cpu'[wpfilebase tag=file id=155 tpl=supplement /]
When you work with sound either live or recorded, the sound is generally captured with the microphone very close to the source of the sound. With the microphone very close, and particularly in an acoustically treated studio with very little reflected sound, it is often desired or even necessary to artificially add a reverberation effect to create a more natural sound, or perhaps to give the sound a special effect. Usually a very dry initial recording is preferred, so that artificial reverberation can be applied more uniformly and with greater control.
There are several methods for adding reverberation. Before the days of digital processing this was accomplished using a reverberation chamber. A reverberation chamber is simply a highly reflective, isolated room with very low background noise. A loudspeaker is placed at one end of the room and a microphone is placed at the other end. The sound is played into the loudspeaker and captured back through the microphone with all the natural reverberation added by the room. This signal is then mixed back into the source signal, making it sound more reverberant. Reverberation chambers vary in size and construction, some larger than others, but even the smallest ones would be too large for a home, much less a portable studio.
Because of the impracticality of reverberation chambers, most artificial reverberation is added to audio signals using digital hardware processors or software plug-ins, commonly called reverb processors. Software digital reverb processors use software algorithms to add an effect that sounds like natural reverberation. These are essentially delay algorithms that create copies of the audio signal that get spread out over time and with varying amplitudes and frequency responses.
A sound that is fed into a reverb processor comes out of that processor with thousands of copies or virtual reflections. As described in Chapter 4, there are three components of a natural reverberant field. A digital reverberation algorithm attempts to mimic these three components.
The first component of the reverberant field is the direct sound. This is the sound that arrives at the listener directly from the sound source without reflecting from any surface. In audio terms, this is known as the dry or unprocessed sound. The dry sound is simply the original, unprocessed signal passed through the reverb processor. The opposite of the dry sound is the wet or processed sound. Most reverb processors include a wet/dry mix that allows you to balance the direct and reverberant sound. Removing all of the dry signal leaves you with a very ambient effect, as if the actual sound source was not in the room at all.
The second component of the reverberant field is the early reflections. Early reflections are sounds that arrive at the listener after reflecting from the first one or two surfaces. The number of early reflections and their spacing vary as a function of the size and shape of the room. The early reflections are the most important factor contributing to the perception of room size. In a larger room, the early reflections take longer to hit a wall and travel to the listener. In a reverberation processor, this parameter is controlled by a pre-delay variable. The longer the pre-delay, the longer time you have between the direct sound and the reflected sound, giving the effect of a larger room. In addition to pre-delay, controls are sometimes available for determining the number of early reflections, their spacing, and their amplitude. The spacing of the early reflections indicates the location of the listener in the room. Early reflections that are spaced tightly together give the effect of a listener who is closer to a side or corner of the room. The amplitude of the early reflections suggests the distance from the wall. On the other hand, low amplitude reflections indicate that the listener is far away from the walls of the room.
The third component of the reverberant field is the reverberant sound. The reverberant sound is made of up all the remaining reflections that have bounced around many surfaces before arriving at the listener. These reflections are so numerous and close together that they are perceived as a continuous sound. Each time the sound reflects off a surface, some of the energy is absorbed. Consequently, the reflected sound is quieter than the sound that arrives at the surface before being reflected. Eventually all the energy is absorbed by the surfaces and the reverberation ceases. Reverberation time is the length of time it takes for the reverberant sound to decay by 60 dB, effectively a level so quiet it ceases to be heard. This is sometimes referred to as the RT60, or also the decay time. A longer decay time indicates a more reflective room.
Because most surfaces absorb high frequencies more efficiently than low frequencies, the frequency response of natural reverberation is typically weighted toward the low frequencies. In reverberation processors, there is usually a parameter for reverberation dampening. This applies a high shelf filter to the reverberant sound that reduces the level of the high frequencies. This dampening variable can suggest to the listener the type of reflective material on the surfaces of the room.
Figure 7.7 shows a popular reverberation plug-in. The three sliders at the bottom right of the window control the balance between the direct, early reflection, and reverberant sound. The other controls adjust the setting for each of these three components of the reverberant field.
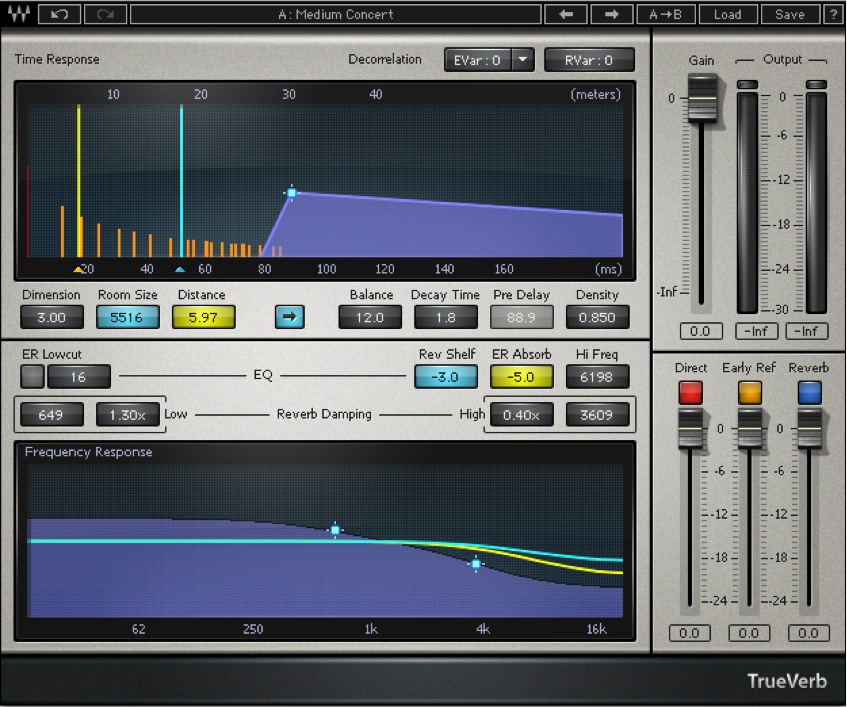
The reverb processor pictured in Figure 7.8 is based on a complex computation of delays and filters that achieve the effects requested by its control settings. Reverbs such as these are often referred to as algorithmic reverbs, after their unique mathematical designs.
[aside]Convolution is a mathematical process that operates in the time-domain – which means that the input to the operation consists of the amplitudes of the audio signal as they change over time. Convolution in the time-domain has the same effect as mathematical filtering in the frequency domain, where the input consists of the magnitudes of frequency components over the frequency range of human hearing. Filtering can be done in either the time domain or the frequency domain, as will be explained in Section 3.[/aside]
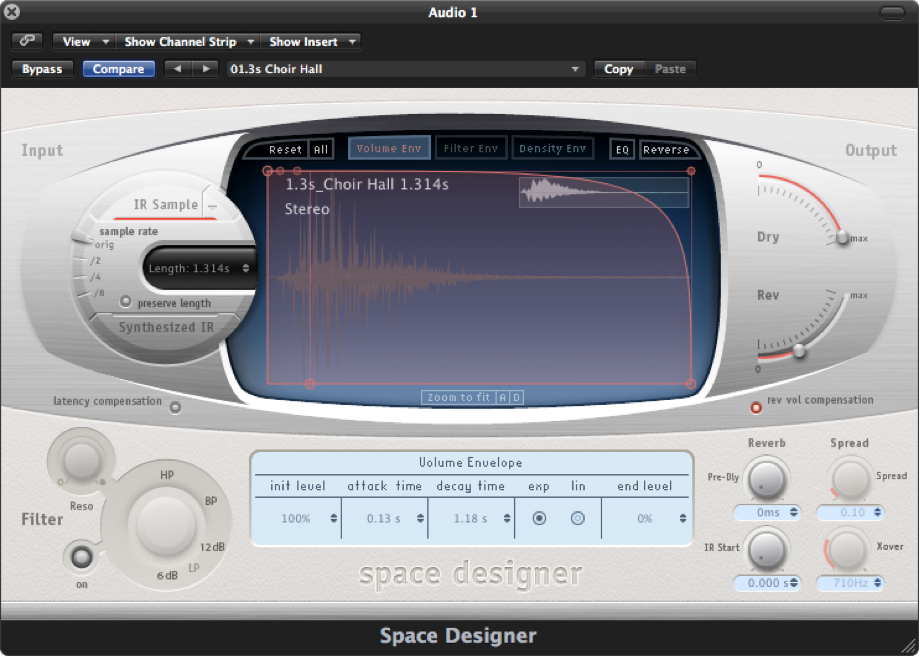
There is another type of reverb processor called a convolution reverb, which creates its effect using an entirely different process. A convolution reverb processor uses an impulse response (IR) captured from a real acoustic space, such as the one shown in Figure 7.8. An impulse response is essentially the recorded capture of a sudden burst of sound as it occurs in a particular acoustical space. If you were to listen to the IR, which in its raw form is simply an audio file, it would sound like a short “pop” with somewhat of a unique timbre and decay tail. The impulse response is applied to an audio signal by a process known as convolution, which is where this reverb effect gets its name. Applying convolution reverb as a filter is like passing the audio signal through a representation of the original room itself. This makes the audio sound as if it were propagating in the same acoustical space as the one in which the impulse response was originally captured, adding its reverberant characteristics.
With convolution reverb processors, you lose the extra control provided by the traditional pre-delay, early reflections, and RT60 parameters, but you often gain a much more natural reverberant effect. Convolution reverb processors are generally more CPU intensive than their more traditional counterparts, but with the speed of modern CPUs, this is not a big concern. Figure 7.8 shows an example of a convolution reverb plug-in.