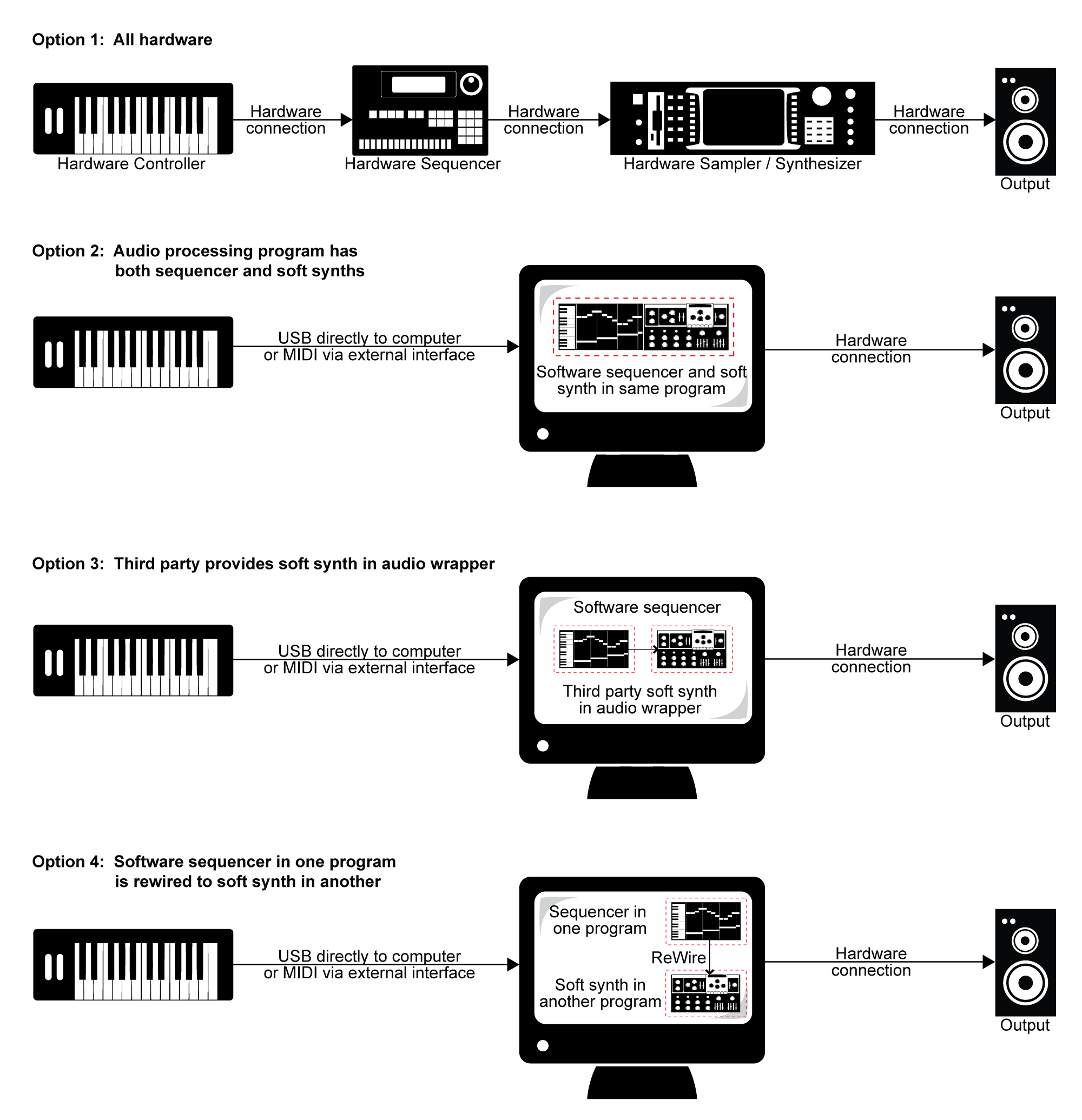
In the early days of MIDI, hardware synthesizers were the norm, and dedicated hardware sequencers also existed, like the one shown in Figure 6.29. Thus, an entire MIDI setup could be accomplished through hardware, as diagrammed in Option 1 of Figure 6.28.

Now that personal computers have ample memory and large external drives, software solutions are more common. A standard setup is to have a MIDI controller keyboard connected to your computer via USB or through a USB MIDI interface like the one shown in Figure 6.30. Software on the computer serves the role of sequencer and synthesizer. Sometimes one program can serve both roles, as diagrammed in Option 2 of Figure 6.28. This is the case, for example, with both Cakewalk Sonar and Apple Logic, which provide a sequencer and built-in soft synths. Sonar’s sample-based soft synth is called the TTS, shown in Figure 6.31. Because samplers and synthesizers are often made by third party companies and then incorporated into software sequencers, they can be referred to as plug-ins. Logic and Sonar have numerous plug-ins that are automatically installed – for example, the EXS24 sampler (Figure 6.32) and the EFM1 FM synthesizer (Figure 6.33).

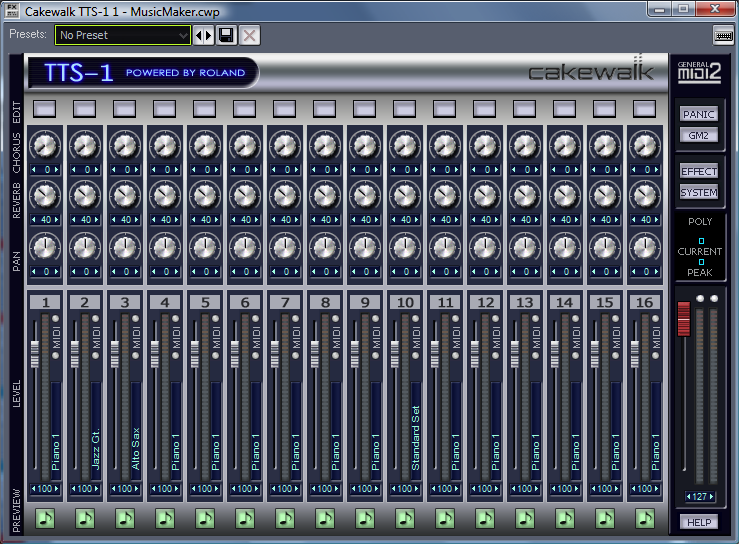

[aside]As you work with MIDI and digital audio, you’ll develop a large vocabulary of abbreviations and acronyms. In the area of plug-ins, the abbreviations relate to standardized formats that allow various software components to communicate with each other. VSTi stands for virtual studio technology instrument, created and licensed by Steinberg. This is one of the most widely used formats. Dxi is a plug-in format based on Microsoft Direct X, and is a Windows-based format. AU, standing for audio unit, is a Mac-based format. MAS refers to plug-ins that work with Digital Performer, an audio/MIDI processing system created by the MOTU company. RTAS (Real-Time AudioSuite) is the protocol developed by Digidesin for Pro Tools. You need to know which formats are compatible on which platforms. You can find the most recent information through the documentation of your software or through on-line sources.[/aside]
Some third-party vendor samplers and synthesizers are not automatically installed with a software sequencer, but they can be added by means of a software wrapper. The software wrapper makes it possible for the plug-in to run natively inside the sequencer software. This way you can use the sequencer’s native audio and MIDI engine and avoid the problem of having several programs running at once and having to save your work in multiple formats. Typically what happens is a developer creates a standalone soft synth like the one shown in Figure 6.34. He can then create an Audio Unit wrapper that allows his program to be inserted as an Audio Unit instrument, as shown for Logic in Figure 6.35. He can also create a VSTi wrapper for his synthesizer that allows the program to be inserted as a VSTi instrument in a program like Cakewalk, an MAS wrapper for MOTU Digital Performer, and so forth. A setup like this is shown in Option 3 of Figure 6.28.
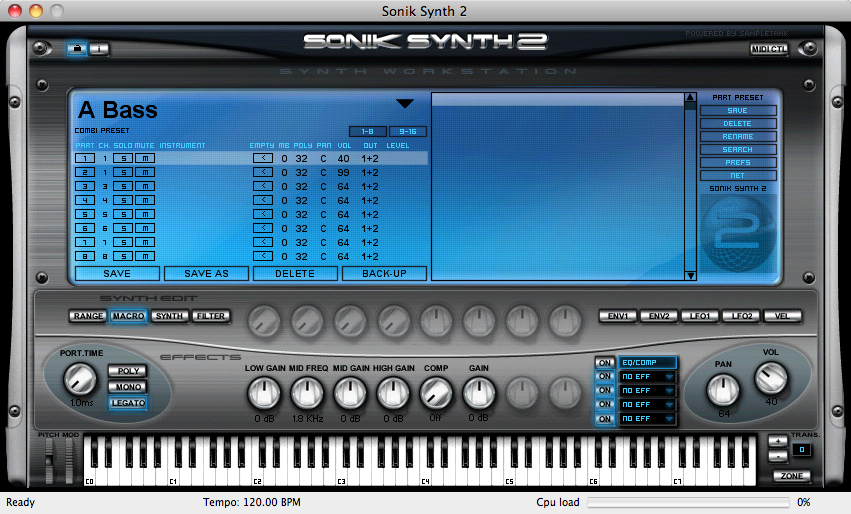
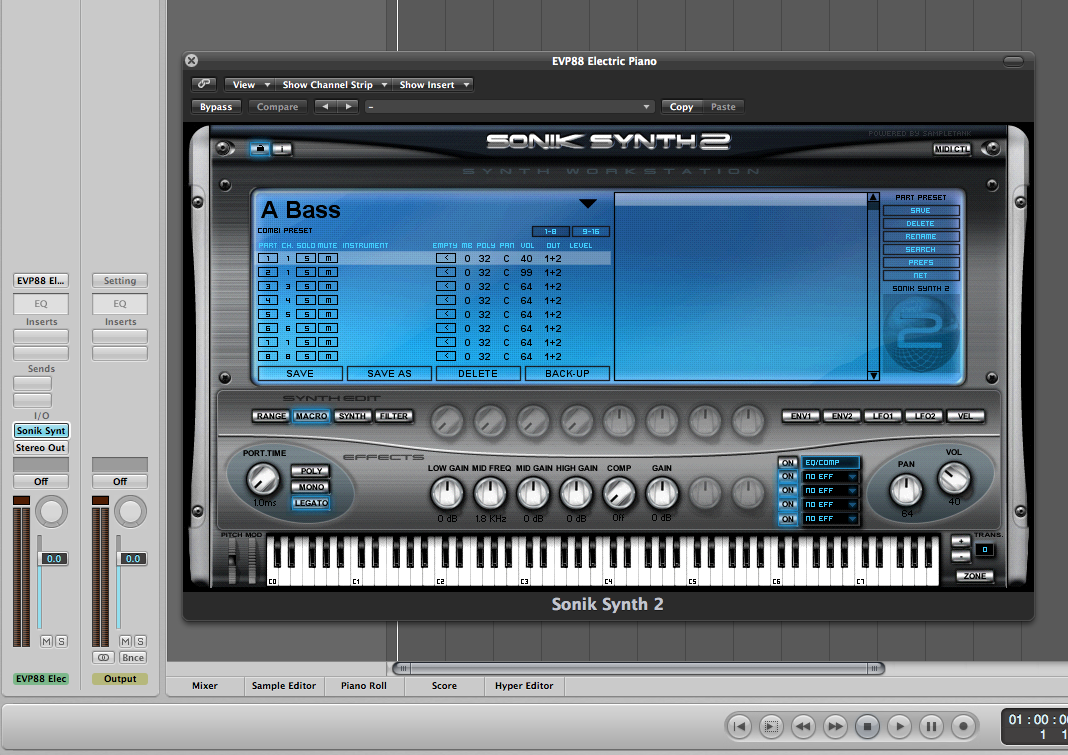
An alternative to built-in synths or installed plug-ins is to have more than one program running on your computer, each serving a different function to create the music. An example of such a configuration would be to use Sonar or Logic as your sequencer, and then use Reason to provide a wide array of samplers and synthesizers. This setup introduces a new question: How do the different software programs communicate with each other?
One strategy is to create little software objects that pretend to be MIDI or audio inputs and outputs on the computer. Instead of linking directly to input and output hardware on the computer, you use these software objects as virtual cables. That is, the output from the MIDI sequencer program goes to the input of the software object, and the output of the software object goes to the input of the MIDI synthesis program. The software object functions as a virtual wire between the sequencer and synthesizer. The audio signal output by the soft synth can be routed directly to a physical audio output on your hardware audio interface, to a separate audio recording program, or back into the sequencer program to be stored as sampled audio data. This configuration is diagrammed in Option 4 of Figure 6.28.
An example of this virtual wire strategy is the Rewire technology developed by Propellerhead and used with its sampler/synthesizer program, Reason. Figure 6.36 shows how a track in Sonar can be rewired to connect to a sampler in Reason. The track labeled “MIDI to Reason” has the MIDI controller as its input and Reason as its output. The NN-XT sampler in Reason translates the MIDI commands into digital audio and sends the audio back to the track labeled “Reason to audio.” This track sends the audio output to the sound card.
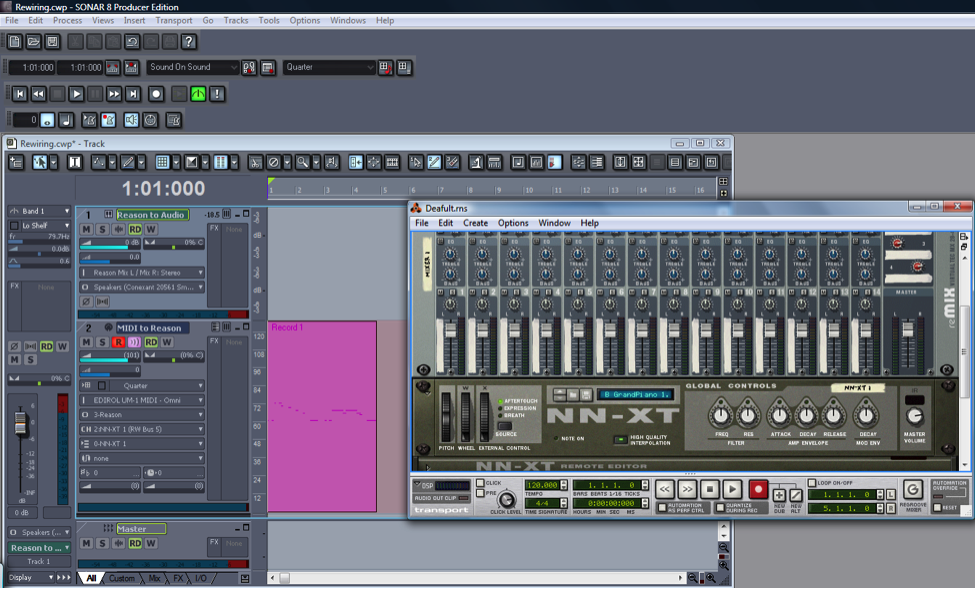
Other virtual wiring technologies are available. Soundflower is another program for Mac OS X developed by Cycling ’74 that creates virtual audio wires that can be routed between programs. CoreMIDI Virtual Ports are integrated into Apple’s CoreMIDI framework on Mac OS X. A similar technology called MIDI Yoke (developed by a third party) works in the Windows operating systems. Jack is an open source tool that runs on Windows, Mac OS X, and various UNIX platforms to create virtual MIDI and audio objects.
6.2.2 Creating Your Own Synthesizer Sounds
[wpfilebase tag=file id=25 tpl=supplement /]
[wpfilebase tag=file id=43 tpl=supplement /]
Section 6.1.8 covered the various components of a synthesizer. Now that you’ve read about the common objects and parameters available on a synthesizer you should have an idea of what can be done with one. So how do you know which knobs to turn and when? There’s not an easy answer to that question. The thing to remember is that there are no rules. Use your imagination and don’t be afraid to experiment. In time, you’ll develop an instinct for programming the sounds you can hear in your head. Even if you don’t feel like you can create a new sound from scratch, you can easily modify existing patches to your liking, learning to use the controls along the way. For example, if you load up a synthesizer patch and you think the notes cut off too quickly, just increase the release value on the amplitude envelope until it sounds right.
Most synthesizers use obscure values for the various controls, in the sense that it isn’t easy to relate numerical settings to real-world units or phenomena. Reason uses control values from 0 to 127. While this nicely relates to MIDI data values, it doesn’t tell you much about the actual parameter. For example, how long is an attack time of 87? The answer is, it doesn’t really matter. What matters is what it sounds like. Does an attack time of 87 sound too short or too long? While it’s useful to understand what the controller affects, don’t get too caught up in trying to figure out what exact value you’re dialing in when you adjust a certain parameter. Just listen to the sound that comes out of the synthesizer. If it sounds good, it doesn’t matter what number is hiding under the surface. Just remember to save the settings so you don’t lose them.
[separator top=”0″ bottom=”1″ style=”none”]